
High-Resolution Mapping of H1 Linker Histone Variants in Embryonic Stem Cells
H1 linker histones facilitate higher-order chromatin folding and are essential for mammalian development. To achieve high-resolution mapping of H1 variants H1d and H1c in embryonic stem cells (ESCs), we have established a knock-in system and shown that the N-terminally tagged H1 proteins are functionally interchangeable to their endogenous counterparts in vivo. H1d and H1c are depleted from GC - and gene-rich regions and active promoters, inversely correlated with H3K4me3, but positively correlated with H3K9me3 and associated with characteristic sequence features. Surprisingly, both H1d and H1c are significantly enriched at major satellites, which display increased nucleosome spacing compared with bulk chromatin. While also depleted at active promoters and enriched at major satellites, overexpressed H10 displays differential binding patterns in specific repetitive sequences compared with H1d and H1c. Depletion of H1c, H1d, and H1e causes pericentric chromocenter clustering and de-repression of major satellites. These results integrate the localization of an understudied type of chromatin proteins, namely the H1 variants, into the epigenome map of mouse ESCs, and we identify significant changes at pericentric heterochromatin upon depletion of this epigenetic mark.
Published in the journal:
. PLoS Genet 9(4): e32767. doi:10.1371/journal.pgen.1003417
Category:
Research Article
doi:
https://doi.org/10.1371/journal.pgen.1003417
Summary
H1 linker histones facilitate higher-order chromatin folding and are essential for mammalian development. To achieve high-resolution mapping of H1 variants H1d and H1c in embryonic stem cells (ESCs), we have established a knock-in system and shown that the N-terminally tagged H1 proteins are functionally interchangeable to their endogenous counterparts in vivo. H1d and H1c are depleted from GC - and gene-rich regions and active promoters, inversely correlated with H3K4me3, but positively correlated with H3K9me3 and associated with characteristic sequence features. Surprisingly, both H1d and H1c are significantly enriched at major satellites, which display increased nucleosome spacing compared with bulk chromatin. While also depleted at active promoters and enriched at major satellites, overexpressed H10 displays differential binding patterns in specific repetitive sequences compared with H1d and H1c. Depletion of H1c, H1d, and H1e causes pericentric chromocenter clustering and de-repression of major satellites. These results integrate the localization of an understudied type of chromatin proteins, namely the H1 variants, into the epigenome map of mouse ESCs, and we identify significant changes at pericentric heterochromatin upon depletion of this epigenetic mark.
Introduction
In all eukaryotes, nuclear DNA is packaged into chromatin by its association with histones [1]. The nucleosome, the building block of chromatin, consists of an octamer of four core histones (H2A, H2B, H3 and H4) wrapped by 147 bp of DNA [2]. Linker histone H1 binds to DNA entering and exiting nucleosome core particles as well as the linker DNA between nucleosomes, facilitating folding of chromatin into higher order structure [1], [3]–[5].
The H1 histone family is the most divergent group among the highly conserved histone proteins. To date, 11 different H1 variants have been characterized in mammals, including somatic H1 variants (H1a to H1e), the replacement H1 (H10), germ cell specific H1s (H1t, H1T2, HILS1 and H1oo), as well as the recently characterized variant H1x [6]. Deletion of three major somatic H1 variants (H1c, H1d and H1e) together leads to a 50% reduction of the total H1 level and embryonic lethality at midgestation, demonstrating that H1 level is critical for mammalian development [7]. H1 variants are conserved from mouse to human, and differ in their biochemical properties and expression patterns during development and malignant transformation [8]–[11]. Although none of the H1 variants tested is essential for mouse development [12]–[15], they have been shown to regulate specific gene expression in various cell types [6], [16]–[18]. However, the mechanisms by which H1 variants modulate chromatin structure and gene expression remain under-explored. Mapping of the precise genomic localizations of different H1 variants in vivo is likely to provide significant insights, but has been challenging due to the lack of high quality antibodies that could accurately distinguish different H1 variants.
Pluripotent embryonic stem cells (ESCs) can differentiate into cells of all three germ layers, offering great potential in regenerative medicine. The epigenome is suggested to play a critical role in stem cell fate determination, and genome-wide mapping studies have revealed that ESCs have characteristic epigenetic landscapes that differ from differentiated cells [19], [20]. However, despite significant efforts to characterize the chromatin features of human and mouse ESCs, both by individual labs [19], [21]–[23] and by large consortia (ENCODE [24], Roadmap Epigenomics [25]), the landscapes of linker histone H1 variants have not been described on a genome-wide scale.
In this study, we have achieved high resolution mapping of H1d, H1c and H10 in ESCs by chromatin immunoprecipitation followed by massive parallel sequencing (ChIP-seq). H1d and H1c are among the most abundant linker histones in mouse ESCs, accounting respectively for 32.6% and 16.4% of total H1, whereas the differentiation associated H1, H10, accounts for 2% of H1 in undifferentiated ESCs [26], [27]. These three variants differ significantly in terms of their residence time on chromatin and their ability to promote chromatin condensation in vitro [28], [29]. They also display different expression patterns during mammalian development and in exponentially growing cells vs. quiescent cells [8], [10], [30]. Here, we have generated FLAG-tagged H1d knock-in ESCs, Myc-tagged H1c knock-in ESCs, as well as FLAG-tagged H10 overexpressing ESCs, designated as respective H1dFLAG, H1cMyc, and fH10 cells. We demonstrate that tagged H1 variants maintain the biochemical properties of the endogenous H1s in vivo and that FLAG-H1d can substitute for H1d during mouse development. High resolution mapping reveals that H1d and H1c occupancies are highly correlated, both enriched at AT-rich regions, but also possess different binding specificity. Both H1d and H1c largely co-localize with H3K9me3, but show an inverse correlation with GC% or H3K4me3. Importantly, we discover that H1d and H1c are highly enriched at major satellite elements, which display a longer nucleosome repeat length than bulk chromatin in ESCs. Finally, we show that H1 depletion leads to chromocenter clustering and increased expression of major satellites independent of multiple epigenetic marks at these regions.
Results
Generation of tagged H1 knock-in ESCs
Efforts to generate high resolution genome-wide maps of H1 variants were hampered by the lack of H1 variant specific antibodies of sufficient quality for ChIP-seq. Here, we established knock-in mouse ESC lines in which H1d or H1c variant was N-terminally tagged with an epitope (FLAG or Myc) for which highly specific antibodies exist. An H1dFLAG cell line was created by inserting the FLAG tag coding sequence at the endogenous H1d locus through homologous recombination (Figure 1A). H1c/H1e double knockout mice develop normally, yet H1c/H1d/H1e triple knockout (H1 TKO) mice are embryonic lethal [7]. Thus, ESCs with H1dFLAG allele in H1c+/−H1e+/− background could be used to produce H1c−/−H1dFLAG/FLAGH1e−/− mice to determine whether FLAG-tagged H1d (FLAG-H1d) functions equivalently to endogenous H1d by assessing if the tagged H1d can rescue the embryonic lethality of H1 TKO mutants. Toward this end, we generated both H1c+/−H1d+/FLAGH1e+/− (“H1dFLAG”) and H1c+/−H1dFLAG/−H1e+/− (“H1d-trans”) ESC lines by transfection of the FLAG-H1d targeting vector (Figure 1A) into the cis triply targeted H1c+/−H1d+/−H1e+/− ESCs established previously [7]. ESC clones with either cis or trans configuration of the H1dFLAG allele with the H1c and H1e KO allele were identified and verified by Southern blotting (Figure 1B). As expected, FLAG-H1d was located in the nuclei of the H1dFLAG cells (data not shown). Analysis of histone extracts of chromatin prepared from cis-targeted H1dFLAG cells by HPLC and immunoblotting indicated that FLAG-H1d was associated with chromatin and eluted in the same fraction as the endogenous H1d, suggesting that FLAG-H1d has the same hydrophobicity as the endogenous H1d (Figure 1C and 1D). The ratio of somatic H1 variants, H1 a–e, to nucleosome (H1/nuc) of H1dFLAG cells was nearly identical to that of H1c+/−H1d+/+H1e+/− (cehet) cells, indicating a similar expression level of FLAG-H1d as the endogenous H1d (Figure 1E). As expected, the protein level of differentiation associated H10 variant was minimal in undifferentiated ESCs. We injected cis-targeted H1dFLAG cells into mouse blastocysts and produced chimeric mice which gave germline transmission of the H1dFLAG allele. H1c+/−H1d+/FLAGH1e+/− mice were intercrossed to generate H1c−/−H1dFLAG/FLAGH1e−/− homozygous mice (designated as H1dFLAG/FLAG mice) (Figure S1Ai). These homozygotes were viable, fertile and developed normally as H1c/H1e double null (ceKO) mice, demonstrating that FLAG-H1d can substitute for the endogenous H1d to fully rescue the lethal phenotype of H1 TKO mutants. HPLC, mass spectrometry and immunoblotting demonstrated that H1dFLAG/FLAG mice had full replacement of H1d by FLAG-H1d (Figure S1Aii and S1Aiii) and that the H1/nuc ratio of spleen chromatin from H1dFLAG/FLAG mice was 0.7, comparable to that of ceKO mice (Figure S1Aiv). Taken together, these results demonstrate that FLAG-H1d maintains the expression level and properties of the endogenous H1d in vivo.

