
Crossover Patterning by the Beam-Film Model: Analysis and Implications
Crossing-over is a central feature of meiosis. Meiotic crossover (CO) sites are spatially patterned along chromosomes. CO-designation at one position disfavors subsequent CO-designation(s) nearby, as described by the classical phenomenon of CO interference. If multiple designations occur, COs tend to be evenly spaced. We have previously proposed a mechanical model by which CO patterning could occur. The central feature of a mechanical mechanism is that communication along the chromosomes, as required for CO interference, can occur by redistribution of mechanical stress. Here we further explore the nature of the beam-film model, its ability to quantitatively explain CO patterns in detail in several organisms, and its implications for three important patterning-related phenomena: CO homeostasis, the fact that the level of zero-CO bivalents can be low (the “obligatory CO”), and the occurrence of non-interfering COs. Relationships to other models are discussed.
Published in the journal:
. PLoS Genet 10(1): e32767. doi:10.1371/journal.pgen.1004042
Category:
Research Article
doi:
https://doi.org/10.1371/journal.pgen.1004042
Summary
Crossing-over is a central feature of meiosis. Meiotic crossover (CO) sites are spatially patterned along chromosomes. CO-designation at one position disfavors subsequent CO-designation(s) nearby, as described by the classical phenomenon of CO interference. If multiple designations occur, COs tend to be evenly spaced. We have previously proposed a mechanical model by which CO patterning could occur. The central feature of a mechanical mechanism is that communication along the chromosomes, as required for CO interference, can occur by redistribution of mechanical stress. Here we further explore the nature of the beam-film model, its ability to quantitatively explain CO patterns in detail in several organisms, and its implications for three important patterning-related phenomena: CO homeostasis, the fact that the level of zero-CO bivalents can be low (the “obligatory CO”), and the occurrence of non-interfering COs. Relationships to other models are discussed.
Introduction
Crossover (CO) recombination interactions occur stochastically at different positions in different meiotic nuclei. Nonetheless, along a given chromosome, COs tend to be evenly spaced. This interesting phenomenon implies the existence of communication along chromosomes, the nature of which is not understood. CO patterning, commonly known as “CO interference”, was originally detected from genetic studies in Drosophila [1], [2]. It was found that the frequency of meiotic gametes exhibiting two crossovers close together along the same chromosome (“double COs”) was lower than that expected for their independent occurrence. The implication was that occurrence of one CO (or more correctly one CO-designation) “interferes” with the occurrence of another CO (CO-designation) nearby.
We previously proposed a model for CO patterning in which macroscopic mechanical properties of chromosomes play governing roles via accumulation, relief and redistribution of stress (Figure 1A) [3], [4]. In that model, a chromosome with an array of precursor interactions comes under mechanical stress along its length. Eventually, a first interaction “goes critical”, undergoing a stress-promoted molecular change which designates it to eventually mature as a CO. By its intrinsic nature, this change results in local relief of stress. That local relaxation then redistributes outward in the immediate vicinity of its nucleation point, in both directions, dissipating with distance. A new stress distribution is thereby produced, with the stress level reduced in the vicinity of the CO-designation site, to a decreasing extent with increasing distance from its nucleation point. This effect disfavors occurrence of additional (stress-promoted) CO designations in the affected region. The spreading inhibitory signal comprises “CO interference”. More such CO-designations may then occur, sequentially, each accompanied by spreading interference. Each subsequent event will tend to occur in a region where the stress level remains higher, which will necessarily tend to be regions far away from prior CO-designated sites. Thus, as more and more designation events occur, they tend to fill in the holes between prior events, ultimately producing an evenly-spaced array. The most attractive feature of this proposed mechanism is the fact that redistribution of stress is an intrinsic feature of any mechanical system, thus comprising a built-in communication network as required for spreading CO interference.

CO-designated interactions then undergo multiple additional biochemical steps to finally become mature CO products [5]. Precursors that do not undergo CO-designation mature to other fates, predominantly inter-homolog non-crossovers (NCOs).
CO patterning by the above stress-and-stress relief mechanism can be modeled quantitatively by analogy with a known physical system that exhibits analogous behavior, giving the beam-film (BF) model [3].
We note that BF model simulations can be applied to any mechanism whose effects are described by the same mathematical expressions as the beam-film case. In such a more general formulation (Figure 1B), there is again an array of precursor interactions. That array would be acted upon by a “Designation Driving Force” (DDF). Event-designations would occur sequentially (or nearly so). Each designation would set up a spreading inhibitory effect that spreads outward in both directions, decreasing in strength with increasing distance, thereby decreasing the ability of the affected precursors to respond to the DDF. When multiple designation/interference events occur, they would produce an evenly-spaced array. Maturation of CO-designated and not-CO-designated interactions ensues.
The present study adds several new features to the BF simulation program and explores in further detail the predictions and implications of the BF model (whether mechanical or general). We evaluate the ability of the model to quantitatively explain experimental CO pattern data sets in budding yeast, tomato, grasshopper and Drosophila. Our results show that the logic and mathematics of the BF model are remarkably robust in explaining experimental data. New information of biological interest also emerges. We then present detailed considerations of three phenomena of interest, the so-called “obligatory CO” and “CO homeostasis”, and the nature of “non-interfering COs”. We discuss how these phenomena are explained by the BF model and show that BF predictions can very accurately explain experimental data pertaining to these effects. Overall, the presented results show that BF simulation analysis is a useful approach for exploring experimental CO patterns. Other applications of this analysis are presented elsewhere. The current study has also provided new criteria for characterization of CO patterns using Coefficient of Coincidence analysis and illustrates both short-comings and useful applications of gamma distribution analysis. Relationships of the BF model to other models are discussed.
Results
Part I. Coefficient of Coincidence (CoC) Relationships and the Event Distribution (ED)
CO data sets, whether experimental or from BF simulations, comprise descriptions of the positions of individual COs along the lengths of each of a large number of different chromosomes (“bivalents”). Each bivalent represents the outcome of CO-designation in a single meiotic nucleus; the entire data set comprises the outcomes of CO patterning for a particular chromosome in many nuclei.
CoC relationships
The classical description of CO interference relationships is Coefficient of Coincidence (CoC) analysis [1], [2]. For this purpose (Figure 2A), the chromosome of interest is divided into a number of intervals and for each interval the total frequency of COs in the many chromosomes examined is observed. Intervals are then considered in pairs, in all possible pairwise combinations. For each pair, the observed frequency of bivalents exhibiting a CO in both intervals (“double COs”) is compared with the frequency expected if events occurred independently in the two intervals. The latter frequency is given by the product of the total frequencies of events in the two intervals, each considered individually. For any pair of intervals, the ratio of the frequency of observed double COs to the frequency of expected double COs (Observed/Expected) is the Coefficient of Coincidence (CoC). If events occur independently in the two intervals, the CoC for that pair of intervals is one. If (positive) CO interference is present for the two intervals, the CoC is less than one (some expected COs have been inhibited). CoC values for all interval pairs are then plotted as a function of the distance between the corresponding intervals (defined as the distance between the centers of the two intervals).

The classical resulting CO interference CoC pattern is illustrated by an appropriate set of BF simulations (Figure 2B). When intervals are close together (short inter-interval distances), the frequency of observed COs is much less than that expected from independent occurrence (CoC<<1), reflecting “interference”. The CoC increases with increasing inter-interval distance to a value of ∼1. Additionally, because COs tend to be evenly spaced, the CoC value rises above ∼1 specifically at the average distance between adjacent COs (or multiples thereof): at these particular spacings, the probability of a double CO is higher than that predicted by random occurrence. This tendency is increasingly pronounced as interference extends over longer and longer fractions of total chromosome length.
BF simulations specify a parameter for interference distance, denoted “L” ([3]; below). Figure 2B illustrates CoC curves for simulations at varying values of L. For any actual CoC curve, whether experimental or simulated, a useful parameter for describing the strength of CO interference is the inter-interval distance at which the CoC = 0.5. We define this parameter as LCoC (Figure 2B; vertical arrows). Where appropriate, the value of the BF-specified parameter “L” is denoted alternatively as LBF to distinguish it from LCoC (Figure 2B). Interestingly, the values of LCoC and LBF are always quite similar (e.g. Figure 2B).
CoC analysis provides a very accurate and reproducible description of CO patterns for experimental data sets as long as two requirements are met (Figure S1, Protocol S1). First, chromosomes must be divided into a large enough number of intervals that double COs within an interval are rare. If this requirement is not met, closely-spaced double COs will be missed. In general, interval size should be less than ∼1/4 the average distance between adjacent COs. Second, the data set must be large enough to give significant numbers of double COs. As a practical matter, where possible (e.g. for cytological markers of CO positions), interval size should be decreased progressively until the CoC curve no longer changes.
We further note that the appropriate metric for CO interference is physical distance along the chromosome. This has been shown to be the case for mouse and Arabidopsis [6]–[8]; for tomato (as described below); and for budding yeast (L.Z., unpublished). Accordingly, disruption of chromosome continuity abolishes the transmission of interference in C.elegans [9]. Experimentally, “interference distance” is defined in units of µm pachytene (synaptonemal complex; SC) length. In reality, SC length is often (or always) a proxy for chromosome length at the preceding stage (leptotene): in yeast, Sordaria and likely other organisms, CO patterning occurs at the leptotene stage and nucleates SC formation (e.g., [4]).
The ED
CO patterns are also reflected in the average number of COs per bivalent and the fractions of chromosomes exhibiting different numbers of COs, which we refer to as the “Event Distribution” or “ED”. As the “interference distance” increases, the distribution of COs per bivalent shifts to lower numbers with a corresponding decrease in the average number of COs per bivalent (Figure 2C).
Part II. Parameters of the BF Model and Their Roles for CO Patterns
BF simulations require specification of three types of parameters (Table 1). One set describes the nature of the precursor array upon which CO-designation acts; a second set describes features of the patterning process per se; and a third precursor specifies the efficiency with which a designated event matures into a detectable CO or CO-correlated signal.
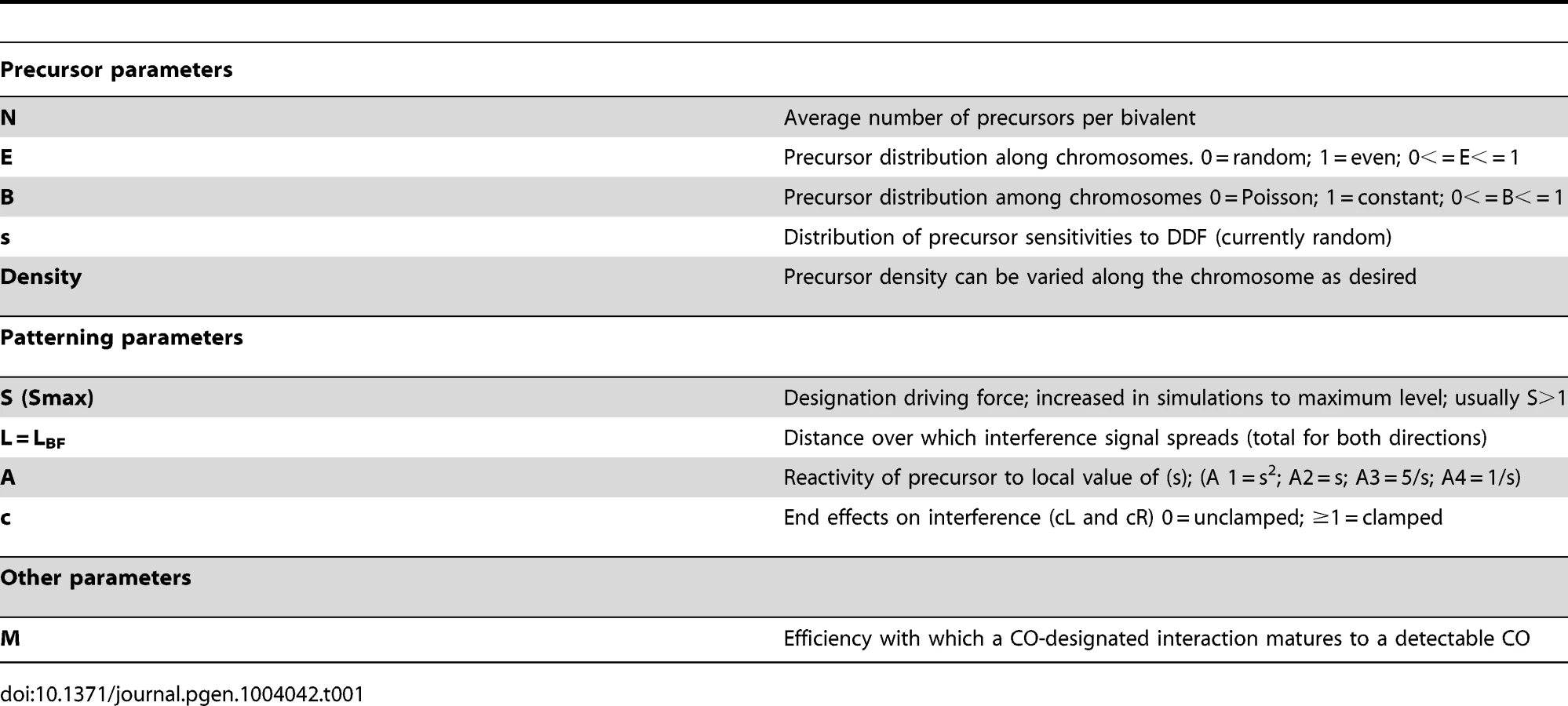
The precursor array
The precursors for CO patterning are generally assumed to be the total array of double strand break (DSB)-initiated interactions between homologs. Several BF parameters describe the nature of this array. (N) specifies the average number of precursors per bivalent. (E) specifies the extent to which the precursors along a given bivalent are evenly or randomly spaced. (B) specifies the extent to which precursors occur at a constant value along a given bivalent in different meiotic nuclei or are randomly (Poisson) distributed among different nuclei. Also, different precursors will naturally exhibit a range of intrinsic sensitivities to the DDF. The parameter(s) specifies the distribution of those sensitivities as specified by the Matlab function “rand”.
The original BF model included (N) and (s) and assumed a given chromosome has the same number of precursors in different nuclei but assumed that precursors are distributed randomly along a given chromosome (B = 1, E = 0). The latter assumption is likely not the case in vivo. Experimental evidence in several organisms shows that precursors tend to be evenly spaced, sometimes dramatically (e.g. [10]–[14]). And anecdotal evidence further suggests that the number of precursors tends to be quite constant for a given bivalent in different nuclei (e.g. [10], [12], [15], [16]). We further note that evenly-spaced precursors have not been taken into account in any previous quantitative model for CO patterning (e.g. [17]–[20]). Variations in the nature of the precursor array can affect CoC relationships, with interactive effects, particularly at low values of (N) (Figure 3ABC; Figure S2).