Using a similar knock-in strategy, we generated H1c+/MycH1d+/−H1e+/− ESCs (H1cMyc) by transfection of the H1cMyc targeting construct into the cis triply targeted H1c+/−H1d+/−H1e+/− ESCs and selected ESC clones that underwent homologous recombination at H1c locus (Figure S1Bi and S1Bii). Similar to FLAG-H1d, the N-terminally Myc tagged H1c (Myc-H1c) colocalized with Hoechst stained nuclear regions in H1cMyc cells (data not shown), and Myc-H1c was eluted in the same fraction as the endogenous H1c protein from HPLC analysis (Figure S1Biii and S1Biv). H1cMyc cells had a H1/nuc ratio of 0.38, comparable to the ratio of 0.36 in cehet cells (Figure 1E, Figure S1Biii), indicating that like FLAG-H1d, Myc-H1c has the same expression level and biochemical properties as the endogenous H1c.
H1d and H1c are under-represented at GC-, gene-rich regions and depleted at active promoters
To achieve high resolution mapping of H1d and H1c variants in mouse ESC genome, we performed ChIP-seq in cis-targeted H1dFLAG and H1cMyc ESCs using anti-FLAG and anti-Myc antibodies, respectively. In each ChIP-seq library, approximately 80–90% of reads were mappable to the mouse genome (mm9) using the Bowtie aligner [31] (Table S1). While sonicated chromatin input control libraries on average had 65% vs. 22% of reads mapped to unique positions and multiple positions respectively, the H1c ChIP-seq libraries had 44% vs. 45% mapped to unique vs. multiple positions, suggesting that a higher proportion of H1c resides on repetitive sequences. Similarly, an overrepresentation of multi-match sequence reads (39% of mapped reads) occurred in H1d ChIP-seq libraries. A survey of sequencing signal intensities indicated that H1d and H1c were generally depleted from gene rich regions with the deepest dips around transcription start sites of active genes (examples shown in Figure 2A and Figure S2A). ChIP-seq with the anti-FLAG antibody in control ESCs not containing FLAG-H1d generated minimal random background signals (data not shown), and examination of H1c (anti-Myc) signals showed no enrichment at c-Myc target genes, such as Oct4, Nanog and Sox2 [32] (Figure S2A), indicating no cross-reactivity for these antibodies. To compare H1 occupancy with other histone marks, we performed ChIP-seq of an active histone mark, H3K4me3, and two repressive histone marks, H3K9me3 and H3K27me3, in murine ESCs. Visual examination of the track files revealed that H1 dips often coincided with H3K9me3 dips or H3K4me3 peaks and that H1 displayed higher signals at gene poor regions with high AT% (low GC%) (Figure 2A). H3K27me3, enriched at Hox gene clusters (Figure S2B) as expected, did not show obvious pattern correlation with H1 (Figure 2A and Figure S2A). These observations suggest possible correlations of H1d and H1c with H3K9me3, H3K4me3, gene distribution and GC content in vivo.

We next investigated the relationship between H1 occupancy and gene expression levels at a 10 kb region centered around transcription start sites (TSSs) as well as a 10 kb region centered around transcription termination sites (TTSs) using GenPlay software [33]. Such metagene analysis revealed that H1 signals were always lower than chromatin input control within these regions (IP-IN<0) (Figure 2B), suggesting a general depletion of H1 at gene containing regions. Both H1d and H1c were especially depleted around the TSSs with dips much deeper at highly active genes than at silent genes (Figure 2B). Interestingly, except at TSSs and promoters, H1 signals remained largely constant throughout the gene encompassing regions and the signal intensity was higher at the silent genes than that at active genes, suggesting that H1 is underrepresented at surrounding regions of active genes as well (Figure 2B). Indeed, for genes highly depleted of H1 variants at promoters, the signal values of H1s, although gradually increased toward distal regions, remained diminished up to 200 kb from TSS (Figure S3), suggesting that H1s are depleted from broad domains at these regions in the genome. H3K4me3 is known to be peaked around TSS of active genes [34], [35], and metagene H3K4me3 curves displayed an opposite pattern to that of H1 (Figure 2B), further indicating that H1 is absent at active promoters. H3K9me3 exhibited a very similar distribution pattern to that of H1d and H1c, whereas H3K27me3 did not show similar profiles to that of H1 variants (Figure 2B). Metagene analysis of H1 and histone marks on genes finely partitioned by expression levels (each group with 20% of genes) over a 10 kb region (−5 kb to +5 kb of TSS) further corroborated their distinctive patterns at TSSs as a function of gene expression (Figure 2C).
To better define the correlation of H1 occupancy with histone marks around TSSs and promoters, metagene analysis of H1 signals was performed for genes partitioned into 5 groups according to their levels of H3K9me3, H3K4me3, or H3K27me3, which displayed characteristic profiles around TSS (Figure 2D, 2E, 2F and Figure S2C). H1 signals displayed positive and negative correlations with respective H3K9me3 and H3K4me3 signals, having the deepest dip for promoters and TSSs with the lowest H3K9me3 levels (Figure 2D) or highest H3K4me3 signals (Figure 2E). On the other hand, H1 signals showed no correlation with H3K27me3 levels and no difference among the 5 groups of genes partitioned according to H3K27me3 levels (Figure 2F). Interestingly, H1 was also depleted at the promoters of genes bound by H3K4me3 and H3K27me3 bivalent marks [21] but not at H3K4me3-free promoters, regardless of the presence or absence of H3K27me3 (Figure 2G).
Although most H1d and H1c signals appeared universally distributed, we identified regions enriched for H1 binding using SICER [36] and GenPlay software. Identified H1d and H1c enriched regions often formed broad domains (examples shown in Figure S4A). Annotation of H1d - and H1c - rich regions using CEAS [37], a software designed to characterize both sharp and broad ChIP-seq enrichment, indicated that, similar to H3K9me3, both H1d and H1c “peaks” were over-represented in distal intergenic regions and under-represented at promoters and 5′UTR, which were highly enriched with H3K4me3 peaks as reported previously (Figure S4B and [34]).
Correlation of H1 with histone marks and features of H1d and H1c enriched regions
We next performed genome-wide correlation analysis to determine if the similarity and/or contrast of H1 variants with GC% and histone marks at TSSs also extend to a genome-wide scale. Indeed, the distribution of H1d and H1c were highly correlated throughout the genome (R = 0.7866) (Figure 3A), and both variants were negatively correlated with GC% (R = −0.4182 and −0.4140 for respective H1d and H1c), indicating that H1d and H1c were enriched or depleted at similar regions. Both H1d and H1c were correlated negatively with H3K4me3 (R = −0.2640 and −0.3317 respectively), but positively with H3K9me3 (R = 0.5732, 0.5790) (Figure 3B), suggesting their enrichment at heterochromatin. On the other hand, these two variants showed no obvious correlation with H3K27me3 (R = −0.08 for both variants) (Figure 3B). Correlation analysis of sequencing signals on enriched or depleted regions gave similar coefficients as the respective genome-wide coefficients (data not shown). It is interesting to note that the coefficients of H1 vs. H3K4me3 on sex chromosomes were dramatically different from those of autosomes (Figure S5A). This result echoes the previous finding that sex-chromosome genes are overrepresented among genes with altered expression levels by triple H1 deletion in ESCs [26], suggesting that H1 may play a role in regulating higher order chromatin structures of sex chromosomes.

To gain a comprehensive view of the DNA features of H1d - and H1c - rich regions, we selected the regions highly enriched for H1 variants and histone marks, and performed cross-comparison of genome attributes using the statistical analysis software EpiGRAPH [38]. Such analysis (Figure 3C and Figure S5B) revealed that: a) H1d/H1c common peaks (regions highly enriched for both H1d and H1c) appeared similar to H3K9me3 peaks in genome attributes, except for satellite DNA which was relatively overrepresented in H1 peak regions; b) H1d/H1c common peaks were enriched at AT-rich sequences, satellite DNA, and chromosome G-bands but were absent from GC-rich regions, and genes or exons when compared with H3K4me3 or H3K27me3 peaks; c) comparison of H1d/H1c common peaks with H1d/H1c unique peaks (regions highly enriched for H1d or H1c but not both) showed similar features as the comparison of H1d/H1c common peaks with H3K4me3 or H3K27me3 peaks; d) comparison of H1d vs. H1c specific peaks indicated that H1d unique peaks were relatively enriched at GC-rich sequences and LINEs, whereas H1c unique peaks were more enriched at AT-rich sequences, Giemsa positive regions and satellite DNA; e) the overrepresentation analyses between H1d (or H1c) unique peak regions and histone mark peak regions exhibited similar features as comparisons using H1 common peaks. These results define common and unique features for H1d and H1c enriched regions.
High occupancy of H1d and H1c at major satellite sequences
The EpiGRAPH overrepresentation analysis indicated that peak regions of H1d and H1c were enriched for satellite repeats. Indeed, examination of the top ranked H1 peak regions with especially high binding signals revealed that these regions overlap perfectly with major satellite sequences (examples shown in Figure 4A). This finding and the above observation of overrepresentation of multi-match sequence reads in H1 ChIP-seq libraries prompted us to perform a thorough mapping study of sequence reads to a database of repetitive sequences. We aligned sequence reads of H1d, H1c, H3K9me3, H3K27me3 and H3K4me3 ChIP-seq libraries to Repbase Update, a comprehensive database of repetitive elements from diverse eukaryotic organisms [39]–[41]. We found that both H1d and H1c were significantly enriched at repetitive sequences, with H1d and H1c ChIP-seq libraries having on average percent mapped repeats respective 2.3-, and 2.8-fold of that of chromatin input-seq libraries (Figure 4B). H3K9me3, H3K27me3 and H3K4me3 ChIP-seq libraries had an average respective percent mapped repeats 1.4-, 0.7-, and 0.9 - fold compared with input controls (Figure 4B), suggesting an overrepresentation of H3K9me3, yet not as dramatic as H1d and H1c, at repetitive sequences.

Importantly, we found that the increased proportion of total reads of H1 libraries mapped to repetitive sequences was predominantly caused by overrepresentation on the major satellite sequences on which the levels of H1d and H1c occupancy were enriched on average 4.0 - and 5.6-fold compared with the chromatin input control (Figure 4B). This level of H1 enrichment appeared to be specific to major satellites because we did not observe H1d and H1c enrichment among other abundant repeats, except for a moderate increase of H1d and H1c occupancy at minor satellites. qChIP-PCR results confirmed the preferential binding of these two H1 variants to major satellites (Figure S6). Sequencing results showed that H1d and H1c levels on most of other less abundant classes of repetitive elements, such as L1, IAP LTR retrotransposons, SINE, non-LTR retrotransposons, and DNA transposons, were similar or lower compared with the input control (Figure 4B and Figure S7). H3K4me3 was highly enriched at 5′end of a subset of LINE L1 sequence (Figure S7), consistent with the abundant expression of L1 detected in multiple cell types [42]–[44], whereas H3K9me3 was enriched at major satellite repeats and LTR transposons, such as IAP particles, with similar levels as previously reported [34], [45] (Figure 4B and Figure S7). Enrichment of H1 variants at major satellites was also confirmed by calculating the normalized “IP-IN” signals at major satellite regions in mouse genome mm9 assembly (July 2007) annotated by RepeatMasker (http://repeatmasker.org) (Figure S8). Analysis of ChIP-seq libraries of FLAG-H1d in H1d-trans ESCs, which had similar levels of FLAG-H1d and total H1/nuc ratio as the cis H1dFLAG ESCs, also showed similar level of enrichment at major satellites as H1dFLAG ESCs (Figure S9).
Increased nucleosome repeat length at major satellite sequences in ESCs
The level of H1 has been shown to be a determinant of nucleosome repeat length (NRL) with a higher level of H1 correlating with a longer NRL [46], [47]. To validate the enrichment of H1 variants at major satellites and to investigate its impact on the local chromatin structure at these regions, we measured the NRL of bulk chromatin and that of the pericentromeric (major satellites) and centromeric (minor satellites) regions with a time-course micrococcal nuclease (MNase) digestion assay. Southern blotting images revealed that chromatin at major satellites was more resistant to MNase digestion than bulk chromatin and minor satellites (Figure 5A). Consistent with previous studies [26], the bulk chromatin of mouse ESCs displayed a NRL of ∼187 bp (Figure 5B). However, the NRL at major satellites had a value of 200 bp, which was ∼13 bp and ∼8 bp longer than the NRLs of respective bulk chromatin and minor satellites in ESCs (Figure 5B). These results suggest that the enrichment of H1d and H1c at major satellite repeats may contribute to the increase of NRL in the pericentromeric region compared with bulk ESC chromatin. Analysis of H1c/H1d/H1e triple knockout (H1 TKO) ESCs established previously, which have an H1/nuc ratio of 0.25 in bulk chromatin compared with that of 0.46 in WT ESCs [26], indicated that H1 depletion caused a proportional decrease of NRLs in bulk chromatin, major satellites and minor satellites (Figure S10). Consistently, qChIP analysis using a pan-H1 antibody showed total H1 levels were reduced at major and minor satellites by H1 depletion (Figure S10D).

H1 depletion leads to chromocenter clustering and de-repression of major satellite repeats independent of multiple epigenetic marks
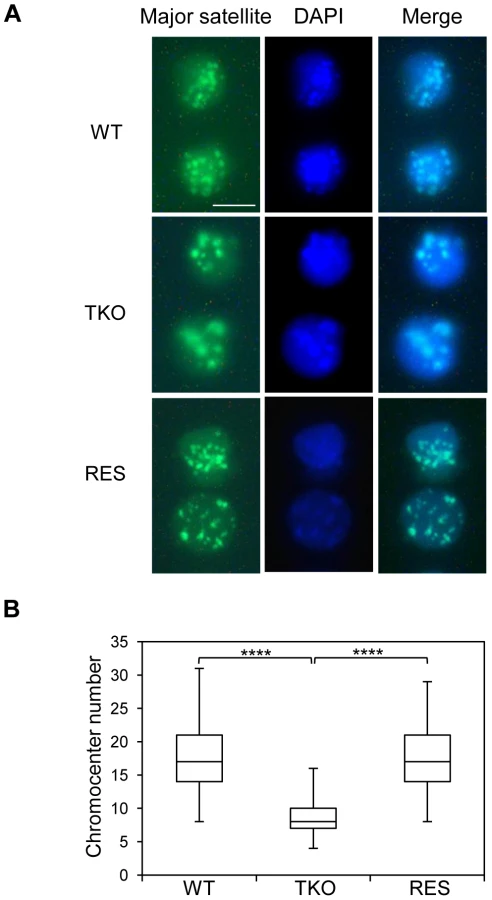
Major satellite repeats at pericentric heterochromatin from different chromosomes tend to cluster together and form the chromocenter, a nuclear compartment that plays an important role in structural maintenance of the chromosomes [48], [49]. Several chromatin proteins such as MeCP2, MBD2, DNMT3a, DNMT3b, and UHRF1 have been shown to contribute to chromocenter clustering [50]–[52], however, the role of H1 in chromocenter formation has not been studied to date. Since both H1d and H1c are markedly enriched at major satellites, we set out to determine the effects of H1 depletion on chromocenter clustering in WT and H1 TKO ESCs by fluorescence in situ hybridization (FISH) using a major satellite specific probe. The chromocenter numbers in H1 TKO ESCs (median = 8, n = 160) were significantly lower than WT cells (median = 17, n = 206) (Figure 6), and the size of chromocenters in H1 TKO ESCs on average was bigger than that in WT ESCs (Figure S11), demonstrating a previously unnoticed defect in the pericentromeric chromatin structure caused by H1 depletion. Analysis of “rescue” (RES) cells established previously [53] showed that overexpressing H1d in H1 TKO cells effectively restored the size and the numbers of chromocenters to the levels comparable to WT cells (Figure 6 and Figure S11). Similarly, H1dFLAG and H1cMyc cells displayed normal chromocenter clustering as WT ESCs (Figure S15). These results indicate that the increased chromocenter clustering is likely due to the dramatic decrease of total H1 levels in H1 TKO ESCs.