The BF simulation program now also includes a feature which permits the density of precursors to be varied along the chromosome in a desired pattern. This feature is useful for modeling effects such as the paucity of DSBs in centromeric regions, or other regional and domainal variations in DSB levels along chromosomes (e.g. [5], [6], [10], [21]–[26]). Application to grasshopper CO patterns is described below.
The BF model assumes that precursors do not turn over, i.e. that a precursor either develops into a CO or into some other type of product, without being recycled to serve again as a precursor in another position. This assumption has not been directly tested. However, it seems reasonable because precursors are known to be highly evolved multi-protein complexes whose numbers can be constant over long periods of time (e.g. [12]).
The BF model also assumes that the entire precursor array is established prior to CO-designation (or essentially so). This is clearly true in some organisms (e.g. [12]). It is not so clear in other organisms, where different regions of the genome can be at significantly different stages within a single nucleus (e.g. [27]). However, BF simulations will still pertain in the latter case if the effects of CO-designation at earlier-evolved positions can be “stored” within the chromosomes and exert their effects upon nearby positions when the appropriate precursors do finally evolve.
Finally, it has sometimes been considered that CO patterns evolve in two stages (e.g. [11], [15]). In such a case, one round of event-designation is imposed on total DSB-mediated interactions, giving a set of intermediate designated sites. That intermediate set then undergoes a second round of designation. BF simulations can directly model this situation. DSB-mediated interactions are used as a first set of precursors for a first simulation to give the intermediate array of events. That intermediate array is then used as a second set of precursors for a second simulation. The predicted outcomes from one - and two-round scenarios for recombination-related markers in Sordaria meiosis are presented elsewhere. A useful feature in distinguishing between the two scenarios is whether closely-spaced COs ever do, or do not, occur at the specific spacing characteristic of the first precursor array. If COs arise in a single step, closely-spaced events can occur at the positions of adjacent precursors. If COs arise in two steps, then this will not occur; instead, closely-spaced COs can only occur at the spacing of adjacent precursors in the intermediate array (Figure S3).
CO patterning parameters: DDF (S), interference distance (L), precursor reactivity (A) and end effects (cL, cR)
All of these patterning parameters are present in the original BF model. Detailed explanations of their significance are as follows:
(S,Smax) versus (L): The outcome of the patterning process is determined primarily by two basic parameters: the strength of the (CO)-designation driving force (global stress or the DDF), as given by parameter (S); and the distance over which interference spreads, given by parameter (L).
For simulation purposes, the value of (S) is progressively increased to a specified maximum (Smax). A first, most reactive, precursor goes critical to give a CO-designation with accompanying interference; the level of (S) is then further increased, giving a next designation at the next most reactive position. This process is increased up to a final desired level. This procedure gives sequential CO-designations. The higher the final maximum value, (Smax), the more CO-designations. Interference arises instantaneously after each designation, reducing the probability that affected precursors can respond to the driving force over the specified distance (L).
The final overall pattern of COs reflects the balance between the CO-designation driving force (DDF) and the interference distance, i.e. the values of (Smax) and (L). Correspondingly, a change in the value of either parameter can confer a similar alteration in CoC relationships and the ED (Figure 4AB). Higher (Smax) or lower (L) permits more COs to occur at shorter inter-interval distances, thus shifting the CoC curve to the left. Concomitantly, the overall level of COs increases. Lower (Smax) or higher (L) has the opposite effects. The ED changes commensurately.

To a considerable extent, opposing variations in the two parameters can compensate for one another (Figure 4CD). Nonetheless, in most cases, the effects of variations in (L) and (Smax) can be distinguished. The primary target of (L) is inter-CO communication, with the number of COs affected as a secondary consequence. The primary target of the DDF (Smax) is the number of COs, not inter-CO communication, with inter-CO relationships affected as a secondary consequence. Correspondingly, variations in (L) primarily affect CoC relationships whereas variations in (Smax) primarily affect the ED (Figure 4CDEF). The practical implication for best-fit BF simulations is that the values of these two parameters can be specified independently (Figure S4).
We note that, in vivo, (S) and (Smax) could take a variety of forms. (i) The value of Smax could potentially be defined by the time available for CO-designation. Interestingly, in Drosophila, the presence of a structural chromosome heterozygosity (deletion or inversion) results in a delay in meiotic progression and an increase in the number of COs without loss of CO interference [28], [29]. This constellation of phenotypes could be modeled by an increase in Smax. (ii) CO designation could occur sequentially without any progressive increase in the DDF, simply because different precursor complexes will tend to undergo designations sooner or later in relation to their intrinsic reactivities, up to the maximum number specified by Smax.
Also: in the BF model, the strength of the interference signal decays exponentially with distance from the CO-designation site (Figure 1A) in accord with the way in which stress redistributes in the beam-film system upon which the mathematical expressions are based [3], [4] (Figure 1A legend). This decay relationship can be altered in the simulation program. However, we have found no need to do so thus far (e.g. below).
Finally, the value of (Smax) actually incorporates the combined effects of the driving force and the sensitivity of precursors to that force. Similarly, the value of (L) incorporates the combined effects of the strength of the interference signal (as it dissipates with distance) and the sensitivity of precursors to that signal. Put another way: any difference that can be modeled by a change in (Smax), or a change in (L) could, potentially, reflect a change either an actual change in the altered feature or a change in the ability of precursors to sense that feature. Other information must be brought to bear to distinguish the two types of effects.
(A): A third patterning parameter, (A), describes the dose/response relationship between precursor sensitivity (s) and the local stress/DDF level at the corresponding position (i.e. the value of s as modified by the effects of any interference signals that have emanated across that position). Parameter (A) can have one of four possible values. In two cases (A = 1, 2), reactivity varies directly with (s); in the other two cases (A = 3, 4), reactivity varies inversely with (s) (Table 1). Variations in (A) can affect CO patterns (Figure 5A).

Clamping: c(L) and c(R): Special considerations apply to interference at chromosome ends. These effects are incorporated into BF simulations by “clamping” parameters (cL and cR). In the absence of any other consideration, a terminal region will behave the same way as any other region of the chromosome with respect to its response to the DDF (Smax), the interference signal (L) and precursor reactivity (A). The interesting consequence of this effect, not regularly appreciated, is that there will automatically be intrinsic tendency for the ends to exhibit higher frequencies of COs, because these regions will be subjected to interference signals emanating in from only one direction (i.e. from internal regions of the chromosomes and not from regions “beyond” the end of the chromosome) (Figure 5B top). In a mechanical model, this “default” situation is achieved by “clamping” the end of the chromosome to some object. In BF simulations, clamping is defined by parameter (c), which can be specified individually at each chromosome end (cL and cR). The default case, fully clamped, is c = 1.
In a mechanical model, the chromosome end could alternatively be free in space, i.e. would be “unclamped”. Since such a free end cannot support stress, it would behave as if it already had experienced a CO, i.e. with an interference signal having spread inward. The result would be a decreased probability that COs will occur near that end. In this case, c = 0. Intermediate situations can also occur. Thus, c(L) and c(R) can take any value between 0 and 1.