Pervasive transcription of repetitive sequences contributes to genome regulation, and aberrant regulation of the expression of satellite sequences interferes with heterochromatin assembly and chromosome segregation [49], [54]–[56]. To further examine the effects of H1 depletion on major satellites, we analyzed several repetitive sequences for expression and epigenetic marks in WT and H1 TKO ESCs. Quantitative reverse transcription-PCR (qRT-PCR) analysis showed that the expression levels of major satellites were 3.5-fold higher in H1 TKO ESCs than in WT ESCs, whereas the expression levels of minor satellites and LINE L1 were not significantly changed (Figure 7A). Such de-repression of major satellites by H1 depletion was dramatically curbed in RES cells (Figure 7A) as well as in H1dFLAG and H1cMyc ESCs (Figure S16), indicating that the levels of H1s have a direct impact on transcriptional regulation of major satellites. Notably, the levels of multiple epigenetic marks, such as repressive marks H3K9me3, H3K27me3, and H4K20me3, the active mark H3K4me3, as well as DNA methylation all remained unchanged at the analyzed repeats in H1 TKO ESCs compared with WT ESCs (Figure 7B and 7C). The lack of significant changes in the histone marks and DNA methylation at these repetitive sequences suggests that the increase in expression levels at major satellites may be due to an effect of local chromatin decondensation caused by H1 depletion in H1 TKO ESCs.

We note that the level of H10, the replacement H1 variant, was increased significantly in TKO ESCs compared with that in undifferentiated WT ESCs where H10 was minimal [26], [53]. To examine if the increased chromocenter clustering and expression of major satellites in H1 TKO ESCs could be attributed to an increase in H10 levels, we generated “fH10” cells by over-expressing FLAG-H10 in WT ESCs, and selected cell lines that expressed FLAG-H10 at a similar level to that of H10 in H1 TKO ESCs (Figure S12 and [26]). As expected, FLAG-H10 was eluted in the same fraction as endogenous H10. ChIP-seq of H10 in fH10 cells with an anti-FLAG antibody indicated that, despite its different biochemical properties and unique expression patterns [6], [8], [57], H10 shared similar distribution features to that of H1d and H1c in ESCs, including depletion at active promoters and enrichment at major satellites (Figure S3, Figure S8, Figure S13, and Figure S14). Similar to H1d and H1c, H10 also displayed overall positive correlation with H3K9me3 and inverse correlations with GC% and H3K4me3, although the level of correlation was to a lesser extent (data not shown). Furthermore, H10 enriched regions were significantly under-represented in gene regions but over-represented in distal intergenic regions with 80.1% of H10 peaks located in these regions (data not shown). Beside major satellites, H10 also appeared to be enriched at minor satellites and, to a lesser extent, at LINE L1 elements as determined by ChIP-seq and ChIP-PCR (Figure S14B and S14C), suggesting differential binding preferences of H10 compared with H1d and H1c.
Analysis of fH10 ESCs by FISH and qRT-PCR indicated that the chromocenter numbers were not reduced compared with WT ESCs (Figure S15) and that expression of major satellites remained at low levels (Figure S16), excluding the possibility of H10 upregulation being responsible for chromocenter clustering and upregulation of major satellite transcription in H1 TKO ESCs.
Collectively, these results demonstrate increased chromocenter clustering and major satellite transcription by H1 depletion, and suggest important roles of the dominant H1 variants in ESCs in maintaining pericentric chromatin properties.
Discussion
H1 Linker histones are abundant chromatin binding proteins that facilitate the formation of higher order chromatin structures [1], [2]. The existence of multiple mammalian H1 variants which are differentially regulated during development presumably offers additional levels of modulation on chromatin structure and function. Despite many efforts, the in vivo localization and function of individual H1 variants in genome organization remain elusive. Chromatin plays critical roles in stem cell fate determination and reprogramming, and the epigenome of ESCs has been intensively studied. However, the genome-wide maps of one group of the major chromatin proteins, H1 variants, have not been established. Here, we have filled both gaps by generating high resolution maps of three H1 variants in mouse ESCs, identified unique H1 binding features, and discovered an unusual enrichment and function of H1 variants at major satellites.
We have established a knock-in system to stringently test the functions of the tagged H1s and to facilitate the generation of high resolution maps of H1 variants in ESCs by ChIP-seq. Our results demonstrate that, when tagged at the N-terminus, the short FLAG and Myc tags, with respective 8 and 13 amino acids, do not alter the biochemical and cellular properties of H1 proteins in vivo. The strategy of homologous recombination ensures that the expression of tagged H1 variants is comparable to that of their endogenous counterparts. FLAG-H1d fully rescues the lethal phenotype of H1d deletion on H1c/H1e double knockout genetic background, further demonstrating the functional equivalence of the tagged H1 and the respective endogenous H1 variant in vivo. Although Myc-H1c was not tested in mice, it is anticipated to mimic the endogenous H1c based on all the other assays performed. These data provide a technical demonstration on how highly similar protein variants can be analyzed differentially and on a genomic scale using in vivo validated knock-in mice.
On the H1 genome-wide maps we have generated here, H1d and H1c are highly correlated and display similar binding patterns in the ESC genome. Both variants are enriched at AT-rich regions, gene deserts and major satellites, but are depleted at GC-rich, gene-rich regions and especially at active promoters. Thus, despite their differences in compacting DNA in vitro and the expression patterns during development [8], [10], [28], H1d and H1c are quite similar in overall distribution in the genome, which we surmise contributes to the redundancy among the major somatic H1s as suggested from previous studies of single or double H1 variants knockout mice [7], [14]. Nevertheless, analyses of the regions that are uniquely enriched for H1d or H1c reveal some differences in sequence features (Figure 3C and Figure S5B). H1c has a higher enrichment at major satellites than H1d but is relatively depleted from LINE sequences (Figure 3C and Figure 4B). In addition, H1c enriched regions have a higher proportion in gene bodies and proximal regions compared with H1d peak distribution (Figure S4B). These differences may account for an additional level of modulation and fine-tuning of genome function by the presence of multiple H1 variants in mammals.
H10, the H1 variant associated with differentiation, has unique expression pattern and biochemical properties. It is highly basic, expressed in differentiated cell types, and more similar to histone H5 in avian red blood cells than any other somatic variants [53], [57]. However, overexpressed H10 (in fH10 cells) shares the distinctive features of H1d and H1c in ESCs in genome-wide occupancy. It is worth noting, though, that endogenous H10 proteins are present at very low levels in undifferentiated WT ESCs and the genome-wide localization of H10 in ESCs may differ significantly from its binding patterns in differentiated cells. It would be interesting to systematically determine the genome-wide maps of histone variants in different cell types, particularly in light of a recent study reporting a distribution pattern change of H1.5 in cellular differentiation [58]. The cell lines and mouse models generated in this study will greatly facilitate these future studies.
The prevalent H1 variants binding with local troughs at active promoters we observed here in the mouse ESC genome is reminiscent of the previous results when ChIP-chip and a pan-H1 antibody were used to map H1 on a portion of the human genome in MCF-7 cells [59] or when DamID method was used to map H1 in Drosophila cells [60]. The depletion of H1 at TSSs of active genes observed in three systems suggests that this feature is common to all H1s and evolutionarily conserved. However, our study differs from the two previous studies and offers more opportunities for high resolution and in-depth analysis because the knock-in system generated in this study allows for robust and highly specific mapping of H1 variants and deep-sequencing covers the entire genome including the repetitive genome. Furthermore, we have found that the depletion of H1 at active genes is not restricted to regions around the TSS, but also expands to the entire gene encompassing domain (Figure 2B and 2C). Such phenomena suggests that a wide-spread change in higher order chromatin structure may be associated with gene expression and that gene-rich domains may adopt an overall decondensed chromatin structure with less H1 occupancy.
Correlation analyses indicate that H1d and H1c are inversely correlated with GC content, H3K4me3 mark, but positively correlated with H3K9me3 mark across the mouse ESC genome (Figure 3B). Our finding that the common peaks of H1d and H1c are enriched with AT-rich DNA sequences in vivo resonates with the previous observation that H1 is preferentially associated with scaffold associated regions (SAR) [61], which are also AT-rich sequences [62]. This binding feature may reflect a higher affinity of H1 to AT-tracts observed in in vitro studies [63], [64]. The GC content has been suggested to be an intrinsic factor for nucleosome occupancy [65], and our data suggest that it may also have an impact on H1 binding. It is also noteworthy that, compared with gene expression levels, H3K4me3 and H3K9me3 correlate better with H1 levels at TSS. For example, we did not observe dips of H1d and H1c around promoters of 40% genes when partitioned by H3K4me3 or H3K9me3 signals, whereas a small H1 signal dip exists even for the 20% genes with lowest expression values (Figure 2C, 2D, and 2E). It is possible that the steady state level of RNA messages (expression) may not faithfully reflect the active/inactive state of the promoters which may correlate better with the status of histone marks. It has been reported that promoters of many genes with low expression have high H3K4me3 levels [21], and we surmise that H1 may be absent from these gene promoters as well.
The co-localization of H1d and H1c with H3K9me3 suggests that these two variants are enriched at heterochromatin and may facilitate the maintenance of constitutive heterochromatin structure. Such association may be mediated through HP1, the heterochromatin protein binding to H3K9me3 and H3K9 methyltransferase Suv39h and facilitating spreading of heterochromatin marks [66]–[68]. Indeed, H1 has been shown to interact in vitro with HP1α [69], [70]. On the other hand, localization of HP1 is impaired in H1 depleted Drosophila [71], suggesting that H1 may also contribute to the proper targeting of HP1.
Surprisingly, we found that, at major satellite sequences, H1d and H1c signals are dramatically overrepresented, and this accounts for almost all the increased proportion of H1 sequence reads at repetitive sequences. The levels of H1d and H1c at major satellites are much higher than H3K9me3 (Figure 4B), a repressive histone mark also enriched at these repeats [34]. The overrepresentation of H1 at major satellites in ESCs is also supported by a longer NRL, which suggests a higher local H1 level than bulk chromatin and minor satellites. Consistent with previous observations [49], [51], we find that major satellites are more resistant to MNase digestion than bulk chromatin and minor satellites in ESCs (Figure 5), suggesting that pericentromeric regions may adopt special higher order chromatin structure as indicated by sucrose sedimentation assay [72]. High resolution mapping in this study identifies major satellites as the dominant preferential binding sites for H1 variants in ESCs, suggesting that H1 may play an important role in mediating the formation of distinct chromatin structure at pericetromeric regions. This is further supported by the effects of H1 depletion on chromocenter clustering and expression of major satellites. We note that a higher NRL in major satellites than bulk chromatin is also present in H1 TKO ESCs (Figure S10), suggesting a possible enrichment of the remaining H1 variants at major satellite sequences in H1 TKO ESCs. Consistently, we find that overexpressed H10 also appear to preferentially accumulate at satellite sequences in ESCs (Figure S14).
The enrichment of H1 at major satellites could not be solely attributed to the relatively high affinity of H1c and H1d to AT-rich sequences. Major and minor satellites sequences contain approximately 65% of A and T, with a ratio of A∶T being respective 2.6∶1 and 1.8∶1. This could result in major satellites having more A-tracts to which H1 might have a higher affinity. Phased nucleosome positioning observed at the major satellites [73], [74] could also contribute to the preferential binding of H1 at this region because different nucleosome positioning patterns have been shown to differentially affect H1 binding in vitro [75].
Mouse major satellites, constituting the pericentromere [76], [77] necessary for chromosome structure and function, are shown to form clusters/chromocenters, exhibit distinct heterochromatin features and adopt a more stable and condensed chromatin conformation than the bulk chromatin [49], [72]. Our findings of the preferential binding of H1 at major satellites and chromocenter clustering (reduced number of chromocenters) in H1 TKO ESCs suggest that H1 contributes to and may be required for the proper formation of pericentric heterochromatin. The rescue of the clustering effects by overexpressing H1d in H1 TKO ESCs or in H1dFLAG and H1cMyc cells compared with H1 TKO ESCs indicates that the total H1 level, rather than a specific H1 variant, is a key determining factor of chromocenter clustering. This conclusion is further supported by our finding that overexpressing H10 level to 3.5 fold of that of endogenous H10 in WT ESCs has little effect on chromocenter numbers or major satellite expression. In vitro studies have shown highly cooperative binding of H1 globular domain to DNA [78], a property which we speculate could contribute to increased chromocenter clustering in the face of marked reduction of H1 levels in H1 TKO ESCs. A larger nucleosome spacing (200 bp) (Figure 5) together with a higher local H1 level at major satellites could be important for efficient compaction of pericentromeric chromatin because nucleosome arrays with a NRL of 197 bp are able to form 30 nm fiber structure in vitro in the presence of linker histones whereas arrays with a short NRL are only able to form thinner and less compact structures [5].
The effects of H1 on major satellites are not restricted to chromatin structure and heterochromatin formation. Loss of H1c, H1d and H1e causes a dramatic increase in transcripts from major satellites, but does not change the levels of the repressive epigenetic marks, H3K9me3, H4K20me3, H3K27me3, or DNA methylation at these sequences. This suggests that the increase in expression of major satellites in H1 TKO ESCs is not mediated by loss of these repressive epigenetic marks, but rather caused by reduced binding of H1 per se or the potential decondensation of local chromatin structure. The phenomenon of changes in chromocenter organization independent of H3K9me3 is reminiscent of results from deletion of UHRF1 [52], a histone binding protein or overexpression of MeCP2 in mouse myoblasts [50]. Chromocenter organization is likely to be independent of H3K9me3 pathway because double deletion of Suv39h1 and Suv39h2 has minimal effects on the number and size of chromocenters in mouse cells [79], [80]. The expression changes in major satellites in H1 TKO ESCs are also not due to potential changes in cell cycle since H1 TKO ESCs have similar growth rate [26] and cell cycle profiles (data not shown) to WT ESCs. The reduction in expression levels of major satellites detected in RES cells compared with H1 TKO cells further supports that the drastic decrease in H1 levels causes de-repression of major satellites. Noncoding major satellite transcripts have been shown to be important for proper chromocenter formation [81], thus we speculate that the increased levels of major satellite transcripts contribute to chromocenter clustering in H1 TKO cells. In light of previous findings that ESCs null for DNA methyltransferases displayed chromocenter clustering [51], similar to what we observed in H1 TKO ESCs, we surmise that H1 and DNA methylation may act cooperatively in the proper maintenance of chromocenter structure.
In summary, we report high resolution maps of two abundant somatic H1 variants and the replacement H1 variant in mouse ESCs, connecting this important yet under-explored repressive mark with the well-studied ESC epigenome. The enrichment and effects of H1d, H1c and H10 on major satellites highlight an important role of these H1 variants in the maintenance of chromosome architecture and function. The cell lines and mouse strains we generated using the knock-in system also provide valuable tools for studying H1 variant specific functions both in vitro and in vivo. Genome-wide distribution studies of other H1 variants as well as in differentiated cell types are likely to lead to a better understanding of the role of H1 and higher order chromatin folding in gene expression and chromatin function.
Materials and Methods
Generation of H1dFLAG ESCs and H1dFLAG/FLAG mice
The H1dFLAG knock-in targeting vector containing H1d 5′ and 3′ homology regions flanking the N-terminal FLAG-tagged H1d and the SV40-Blasticidin resistant gene was transfected into ESCs as described previously [14]. 200 ESC clones resistant to 20 µg/ml Blasticidin (Life Technologies) and 2 µM gancyclovir (Sigma-Aldrich) were picked, and 5 clones with homologous recombination were identified by Southern blotting using the probe shown in Figure 1A. Two cis-targeted clones were injected into C57BL/6 recipient blastocysts to produce chimeric mice, which gave germline transmission. H1c+/−H1d+/FLAGH1e+/− mice were intercrossed to generate H1c−/−H1dFLAG/FLAGH1e−/− (H1dFLAG/FLAG) mice. All animal work was performed according to procedures approved by the Institutional Animal Care and Use Committee (IACUC) at Georgia Institute of Technology.
Preparation and analysis of histones
Nuclei and chromatin of ESCs and mouse tissues were prepared and analyzed according to protocols described previously [82], [83]. Histones were extracted from chromatin with 0.2 N sulfuric acid and 50–100 µg of total histone preparations were injected into a C18 reverse phase column (Vydac) on an ÄKTA UPC10 system (GE Healthcare). The effluent was monitored at 214 nm (A214), and the peak areas were recorded and analyzed with ÄKTA UNICORN 5.11 software. The A214 values of the H1 and H2B peaks were adjusted by the number of peptide bonds in each H1 variant and H2B. The H1/nucleosome ratio was determined by dividing the A214 of all H1 peaks by half of the A214 of the H2B peak. Fractions corresponding to different H1 variants from HPLC analysis were collected, lyophilized and analyzed with silver staining, Coomassie staining and Western blotting.
Antibodies
The following antibodies were used in this study: anti-FLAG (Sigma-Aldrich F3165), anti-DYKDDDDK tag (Cell Signaling #2368), anti-Myc-tag (Cell Signaling #2272), anti-H3K4me3 (Millipore 07-473), anti-H3K9me3 (Abcam 8898), anti-H3K27me3 (Millipore 07-449), anti-H4K20me3 (Millipore 07-463), anti-H10 (Santa Cruz 56695), anti-H1 (Milipore 05-457) and IgG (Millipore 12-370).