As a practical matter, specification of (cL) and (cR) permits more accurate modeling of in vivo patterns where end effects are prominent. For example, many organisms exhibit a tendency for COs to occur near the ends of chromosomes whereas others do not. Such effects tend to emerge when chromosome ends are clamped (e.g. Figure 5B middle, bottom). [Notably, however, genetic variations that result in paucities or excesses of DSBs near ends (e.g. [6], [10], [21]–[26], [30]) should be modeled by variations in the precursor density (above) rather than as effects on interference].
Variations in (cL) and (cR) primarily affect the distribution of COs along the length of a bivalent but also have secondary effect on overall CoC and ED relationships (Figure 5BC).
Maturation efficiency (M)
A precursor that undergoes designation may not mature efficiently into the signal used to define designations experimentally. This situation, defined by the value of the parameter (M), occurs in diverse mutant situations. If maturation is less than 100% efficient, the initial array of CO-designated events undergoes random subtraction such that the final array of detected events reflects only a subset of the original designation array. Variations in (M) do not affect CO patterns. Since maturation efficiency only affects CO status after patterning is established, a decrease in (M) only shifts ED relationships to lower CO numbers, with no/little effect on CoC relationships (Figure 5D).
Part III. BF Simulations Accurately Describe Experimental Data Sets
Application of the BF model to an experimental data set permits the identification of a set of parameter values for which simulated CO patterns most closely match those observed experimentally (general strategy described and illustrated in Figure S4).
Best-fit simulation analysis for data sets from yeast, Drosophila, tomato and grasshopper demonstrates that the logic and mathematics of the BF model can describe experimental CO patterns with a high degree of quantitative accuracy. This conclusion is evident in descriptions of CoC and ED patterns as described in this section (III). Additional evidence is provided by applications and extensions of BF simulation analysis to CO homeostasis, the obligatory CO and non-interfering COs as described in sections IV–VI. Inspection of experimental CoC relationships has also provided new information regarding the metric of CO interference in tomato and the fact that interference spreads across centromere regions (in grasshopper, as previously described, and also in tomato and yeast).
Budding yeast
Yeast provides a favorable system for analysis of CO patterning in general, and for application and evaluations of BF modeling in particular, for several reasons. First, in this organism, the sites of patterned (“interfering”) COs are marked by foci of ZMM proteins Zip2 or Zip3 along pachytene chromosomes ([31]; Materials and Methods; Figure 6A). Zip2/3 foci mark CO sites very soon after they are designated (and independent of the two immediate downstream consequences of CO-designation, i.e. formation of the first known CO-specific DNA intermediate and nucleation of SC formation). Thus, effects of CO maturation defects on CO patterns are minimized. Second, the positions of these foci, and thus of CO-designations, can be determined along any specifically-marked chromosome to the resolution of fluorescence microscopy (e.g. Figure 6B). Also, Zip2/3 focus positions can be determined even in the absence of SC [31]. Third, the average number of Zip3 foci (COs) per bivalent varies over a significant range (e.g. Table 2). The lowest value described thus far, ∼2 for Chromosome III, is close to the number of COs seen in some other organisms (e.g. mouse or human or grasshopper) and thus provide appropriate models for such cases. At the highest values, ∼7, multiple foci (COs) occur quite evenly along the length of the chromosome, which is very useful for revealing general patterns. Fourth, analysis of chromosomes in hundreds of nuclei is readily achievable, thus readily providing sufficiently large data sets for both wild-type and diverse mutant cases. Correspondingly, CoC and ED relationships can be determined extremely accurately. For a given data set, CoC values at each inter-interval distance can vary over a significant range (Figure 6C). This variation is largely due to sampling variation because it is significantly reduced in BF simulation data sets that involve 5000 chromosomes rather than the 300 that usually comprises a typical data set. Despite this variation, which is present in all experimental data sets (below), the average CoC curve obtained from such an experiment is highly reproducible, as illustrated by the results of four independent experiments (Figure 6D–G).


Experimental CO patterns in wild-type SK1: We have defined Zip3 focus patterns along WT chromosomes III, IV and XV in the SK1 strain background. These chromosomes range in size from 330 to 1530 kb (Table 2). For CoC analysis, each chromosome was divided into 100 nm interval, a size that provides maximal accuracy (Figure S1). Inter-interval distances for CoC analysis are expressed in units of µm SC length (rationale above). The three analyzed chromosomes exhibit virtually overlapping CoC curves, with LCOC = ∼0.3 µm (Figure 6F; Table 2). Along a pachytene chromosome of SK1, this distance corresponds to ∼100 kb. The CoC curve remains less than 1 up to inter-interval distances corresponding to ∼150 kb, in accord with the maximal distance over which interference is detected by genetic analyses (e.g. [32]).
The value of Zip3 foci as a marker for CO patterns is further confirmed by analysis of an mlh1Δ mutant. Since Zip3 foci mark CO sites shortly after they are designated, and long before the late step at which Mlh1 is thought to act (above), the mlh1Δ mutation should not reduce total Zip3 focus levels and should have no effect on CoC relationships for Zip3 foci. This expectation is confirmed (Figure 6H).
BF analysis: CoC and ED data for all three analyzed chromosomes can be very closely matched by BF best-fit simulations (e.g. Figure 6I; best-fit simulations for SK1 Chromosome IV and III and for chromosome XIV in BR are shown in Figure S5 A–D; parameter values in Table 2). Points of note include:
-
Despite differences in absolute chromosome length, and numbers of Zip3 foci, all three chromosomes are described by the same set of optimal parameter values with the exception of the predicted number of precursors, which increases with chromosome length as could be expected (Table 2).
-
The thus-defined best-fit value of (L), i.e. the distance over which the inhibitory interference signal spreads, is ∼300 nm (LBF = ∼0.3 µm) for all analyzed chromosomes (Table 2). This value of (LBF) turns out to correspond closely to “interference distance” as defined experimentally by CoC analysis in all cases (LCOC = ∼0.3 µm; Table 2).
-
For each chromosome, the number of precursors used for the best-fit simulation corresponds well to that described experimentally by analysis of DSBs and is approximately proportional to chromosome length [21].
-
An optimal match between best-fit CoC curves and experimental data requires that precursors be relatively evenly spaced along the chromosomes (E = 0.6; (Figure 6IJ; Figure S5A–E), thus confirming and extending experimental evidence that yeast DSBs are evenly spaced (discussion in [13], [14]; see also below).
-
Notably, also, for the shortest chromosome (III), an optimal match is obtained only if precursors are also assumed to occur in a relatively constant number along a given chromosome in different nuclei (B = 1; Figure S5F). At lower values of B, the frequency of zero-Zip3 focus chromosomes is higher than that observed experimentally because a significant fraction of chromosomes fail to acquire enough precursors to give at least one focus. This finding suggests that a given chromosome usually acquires the same (or nearly the same) number of precursors in every meiotic nucleus. For longer chromosomes, the value of B is not very important (e.g. Figure 6K; further discussion below).
-
Zip3 focus analysis reveals that the shortest yeast chromosome (III) has a significant number of zero-event chromosomes (1%) whereas the two longer chromosomes have much lower numbers (no zero-focus chromosome has been detected among >1000 chromosomes analyzed) (e.g. Figure 6G). These values are recapitulated by BF simulations (Figure 6I; Figure S5EF; further discussion below).
The ability of BF simulations to accurately describe yeast data is further supported by analysis of CO homeostasis and the “obligatory CO” as described below.