Chromatin immunoprecipitation (ChIP)
ChIP assays were performed as described previously [26] with the following modifications: 20 µl of Dynabeads Protein G (Life Technologies) were incubated with 2 µg of antibody for 4 hours, followed by incubation with 40 µg of sonicated soluble chromatin overnight at 4°C. Dynabeads were washed, immunoprecipitates were eluted, and DNA-protein complexes were incubated overnight at 65°C to reverse crosslinks. DNA was purified with a DNA Isolation column (Qiagen). Input control DNA was prepared from reverse-crosslinked soluble chromatin prior to immunoprecipitation. Quantitatitve PCR on ChIP samples for major satellites, minor satellites, LINE L1, IAP LTR and Hprt was performed with primers published previously [45], [84].
Generation of ChIP–seq libraries
The libraries for massive parallel sequencing were prepared with the ChIP-seq Sample Preparation Kit (Illumina) according to the manufacturer's instructions. Briefly, 10 ng of immunoprecipiated DNA or input DNA were end repaired, 3′ adenylated and ligated with adapter oligos supplied by the manufacturer. DNA fragments within the range of 120∼500 bp were purified following gel electrophoresis and amplified with primers provided by the manufacturer. Library DNA was subsequently purified with a Qiagen DNA Isolation column, quantified and submitted for sequencing.
Sequence reads processing and alignment
Sequencing was performed with Illumina Genome Analyzer II and Illumina HiSeq 2000 systems, and raw sequence reads containing more than 30% of ‘N’ were removed and adaptor sequences were trimmed. Clean sequences were aligned against mouse genome, mm9 (UCSC website), and 2,669 categories of mammalian repeats from RepBase version 14.07 [39], [40] using Bowtie aligner software (http://bowtie-bio.sourceforge.net/index.shtml). The first 40 bp (for alignment to mm9) or the first 35 bp (for alignment to RepBase) of the reads were used as seed sequences with up to two mismatches allowed for the alignment, and aligned number of reads were scored. Reads with multiple alignment positions were mapped randomly to one of the possible position. Reads for each ChIP-seq or input-seq library aligned to mm9 were normalized to 10 million reads, and IP-IN signals were calculated in each 100 bp sliding window by subtraction of normalized read counts per 10 million mappable reads of ChIP-seq library by that of its corresponding input-seq library using GenPlay software (http://genplay.einstein.yu.edu/wiki/index.php/Documentation) [33]). Percentage of reads for each repeat mapped to RepBase was calculated by dividing reads mapped to the respective repeat by the total reads in the library, and the fold enrichment for the respective repeat was subsequently calculated as the ratio of the percent of reads of ChIP-seq library to that of the input-seq library. Read length and read counts of each library are listed in Table S1. Representative ChIP-seq libraries with the most sequencing reads mapped to mm9 were utilized for genome browser visualization and metagene analysis, and all replicate ChIP-seq libraries were included in repetitive sequence analysis. Sequencing data have been deposited in NCBI's Gene Expression Omnibus database and assigned GEO Series accession number GSE46134.
Genome-wide correlation analysis
The sum of signals (IP-IN) for each 1000 bp window (normalized to 10 million reads) was used to calculate the correlation coefficients of H1 variants with GC% and different histone markers. Genome-wide and chromosome-wide correlation coefficients were calculated, and the scatter-plots were generated using Matlab.
Overrepresentation and distribution pattern analysis
Significantly enriched regions were identified using GenPlay or SICER v1.1 [36] at the following parameter settings: window size = 200, gap size = 600, E-value = 1000, an effective genome size of 80% of the entire mouse genome, and q-value (FDR) = 0.001. In order to optimize the gap size for H1 variants, the gap size was varied from 0 to 3 times the window size (0, 200, 400, 600) and the best value was chosen according to the criteria as previously described [36]. Distribution of peak regions relative to gene regions was analyzed by CEAS [37]. Top 10% of enriched regions for each ChIP-seq library were selected to identify the overrepresented features using EpiGRAPH (http://epigraph.mpi-inf.mpg.de/WebGRAPH/) [38]. 2214 H1d/H1c common peaks, 1939 H1d unique peaks, 433 H1c unique peaks, 1891 H3K9me3 peaks, 4778 H3K27me3 peaks, and 3446 H3K4me3 peaks were analyzed by EpiGRAPH.
Determination of nucleosome repeat length (NRL)
ESC nuclei were extracted and MNase digestion was performed as described previously [26]. Briefly, 2.5×106 nuclei were resuspended in 200 µl of MNase digestion buffer (0.32 M sucrose, 50 mM Tris-HCl pH 7.5, 4 mM MgCl2, 1 mM CaCl2, 0.1 mM PMSF) and digested at 37°C with 20 units of micrococcal nuclease (MNase) (Worthington) for time course analysis or 2 units of MNase (Worthington) for 5 min in analysis shown in Figure S10A. Nuclei were lysed and DNA was subsequently purified and analyzed by electrophoresis. Southern blotting was performed using major or minor satellite specific probes as described previously [26]. The NRL at each time point was calculated using the regression line generated with size (bp) of polynucleosomes [7], [26], and the values at time “0” were extrapolated as described previously [72].
Fluorescence in situ hybridization (FISH)
FISH was performed as described previously [85]. The major satellite probe was biotin-labeled, denatured and hybridized to the slides overnight. The nuclei were incubated with FITC-Avidin for 1 hour, and counterstained with DAPI. Signals were detected with an Olympus Epifluorescence Microscope (Olympus, Inc.) equipped with an Olympus QCLR3 cooled digital camera. The experiments were repeated three times, and the number of chromocenters for each cell line was counted by three researchers as blind tests. Statistical analysis was performed using a Mann-Whitney U nonparametric test. Areas of chromocenters were quantitated using AxioVision software V4.8.2.0 and presented as pixel2. The conversion factor of pixel/micron was 18.7 pixels per micrometer.
Quantitative reverse transcription PCR (qRT–PCR)
1 µg of total RNA extracted from ESCs was treated with RNase free DNaseI (Sigma-Aldrich) and reverse transcribed using a SuperScript first-strand cDNA synthesis kit with random hexamers (Life Technologies). Triplicate PCR reactions using the iQ SYBR Green Supermix (Bio-Rad) were analyzed in a MyIQ Real-Time PCR Detection System (Bio-Rad). All samples were typically analyzed in two independent experiments. Relative expression units were calculated by subtracting the mock reverse-transcribed signals (RT−) from reverse transcribed signals (RT+) and normalizing the adjusted values with signals of the housekeeping gene GAPDH. The qRT-PCR primers for repetitive sequences are the same as in qChIP, and the primers for GAPDH are as described previously [53].
Bisulfite treatment of DNA and sequencing analysis
1 µg of DNA extracted from ESCs was treated with the CpGenome DNA modification Kit (Millipore) according to the manufacturer's manual. 20 ng of treated DNA was used in each PCR reaction as previously described [26]. The primers used to generate PCR products from the bisulfite-converted DNA are specific for the converted DNA sequence of the analyzed regions. The PCR products were subsequently cloned using the TOPO TA Cloning kit (Life Technologies), and colonies containing the converted DNA inserts were picked. DNA inserts were sequenced and analyzed with BiQ Analyzer [86]. Primers for major and minor satellites were as previously described [87].
Supporting Information
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Zdroje
1. Wolffe AP (1998) Chromatin: Structure and Function. San Diego, CA: Academic Press.
2. van Holde KE (1989) Chromatin: New York: Springer-Verlag.
3. BednarJ, HorowitzRA, GrigoryevSA, CarruthersLM, HansenJC, et al. (1998) Nucleosomes, linker DNA, and linker histone form a unique structural motif that directs the higher-order folding and compaction of chromatin. Proc Natl Acad Sci U S A 95 : 14173–14178.
4. RobinsonPJ, FairallL, HuynhVA, RhodesD (2006) EM measurements define the dimensions of the “30-nm” chromatin fiber: evidence for a compact, interdigitated structure. Proc Natl Acad Sci U S A 103 : 6506–6511.
5. RouthA, SandinS, RhodesD (2008) Nucleosome repeat length and linker histone stoichiometry determine chromatin fiber structure. Proc Natl Acad Sci U S A 105 : 8872–8877.
6. HappelN, DoeneckeD (2009) Histone H1 and its isoforms: contribution to chromatin structure and function. Gene 431 : 1–12.
7. FanY, NikitinaT, Morin-KensickiEM, ZhaoJ, MagnusonTR, et al. (2003) H1 linker histones are essential for mouse development and affect nucleosome spacing in vivo. Mol Cell Biol 23 : 4559–4572.
8. LennoxRW, CohenLH (1983) The histone H1 complements of dividing and nondividing cells of the mouse. J Biol Chem 258 : 262–268.
9. MedrzyckiM, ZhangY, McDonaldJF, FanY (2012) Profiling of linker histone variants in ovarian cancer. Front Biosci 17 : 396–406.
10. WangZF, SirotkinAM, BucholdGM, SkoultchiAI, MarzluffWF (1997) The mouse histone H1 genes: gene organization and differential regulation. J Mol Biol 271 : 124–138.