Drosophila melanogaster
CO interference was first discovered, and CoC analysis developed, by genetic analysis of Drosophila X chromosome (Introduction). These classical genetic data do provide for a quantitatively accurate CoC curve with LCOC = ∼6 µm (Figure 7A), because the interval sizes are small enough and the data set is large enough [33]. The average number of COs per bivalent defined by experimental analysis is 1.44 with an unusually high level of zero-CO bivalents (5%) (Figure 7B). Recent studies of γ-His2Av foci have defined a total of ∼24 DSBs for the entire genome in Drosophila female meiosis [34]. Assuming that DSBs are proportional to genome length, this implies 6 DSBs for the X-chromosome (N = 6). A BF simulation with N = 6 can quantitatively match the classical Drosophila X chromosome data for all descriptors (Figure 7AB). Best-fit simulation requires differential clamping at the two ends, with less clamping at the centromeric end (Table 2). This feature provides for the experimentally-observed tendency for CO distributions to be shifted away from that end (illustrated in [35]).

The ability of BF simulations to accurately describe Drosophila data is further supported by analysis of CO homeostasis and the “obligatory CO” as described below.
Chorthippus bruneus (grasshopper)
CO sites along the L3 bivalent of grasshopper have been defined by analysis of chiasmata in 1466 diplotene nuclei [36], [37]. These data yield a CoC curve with LCoC = 28 µm and an ED with an average of 2.2 COs/bivalent and no detected zero-CO chromosomes (<0.07%; Figure 8A).

A prominent feature of the L3 bivalent is a severe paucity of COs in the centromere region (Figure 8B left panel). This feature presumably reflects a defect in occurrence of precursors (DSBs) in centromeric heterochromatin. Thus, for BF best-fit simulations, the precursor array was adjusted accordingly, to give a strong paucity of precursors in the centromere region (a “black hole”; Figure 8B left; C).
BF best-fit simulations can accurately describe L3 CoC and ED relationships, with or without inclusion of the black hole (Figure 8D, E); however, inclusion of the centromere precursor defect dramatically improves CO distributions along the chromosome, not only for total COs but for bivalents with two or three COs (Figure 8F versus 8G). Unlike all of the other cases analyzed above, there is no information for grasshopper regarding the number of precursors per bivalent. In BF simulations, the best fit between experimental and simulated data sets is provided when N = ∼14 (Figure 8H).
Solanum lycopersicum (tomato)
CO patterns in tomato have been defined by analysis of Mlh1 foci ([38]; Lhuissier F.G. personal communication). Chromosomes in this organism exhibit a range of different pachytene bivalent lengths [38]. Bivalents comprise two groups, chromosomes 2–4 and 5–11, on the basis of longer and shorter SC lengths respectively (Figure S6A). We find that experimental CoC curves are significantly offset for the two groups when the metric of inter-interval distance is Mb (Figure 9A); in contrast, CoC curves for the two groups are superimposable when inter-interval distance is µm SC length (physical distance), with LCoC = 11 µm (Figure 9B).

Physical distance has shown to be the appropriate metric for CO interference in mouse and Arabidopsis (above). The experimental results for tomato described above (Figure 9 AB) imply that this is also true in tomato. In addition, these data imply that the ratio of Mb to µm SC length is higher for shorter chromosomes than for longer chromosomes. This difference is explained, quantitatively, by two facts that: (i) heterochromatic DNA is much more densely packed along the SC than euchromatin and (ii) shorter chromosomes have a higher proportion of heterochromatin than euchromatin (and thus shorter SC lengths) (Figure S6).
CoC and ED patterns for both groups of chromosomes are well-described by BF simulations (Figure 9CD). All parameters have the same values in both cases, including the interference distance (L) when expressed in µm SC length, except that precursor number varies with CO number/SC length (Figure 9CD legend).
Interference spans centromeres in grasshopper, yeast and tomato
Previous analyses of interference have shown that CO interference is transmitted across centromeric regions [6], [37]–[42]. Correspondingly, CoC values for interval pairs that span centromeres are almost indistinguishable from those for pairs separated by the same distances that do not span centromeres (Figure 10B). This is remarkable given the manifestly different structure in these regions. We further find that the same is true for budding yeast, based on Zip3 focus analysis (Figure 10A) and for tomato, from Mlh1 focus analysis (Figure 10C).

Part IV. CO Homeostasis
Experimental evidence has revealed that variations in the level of recombination-initiating double-strand breaks (DSBs) are not accompanied by corresponding variations in the number of COs. When DSB levels are either reduced or increased, CO levels are not reduced or increased commensurately [15], [34], [43]–[46]. This phenomenon is referred to as CO homeostasis [43].
According to the BF model, CO homeostasis is dependent upon, and in fact is a direct consequence of, CO interference (Figure 11A), as proposed [43], [46]. In the absence of interference, the probability that a precursor will give rise to a CO is a function only of its own intrinsic properties, independent of the presence/absence of other precursors nearby. Thus, as the number of precursors decreases, the number of COs will decrease proportionately. In contrast, if interference is present, each individual precursor is subject to interference that emanates across its position from CO-designation events at neighboring positions. The lower the number of precursors, the less this effect will be. Thus, assuming a fixed level of CO interference, the frequency of COs per precursor will increase as the number of precursors decrease. Put another way: as the density of precursors decreases, the ratio of COs to precursors increases, even though there is no change in CO interference. Importantly, since CO homeostasis requires CO interference, its magnitude will also depend on the strength of CO interference as discussed below.

In the BF model, CO homeostasis involves interplay between N and patterning parameters, e.g. L and Smax
CO homeostasis for a given condition can be defined quantitatively by BF simulations in which the value of N (which is the number of precursors per bivalent and thus corresponds to precursor density) is varied, with all other parameter values remaining constant. Homeostasis can be described by plotting, as function of (N), either the frequency of COs per precursor (CO/N) or the total number of COs per bivalent (which corresponds to CO density) (Figure 11BC). Alternatively, CO homeostasis can be seen from the perspective of a starting wild-type situation with the number of COs per bivalent at the wild type precursor level taken as the point of reference and variations in the number of COs and precursors expressed relative to those reference values (Figure 11D).
The magnitude of CO homeostasis, i.e. the extent to which CO levels fail to respond to changes in precursor levels, will vary with the level of CO interference (above). This relationship can be described quantitatively by carrying out simulations for different values of (N) at different values of patterning parameter(s), illustrated here for variations in the interference distance (L) (Figures 11B–D). In the absence of interference, CO levels vary directly with precursor levels; the greater the interference distance, the less the change in CO levels with precursor levels. Notably, at very long interference distances, CO levels do not change at all with precursor levels. This is basically because interference precludes CO-designation at all other precursor sites, thus rendering variations in CO density irrelevant. This latter situation has recently been documented for C.elegans [44], [45]. Analogous effects can be seen for variations in Smax (not shown), in accord with the fact that both L and Smax play important roles for LCoC (above).
BF simulations of CO homeostasis in experimental data sets can be used to evaluate the validity of the BF model
BF best-fit simulations for wild type experimental data sets provide specific predicted values of all BF parameters, including N, L and Smax (above). Given this starting point, BF simulations can then specifically predict how CO levels will vary if the level of DSBs (precursors) is decreased or increased. If the BF model accurately describes CO patterning, the best-fit simulation will accurately describe the experimental data. Application of this approach to budding yeast and Drosophila shows that the BF model can quantitatively predict experimental CO homeostasis patterns in both organisms.