11. WarneboldtJ, HallerF, HorstmannO, DannerBC, FuzesiL, et al. (2008) Histone H1x is highly expressed in human neuroendocrine cells and tumours. BMC Cancer 8 : 388.
12. SirotkinAM, EdelmannW, ChengG, Klein-SzantoA, KucherlapatiR, et al. (1995) Mice develop normally without the H1(0) linker histone. Proc Natl Acad Sci U S A 92 : 6434–6438.
13. LinQ, SirotkinA, SkoultchiAI (2000) Normal spermatogenesis in mice lacking the testis-specific linker histone H1t. Mol Cell Biol 20 : 2122–2128.
14. FanY, SirotkinA, RussellRG, AyalaJ, SkoultchiAI (2001) Individual somatic H1 subtypes are dispensable for mouse development even in mice lacking the H1(0) replacement subtype. Mol Cell Biol 21 : 7933–7943.
15. RabiniS, FrankeK, SaftigP, BodeC, DoeneckeD, et al. (2000) Spermatogenesis in mice is not affected by histone H1.1 deficiency. Exp Cell Res 255 : 114–124.
16. GunjanA, BrownDT (1999) Overproduction of histone H1 variants in vivo increases basal and induced activity of the mouse mammary tumor virus promoter. Nucleic Acids Res 27 : 3355–3363.
17. AlamiR, FanY, PackS, TMS, BesseA, et al. (2003) Mammalian linker-histone subtypes differentially affect gene expression invivo. Proc Natl Acad Sci U S A 100 : 5920–5925.
18. SanchoM, DianiE, BeatoM, JordanA (2008) Depletion of human histone H1 variants uncovers specific roles in gene expression and cell growth. PLoS Genet 4: e1000227 doi:10.1371/journal.pgen.1000227.
19. LuR, MarkowetzF, UnwinRD, LeekJT, AiroldiEM, et al. (2009) Systems-level dynamic analyses of fate change in murine embryonic stem cells. Nature 462 : 358–362.
20. MeissnerA (2010) Epigenetic modifications in pluripotent and differentiated cells. Nat Biotechnol 28 : 1079–1088.
21. BernsteinBE, MikkelsenTS, XieX, KamalM, HuebertDJ, et al. (2006) A bivalent chromatin structure marks key developmental genes in embryonic stem cells. Cell 125 : 315–326.
22. CreyghtonMP, ChengAW, WelsteadGG, KooistraT, CareyBW, et al. (2010) Histone H3K27ac separates active from poised enhancers and predicts developmental state. Proc Natl Acad Sci U S A 107 : 21931–21936.
23. CreyghtonMP, MarkoulakiS, LevineSS, HannaJ, LodatoMA, et al. (2008) H2AZ is enriched at polycomb complex target genes in ES cells and is necessary for lineage commitment. Cell 135 : 649–661.
24. BirneyE, StamatoyannopoulosJA, DuttaA, GuigoR, GingerasTR, et al. (2007) Identification and analysis of functional elements in 1% of the human genome by the ENCODE pilot project. Nature 447 : 799–816.
25. BernsteinBE, StamatoyannopoulosJA, CostelloJF, RenB, MilosavljevicA, et al. (2010) The NIH Roadmap Epigenomics Mapping Consortium. Nat Biotechnol 28 : 1045–1048.
26. FanY, NikitinaT, ZhaoJ, FleuryTJ, BhattacharyyaR, et al. (2005) Histone h1 depletion in mammals alters global chromatin structure but causes specific changes in gene regulation. Cell 123 : 1199–1212.
27. ZhangY, LiuZ, MedrzyckiM, CaoK, FanY (2012) Reduction of Hox gene expression by histone H1 depletion. PLoS ONE 7: e38829 doi:10.1371/journal.pone.0038829.
28. ClausellJ, HappelN, HaleTK, DoeneckeD, BeatoM (2009) Histone H1 subtypes differentially modulate chromatin condensation without preventing ATP-dependent remodeling by SWI/SNF or NURF. PLoS ONE 4: e0007243 doi: 10.1371/journal.pone.0007243.
29. Th'ngJP, SungR, YeM, HendzelMJ (2005) H1 family histones in the nucleus. Control of binding and localization by the C-terminal domain. J Biol Chem 280 : 27809–27814.
30. MeergansT, AlbigW, DoeneckeD (1997) Varied expression patterns of human H1 histone genes in different cell lines. DNA Cell Biol 16 : 1041–1049.
31. LangmeadB, TrapnellC, PopM, SalzbergSL (2009) Ultrafast and memory-efficient alignment of short DNA sequences to the human genome. Genome Biol 10: R25.
32. KidderBL, YangJ, PalmerS (2008) Stat3 and c-Myc genome-wide promoter occupancy in embryonic stem cells. PLoS ONE 3: e3932 doi:10.1371/journal.pone.0003932.
33. LajugieJ, BouhassiraEE (2011) GenPlay, a multipurpose genome analyzer and browser. Bioinformatics 27 : 1889–1893.
34. MikkelsenTS, KuM, JaffeDB, IssacB, LiebermanE, et al. (2007) Genome-wide maps of chromatin state in pluripotent and lineage-committed cells. Nature 448 : 553–560.
35. GuentherMG, LevineSS, BoyerLA, JaenischR, YoungRA (2007) A chromatin landmark and transcription initiation at most promoters in human cells. Cell 130 : 77–88.
36. ZangC, SchonesDE, ZengC, CuiK, ZhaoK, et al. (2009) A clustering approach for identification of enriched domains from histone modification ChIP-Seq data. Bioinformatics 25 : 1952–1958.
37. ShinH, LiuT, ManraiAK, LiuXS (2009) CEAS: cis-regulatory element annotation system. Bioinformatics 25 : 2605–2606.
38. BockC, HalachevK, BuchJ, LengauerT (2009) EpiGRAPH: user-friendly software for statistical analysis and prediction of (epi)genomic data. Genome Biol 10: R14.
39. JurkaJ (2000) Repbase update: a database and an electronic journal of repetitive elements. Trends Genet 16 : 418–420.
40. JurkaJ, KapitonovVV, PavlicekA, KlonowskiP, KohanyO, et al. (2005) Repbase Update, a database of eukaryotic repetitive elements. Cytogenet Genome Res 110 : 462–467.
41. BockC, TomazouEM, BrinkmanAB, MullerF, SimmerF, et al. (2010) Quantitative comparison of genome-wide DNA methylation mapping technologies. Nat Biotechnol 28 : 1106–1114.
42. BelancioVP, Roy-EngelAM, PochampallyRR, DeiningerP (2010) Somatic expression of LINE-1 elements in human tissues. Nucleic Acids Res 38 : 3909–3922.
43. PackerAI, ManovaK, BachvarovaRF (1993) A discrete LINE-1 transcript in mouse blastocysts. Dev Biol 157 : 281–283.
44. TreloganSA, MartinSL (1995) Tightly regulated, developmentally specific expression of the first open reading frame from LINE-1 during mouse embryogenesis. Proc Natl Acad Sci U S A 92 : 1520–1524.
45. MartensJH, O'SullivanRJ, BraunschweigU, OpravilS, RadolfM, et al. (2005) The profile of repeat-associated histone lysine methylation states in the mouse epigenome. EMBO J 24 : 800–812.
46. WoodcockCL, SkoultchiAI, FanY (2006) Role of linker histone in chromatin structure and function: H1 stoichiometry and nucleosome repeat length. Chromosome Res 14 : 17–25.
47. ObergC, IzzoA, SchneiderR, WrangeO, BelikovS (2012) Linker histone subtypes differ in their effect on nucleosomal spacing in vivo. J Mol Biol 419 : 183–197.
48. HsuTC, CooperJE, MaceMLJr, BrinkleyBR (1971) Arrangement of centromeres in mouse cells. Chromosoma 34 : 73–87.
49. GuenatriM, BaillyD, MaisonC, AlmouzniG (2004) Mouse centric and pericentric satellite repeats form distinct functional heterochromatin. J Cell Biol 166 : 493–505.
50. BreroA, EaswaranHP, NowakD, GrunewaldI, CremerT, et al. (2005) Methyl CpG-binding proteins induce large-scale chromatin reorganization during terminal differentiation. J Cell Biol 169 : 733–743.
51. GilbertN, ThomsonI, BoyleS, AllanJ, RamsahoyeB, et al. (2007) DNA methylation affects nuclear organization, histone modifications, and linker histone binding but not chromatin compaction. J Cell Biol 177 : 401–411.
52. PapaitR, PistoreC, GraziniU, BabbioF, CogliatiS, et al. (2008) The PHD domain of Np95 (mUHRF1) is involved in large-scale reorganization of pericentromeric heterochromatin. Mol Biol Cell 19 : 3554–3563.