The BF model quantitatively describes CO homeostasis in yeast: We asked whether the BF model could quantitatively explain CO homeostasis along chromosomes XV and III as defined by Zip3 focus analysis (above). We determined experimentally the number of Zip3 foci that occur along the two test chromosomes in a series of mutants that are known to exhibit particular, defined decreases or increases in DSB levels. Reductions in DSB levels were provided by the hypomorphic alleles of DSB transesterase Spo11 used to originally define CO homeostasis [43]. An increase in DSB levels was provided by a tel1D mutation, which increases DSB levels without significantly altering CO interference ([13]; unpublished). The observed experimental relationships are described by the BF-predicted relationships (Figures 12AB, L = 0.3 µm).
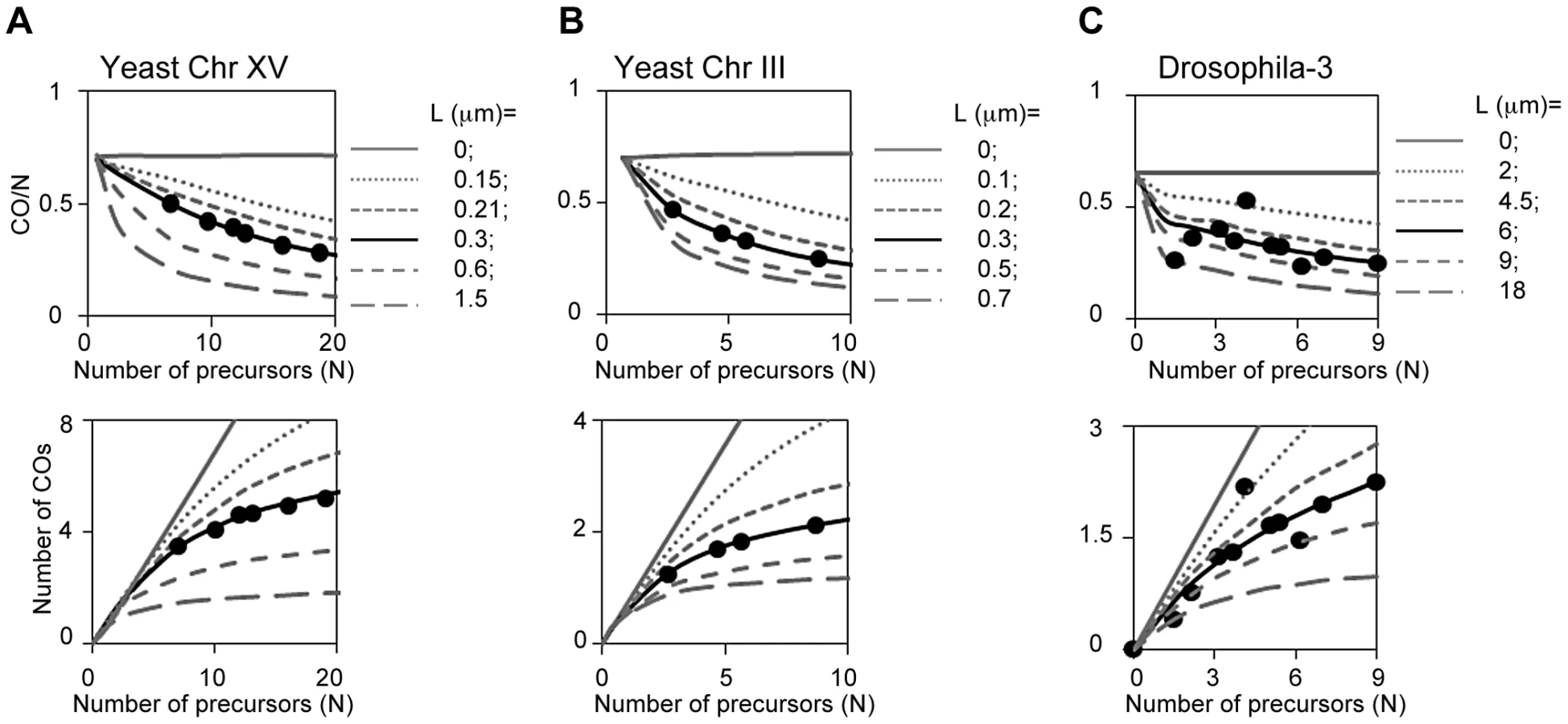
The robustness of BF simulations is further supported by analysis of CoC and ED relationships for Zip3 foci in each of the DSB mutant strains. Best-fit simulations of these data sets should occur at exactly the same values of all parameters except for the number of precursors (N), which should match that defined by experimental analysis of DSBs. Both of these predictions are fulfilled (Figure S7). These comparisons also reveal some interesting subtleties to DSB formation in the mutants (Figure S7).
The BF model quantitatively explains CO homeostasis in Drosophila: We analogously evaluated whether BF simulations accurately predict CO homeostasis relationships in Drosophila, which were defined experimentally by analysis of a fragment of chromosome 3 [34]. In Drosophila, as in yeast, CO-versus-DSB experimental data exhibit a very good match to the CO-versus-(N) relationships predicted using BF best-fit parameter values, uniquely and specifically at the best-fit value of (L) (Figure 12C).
BF simulations should (and do) accurately predict CO homeostasis in interference-defective mutants: CO homeostasis relationships should be altered in mutants where interference is defective, in a predictable way according to the magnitude of the reduction (Figure 12ABC, grey lines above the curves describing the wild-type relationships). We will present elsewhere data showing that BF best-fit simulations for a yeast mutant specifically defective in interference accurately predict CO homeostasis relationships in that mutant, thus further supporting the validity of BF simulation analysis.
The strength of CO homeostasis reflects the ratio of inter-precursor distance and interference distance (LCoC)
It would be convenient to have a standard way of comparing different situations (e.g. different chromosomes, mutants or organisms) with respect to the “strength” of CO homeostasis. In principle, the strength of homeostasis should vary according to the ratio between the CO interference distance (LCoC) and the distance between adjacent precursors (roughly given by the number of precursors divided by µm SC length). If this ratio is higher homeostasis will be stronger because a greater fraction of precursors are within the interference distance and thus can be eliminated without effect; and in the limit, reduction of precursor density will have no effect whatsoever. Oppositely, if this ratio is lower; homeostasis will be weaker because a greater fraction of precursors are outside of the interference distance and thus, when eliminated, will directly reduce CO levels; and in the limit, when the interference distance is zero, CO homeostasis is absent. By this criterion, i.e. [LCOC/average inter-precursor distance from the data in Table 2], the strength of CO homeostasis is the same for all yeast chromosomes (0.3 µm/0.3 µm = 1); are essentially the same for yeast chromosomes as for the Drosophila X chromosome (6 µm/5 µm = 1.1); is significantly greater for grasshopper (28 µm/2.6 µm = 10.8); and is even greater for tomato chromosomes, both groups (11 µm/0.888 µm = 12.5). Systematic exploration of such relationships by BF simulations remains for future studies.
Part V. The “Obligatory CO”
Regular segregation of homologs to opposite poles at the first meiotic division requires that they be physically connected. During meiosis in all organisms, in at least one sex and usually both, the requisite physical connection is provided by the combined effects of a crossover between non-sister chromatids of homologs and connections between sister chromatids along the chromosome arms. Correspondingly, in such organisms, in wild-type meiosis, every bivalent almost always acquires at least one CO [47]. This first CO that is essential for homolog segregation is often referred to as the “obligatory CO”. In fact, the obligatory CO is simply a biological imperative: the level of zero-CO chromosomes should be low. The CO patterning process, by whatever mechanism, must somehow explain this feature.
In most situations, the frequency of zero-CO bivalents is extremely low (<10−3), but higher frequencies also occur in certain wild-type situations as well as in certain mutants (below). In some models for CO patterning, the obligatory CO is ensured by a specific “added” feature of the patterning process (e.g. the King and Mortimer model; Discussion). In contrast, in the beam-film model, the requirement for one CO per bivalent is satisfied as an intrinsic consequence of the basic functioning of the process, as follows.
In the BF model, the “obligatory CO” is independent of (L) and (E) and requires an appropriate combination of values for (Smax), (N), (B) and (M)
In the BF model, the obligatory CO is ensured as an intrinsic consequence of all of the features that ensure occurrence of a first event; features that act later in the process are not relevant (Figure 13A).

L and E: Variations in (L) and (E) have no effect on the level of zero-CO chromosomes because: (i) spreading inhibition of CO-designation (“interference”) only affects the number of COs after the first CO designation; and (ii) the distribution of multiple events along a chromosome also comes into play only after the first designation event has occurred. In contrast, essentially all other basic BF parameters are important in ensuring a low level of zero-CO chromosomes:
Smax, N and B: The frequency of zero-CO chromosomes will be minimized if every chromosome has at least one precursor that is adequately sensitive to the DDF. This effect can be favored by either (i) higher Smax; (ii) higher N; or (iii) higher B. Higher Smax means that a higher fraction of sites in a particular precursor array will be adequately sensitive. Higher N means that there will be more sites and there is a higher chance that an adequately-sensitive precursor will be present. Higher B means a reduced probability that a bivalent will have a lower-than-average number of precursors and thus a lower-than-average chance for an adequately-sensitive precursor to be present.
(M): Even if the CO patterning process ensures the occurrence of at least one CO per chromosome, a defect in maturation of CO-designated interactions to detectable COs will tend to counteract that effect, converting chromosomes with one (or a few) COs to chromosomes with zero-COs.
(A): The more likely a precursor is to give a CO-designation in response to a particular local level of interference, the lower will be the frequency of zero-CO chromosomes. The frequency of zero-CO chromosomes is lowest for A = 4 and increases progressively for A = 3, 2 and 1 (not shown).
Evolutionary implications
The above considerations imply that, according to the BF model, the “obligatory CO requirement” will be met in any given organism because the relevant features have been coordinately tuned by evolution into a combination that ensures a low level of zero-CO chromosomes. That is: a suitably low level of zero-CO chromosomes can be achieved by a variety of combinations, with more and less favorable values of different parameters in different cases. Interplay between pairs of parameters is illustrated for various combinations of (Smax) and (N) (Figure 13B) and for various combinations of (N) and (B) (Figure 13C). The lower the number of precursors, (N), the higher the Smax needed to ensure that at least one will be sensitive enough to undergo CO designation and the more important it will be for precursors to occur in a constant level along the bivalent in every nucleus (higher B).
Application to experimental data: When the obligatory CO appears to be “missing”, in wild-type meiosis
In most organisms, for most chromosomes, in wild-type meiosis the observed frequency of zero-CO chromosomes is <0.1% (e.g. Table 1). However, zero-CO chromosomes occur at significantly higher levels on the Drosophila X chromosome (5%) and on yeast chromosome III (1% by Zip3 foci).
Yeast: the importance of N: BF analysis suggests that, in yeast, the feature responsible for the high level of zero-Zip3 focus chromosomes along chromosome III is simply a paucity of precursors and thus is a function of its diminutive size, per se. In this organism, patterns on all analyzed chromosomes can be described by the same set of BF parameters with the exception of (N), which varies roughly in proportion to chromosome length as defined in µm SC (above). The high level of zero-Zip3 focus chromosomes along chromosome III, relative to other chromosomes, is thus solely a reflection of the fact that it is much shorter than other chromosomes (N = 6 versus N≥13; Table 2). This conclusion is directly and strongly supported by experimental analysis of Zip3 foci along chromosome III in mutants where precursor levels are gradually decreased or increased (by alterations in DSB levels; described below). In such mutants, the frequencies of zero-Zip3 focus chromosomes are commensurately increased or decreased. In mutants with relative DSB levels of 1.5, 1 (WT), 0.8 and 0.7, the frequencies of zero-CO chromosomes are, respectively, <0.003; 0.01; 0.02; and 0.08 (Figure S7B).
Analysis of yeast chromosome III further shows that the best-fit simulation requires that precursors occur in a constant number per bivalent in all nuclei (B = 1; frequency of zero-Zip3 focus bivalents = 0.01). If precursors are Poisson distributed among bivalents in different nuclei (B = 0), the frequency of zero-Zip3 focus bivalents increases to 0.04 (Figure S5). This comparison not only suggests that DSBs/precursors always occur at the same number along a different chromosome but provide a rationale for the existence of this feature which, in the general case, is essential to minimize the frequency of zero-CO bivalents along short chromosomes.
Drosophila X chromosome: The high level of zero-CO bivalents for the Drosophila X chromosome is recapitulated in BF simulations without adding any unusual features (Figure 7B), suggesting that there is nothing remarkable about this chromosome. Further, this chromosome the same number of precursors as yeast chromosome III (N = 6), suggesting that here, too, the fact that the chromosome is “too short” could be an important factor for the high level of zero-CO chromosomes. In accord with this possibility, Drosophila chromosome 3 is 50% longer than chromosome X; and BF simulation analysis shows that if X chromosome length is increased by 50%, with a proportional increase in precursors (to N = 9), and without any change in any other parameter, the frequency of zero-CO would decrease to 0.008.
However: the number of precursors cannot be the only relevant feature, because the level of zero-CO chromosomes in Drosophila is higher than that for yeast chromosome III even though they both have N = 6. This difference could be attributable in part to less regular distribution of precursors among chromosomes in Drosophila (B = 0.5 versus B = 1 in yeast) and to a lower DDF level (Smax = 2.8 versus 3.5 in yeast [Table 2]).
Implications: The general implication of these considerations is that CO patterning features have evolved to give a very low level of zero-CO bivalents, in accord with the biological imperative. However, in certain organisms, the constellation of features may be tuned to just such a level that the number of precursors along shorter chromosomes is just at the limit of the necessary threshold.
Notably, also, in both Drosophila and yeast, additional mechanisms exist which complement the patterned CO system to ensure regular homolog segregation. Drosophila exhibits robust CO-independent segregation [48] and, in budding yeast, the significant level of non-interfering COs also ensure disjunction. For example: 1% of chromosome III's exhibit zero Zip3 foci whereas only 0.1% of chromosome IIIs exhibit no COs as defined genetically (Hunter N and Bishop D, personal communication).
Application to experimental data: When the obligatory CO appears to be “missing” in mutant meiosis
Mutant phenotypes that affect interference and/or the “obligatory CO” could fall into three different categories [47]:
IF − OC+: The BF model predicts that mutants with decreased CO interference, as defined specifically by decreased L, will show no defect in formation of the first (obligatory) CO, i.e. will show the same level of zero-CO chromosomes as that seen in WT meiosis. This phenotype, “IF − OC+”, not previously reported, is now described by observations in yeast to be presented elsewhere.