53. ZhangY, CookeM, PanjwaniS, CaoK, KrauthB, et al. (2012) Histone h1 depletion impairs embryonic stem cell differentiation. PLoS Genet 8: e1002691 doi:10.1371/journal.pgen.1002691.
54. RudertF, BronnerS, GarnierJM, DolleP (1995) Transcripts from opposite strands of gamma satellite DNA are differentially expressed during mouse development. Mamm Genome 6 : 76–83.
55. BerrettaJ, MorillonA (2009) Pervasive transcription constitutes a new level of eukaryotic genome regulation. EMBO Rep 10 : 973–982.
56. Bouzinba-SegardH, GuaisA, FrancastelC (2006) Accumulation of small murine minor satellite transcripts leads to impaired centromeric architecture and function. Proc Natl Acad Sci U S A 103 : 8709–8714.
57. ZlatanovaJ, DoeneckeD (1994) Histone H1 zero: a major player in cell differentiation? FASEB J 8 : 1260–1268.
58. LiJY, PattersonM, MikkolaHK, LowryWE, KurdistaniSK (2012) Dynamic distribution of linker histone h1.5 in cellular differentiation. PLoS Genet 8: e1002879 doi:10.1371/journal.pgen.1002879.
59. KrishnakumarR, GambleMJ, FrizzellKM, BerrocalJG, KininisM, et al. (2008) Reciprocal binding of PARP-1 and histone H1 at promoters specifies transcriptional outcomes. Science 319 : 819–821.
60. BraunschweigU, HoganGJ, PagieL, van SteenselB (2009) Histone H1 binding is inhibited by histone variant H3.3. EMBO J 28 : 3635–3645.
61. IzaurraldeE, KasE, LaemmliUK (1989) Highly preferential nucleation of histone H1 assembly on scaffold-associated regions. J Mol Biol 210 : 573–585.
62. MirkovitchJ, MiraultME, LaemmliUK (1984) Organization of the higher-order chromatin loop: specific DNA attachment sites on nuclear scaffold. Cell 39 : 223–232.
63. KasE, IzaurraldeE, LaemmliUK (1989) Specific inhibition of DNA binding to nuclear scaffolds and histone H1 by distamycin. The role of oligo(dA).oligo(dT) tracts. J Mol Biol 210 : 587–599.
64. BonnefoyE, BanduMT, DolyJ (1999) Specific binding of high-mobility-group I (HMGI) protein and histone H1 to the upstream AT-rich region of the murine beta interferon promoter: HMGI protein acts as a potential antirepressor of the promoter. Mol Cell Biol 19 : 2803–2816.
65. TilloD, HughesTR (2009) G+C content dominates intrinsic nucleosome occupancy. BMC Bioinformatics 10 : 442.
66. BannisterAJ, ZegermanP, PartridgeJF, MiskaEA, ThomasJO, et al. (2001) Selective recognition of methylated lysine 9 on histone H3 by the HP1 chromo domain. Nature 410 : 120–124.
67. LachnerM, O'CarrollD, ReaS, MechtlerK, JenuweinT (2001) Methylation of histone H3 lysine 9 creates a binding site for HP1 proteins. Nature 410 : 116–120.
68. JonesDO, CowellIG, SinghPB (2000) Mammalian chromodomain proteins: their role in genome organisation and expression. Bioessays 22 : 124–137.
69. NielsenAL, Oulad-AbdelghaniM, OrtizJA, RemboutsikaE, ChambonP, et al. (2001) Heterochromatin formation in mammalian cells: interaction between histones and HP1 proteins. Mol Cell 7 : 729–739.
70. DaujatS, ZeisslerU, WaldmannT, HappelN, SchneiderR (2005) HP1 binds specifically to Lys26-methylated histone H1.4, whereas simultaneous Ser27 phosphorylation blocks HP1 binding. J Biol Chem 280 : 38090–38095.
71. LuX, WontakalSN, EmelyanovAV, MorcilloP, KonevAY, et al. (2009) Linker histone H1 is essential for Drosophila development, the establishment of pericentric heterochromatin, and a normal polytene chromosome structure. Genes Dev 23 : 452–465.
72. GilbertN, AllanJ (2001) Distinctive higher-order chromatin structure at mammalian centromeres. Proc Natl Acad Sci U S A 98 : 11949–11954.
73. ZhangXY, HorzW (1984) Nucleosomes are positioned on mouse satellite DNA in multiple highly specific frames that are correlated with a diverged subrepeat of nine base-pairs. J Mol Biol 176 : 105–129.
74. LinxwellerW, HorzW (1985) Reconstitution experiments show that sequence-specific histone-DNA interactions are the basis for nucleosome phasing on mouse satellite DNA. Cell 42 : 281–290.
75. PanettaG, ButtinelliM, FlausA, RichmondTJ, RhodesD (1998) Differential nucleosome positioning on Xenopus oocyte and somatic 5 S RNA genes determines both TFIIIA and H1 binding: a mechanism for selective H1 repression. J Mol Biol 282 : 683–697.
76. Choo KHA (1997) The centromere. Oxford; New York: Oxford University Press. xiv, 304 p. p.
77. ProbstAV, AlmouzniG (2008) Pericentric heterochromatin: dynamic organization during early development in mammals. Differentiation 76 : 15–23.
78. ThomasJO, ReesC, FinchJT (1992) Cooperative binding of the globular domains of histones H1 and H5 to DNA. Nucleic Acids Res 20 : 187–194.
79. PetersAH, O'CarrollD, ScherthanH, MechtlerK, SauerS, et al. (2001) Loss of the Suv39h histone methyltransferases impairs mammalian heterochromatin and genome stability. Cell 107 : 323–337.
80. Harnicarova HorakovaA, GaliovaG, LegartovaS, KozubekS, MatulaP, et al. (2010) Chromocentre integrity and epigenetic marks. J Struct Biol 169 : 124–133.
81. ProbstAV, OkamotoI, CasanovaM, El MarjouF, Le BacconP, et al. (2010) A strand-specific burst in transcription of pericentric satellites is required for chromocenter formation and early mouse development. Dev Cell 19 : 625–638.
82. FanY, SkoultchiAI (2004) Genetic analysis of H1 linker histone subtypes and their functions in mice. Methods Enzymol 377 : 85–107.
83. MedrzyckiM, ZhangY, CaoK, FanY (2012) Expression analysis of mammalian linker-histone subtypes. J Vis Exp 61: e3577 doi: 10.3791/3577.
84. BoyerLA, PlathK, ZeitlingerJ, BrambrinkT, MedeirosLA, et al. (2006) Polycomb complexes repress developmental regulators in murine embryonic stem cells. Nature 441 : 349–353.
85. ZhouJ, SalequeS, ErmakovaO, SepulvedaMA, YangQ, et al. (2005) Changes in replication, nuclear location, and expression of the Igh locus after fusion of a pre-B cell line with a T cell line. J Immunol 175 : 2317–2320.
86. BockC, ReitherS, MikeskaT, PaulsenM, WalterJ, et al. (2005) BiQ Analyzer: visualization and quality control for DNA methylation data from bisulfite sequencing. Bioinformatics 21 : 4067–4068.
87. YamagataK, YamazakiT, MikiH, OgonukiN, InoueK, et al. (2007) Centromeric DNA hypomethylation as an epigenetic signature discriminates between germ and somatic cell lineages. Dev Biol 312 : 419–426.
Štítky
Genetika Reprodukční medicínaČlánek vyšel v časopise
PLOS Genetics
2013 Číslo 4
- Kazuistika – Perspektivy využití precizované medicíny v rámci personalizované specifické terapie onkologických pacientů
- Nobelova cena za chemii pro genetické nůžky: Objev, který změní naši budoucnost?
- Technologie na bázi RNA v klinické praxi: od přebarvených petúnií k terapii vzácných a dosud jen obtížně léčitelných chorob u lidí
- „Nepředstavovali jsme si, že náš výzkum povede přímo ke vzniku nových léků, dokonce ještě za našeho života“
- Bezplatné služby pro diagnostiku ATTRv amyloidózy pro kardiology
Nejčtenější v tomto čísle
- The G4 Genome
- Neutral Genomic Microevolution of a Recently Emerged Pathogen, Serovar Agona
- The Histone Demethylase Jarid1b Ensures Faithful Mouse Development by Protecting Developmental Genes from Aberrant H3K4me3
- The Tissue-Specific RNA Binding Protein T-STAR Controls Regional Splicing Patterns of Pre-mRNAs in the Brain
Zvyšte si kvalifikaci online z pohodlí domova
Mazová zátka a její řešení
nový kurzVšechny kurzy