IF+ OC−: In certain mutants, the level of zero-CO bivalents is increased but interference is unaltered. In the context of the BF model, this phenotype could arise from several types of defects. For example: this phenotype is expected for mutants with altered recombination biochemistry such that CO designation is normal but CO maturation is inefficient, i.e. M<1 (Figure 5A). For example, mutants lacking Mlh1 exhibit reduced levels of COs and significant levels of zero-CO chromosomes but relatively normal CO interference, as shown by genetic/chiasma analysis for several organisms [49]–[51]. On the other hand, by Zip3 focus analysis, both CoC and ED in a yeast mlh1Δ are essentially the same as in WT (Figure 6H), implying that CO-designation is normal. Thus the obligatory CO defect seen by genetic/chiasma analysis is specifically attributable to a maturation defect (M<1). Correspondingly, there are multiple indications that Mlh1 acts very late in recombination, for maturation of dHJs to COs [50], [51].
This phenotype could also be conferred by genetic shortening of a chromosome. A reduction in the Mb length of the chromosome will decrease the precursor number (N) without alternation of any other properties and thus could push N below the minimum necessary threshold. Such an effect could explain the high level of zero-CO chromosomes seen when plant chromosomes are shortened by centric fission [47] and when yeast chromosome III is reduced in length (Hunter N., and Bishop, D.K., personal communication).
IF − OC−: This phenotype could be conferred in several ways. One example would be a defect early in the recombination process that eliminate the ability of recombination precursors to both generate COs and generate/respond to the CO interference signal.
Implications: The existence of IF+ OC − mutants has sometimes been cited as evidence for the existence of a specific feature, separate from interference, that “ensures the obligatory CO”. The existence of IF − OC − mutants has sometimes been cited as evidence that interference is required for the “obligatory CO”. Both of these phenotypes have alternative explanations in the context of the beam-film model. In contrast, the existence of IF − OC+ mutants is specifically predicted by the beam-film model.
Part VI. Non-interfering COs
In some organisms, a significant fraction of COs arises outside of the patterning process. The existence of these “non-interfering” COs is most rigorously documented for budding yeast, where the number of “non-interfering” COs is ∼30% among total COs (by compassion the number of patterned COs defined by analysis of CO-correlated Zip2/Zip3 foci with the number of total COs from genetic and microarray analyses) (e.g. [22], [31], [52], [53]; below).
The origin of non-interfering COs is unknown. One possibility is that they arise from the majority subset of interactions that do not undergo CO-designation [5]. By this model (“Scenario 1”; Figure 14A left), not-CO-designated interactions would mostly mature to NCOs but sometimes would mature to COs, analogously to the situation in mitotic DSB-initiated recombinational repair [54]. Alternatively, such COs might arise from some other set of DSBs that arise outside of the normal process, e.g. because they occur later in prophase after CO-designation is completed or earlier in prophase before patterning conditions are established (“Scenario 2”; Figure 14A right).

Both scenarios can be examined using the BF simulation program. To simulate the outcome of Scenario 1, where non-patterned COs arise from non-designated interactions left over after patterning, a standard CO-designation BF simulation is performed to define the interfering COs; the precursors that have not undergone CO-designation are then used as the starting array of precursors for a second round of CO-designation. In this second round, COs are randomly selected from among the precursors remaining after the first round of designation. The COs resulting from the two simulations are then combined and the total pattern is analyzed.
To model Scenario 2, in which non-patterned COs arise from an unrelated set of precursors, a standard CO-designation BF simulation is performed to define interfering COs. Then a second, independent simulation is performed using a specified number of precursors that are unrelated to the first set and random selection of COs from among that precursor set. COs generated by the two types of simulations are then again combined and analyzed.
CoC relationships for total COs (interfering plus non-interfering) will depend significantly on whether the precursors that give rise to the “non-interfering” COs are evenly or randomly spaced along the chromosomes. CoC curves for total COs reflect the combined inputs of CoC relationships for interfering COs and non-interfering COs. CoC curves for interfering COs are affected only modestly by even-versus-random spacing due to the overriding effects of CO interference (above; e.g. Figure 14B left). However, non-interfering CO relationships are a direct reflection of precursor relationships, which differ dramatically in the two cases. For precursors, CoC = 1 for random spacing and significant “interference” for even spacing; Figure 14B second from left). CoC relationships for non-interfering COs alone exhibit the same features (Figure 14B, rightmost two panels). These differences are directly visible in CoC curves for total COs, with greater or lesser prominence according to the relative abundance of non-interfering COs versus interfering COs (Figure 14C). Notably, CoC relationships for Scenario 1, where precursors exhibit the even spacing defined by BF best-fit simulations (E = 0.6), show a qualitatively different shape than CoC relationships under Scenario 2.
Given this framework, we defined CoC curves for total COs along yeast chromosomes IV and XV as defined by microarray analysis (Figure 14D left panel). The general shapes of these experimental curves correspond qualitatively to those predicted for emergence of non-interfering COs from an evenly-spaced precursor array, with a closer correspondence to those predicted for Scenario 1 than to those predicted for Scenario 2 (compare Figure 14D left panel with Figure 14C).
This impression is further supported by BF simulations. To model Scenario 1, we began with the set of best-fit parameters defined for interfering COs (Zip3 foci) above (Figure 6I) and generated predicted total CoC curves, assuming that non-interfering COs comprise 30% of the total (above), for each of the three possible case of non-interfering COs: Scenario 1 (where precursors are assumed to be evenly spaced as for interfering COs); and Scenario 2 with precursors assumed to be either evenly or randomly spaced (Figure 14D, second panel from left). The CoC curve for the first of these three cases has the same shape as the experimental CoC curves for total COs (compare Figure 14D left and second from left panels) and direct comparison shows that it gives a quite good quantitative match with the experimental curves (Figure 14D third panel from left). Scenario 2 with evenly-spaced precursors is a less good match (Figure 14D, right panel). Scenario 2 with randomly-spaced precursors (Figure 14D, second panel from left, red) is a quite poor match (not shown).
These analyses suggest that, in yeast, non-interfering COs arise from the not-CO-designated precursors as a minority outcome of the “NCO” default pathway (Figure 14A, Scenario 1).
Part VII. Variations in Diverse BF Parameters Alter the Value of the Gamma Shape Parameter
Many studies of CO interference characterize CO patterns by defining a gamma distribution that best describes an experimentally observed distribution of the distances between adjacent COs, often with the assumption (implicit or explicit) that a higher value of the gamma shape parameter (ν) corresponds to “stronger” CO interference (e.g. [11]). We have examined the way in which (ν) varies as a function of changes in the values of several BF parameters. Variations in L or Smax increase or decrease the value of (ν) in correlation with increased or decreased LCOC and in opposition to the average number of COs per bivalent (Figure 15AB, compare green line and blue/pink distributions with red and black lines). This is the pattern expected for a change in the “strength of interference”. In contrast, the value of (ν) is also altered by variations in M or N, which have little or no effect on LCOC; moreover, the change in (ν) co-varies with the change in the average number of COs per bivalent (Figure 15CD, compare green line and blue/pink distributions with red and black lines). The BF model thus implies that a change in the value of (ν), e.g. in a mutant as compared to wild type, may or may not imply a change in the patterning process per se. However, comparison of the variation in (ν) with the variation in average COs per bivalent can distinguish between the two possibilities, with opposing variation implying a patterning difference and co-variation implying a difference in some other feature.

Discussion
The presented analysis has provided new information on CO patterning from several different perspectives.
BF Simulations Accurately, Quantitatively Describe Experimental Data Sets
This is true not only with respect to CoC and ED relationships but with respect to more detailed effects such as CO homeostasis and the obligatory CO. These matches, and the information that emerges there-from, support the notion that the basic logic of the BF model provides a robust and useful way of thinking about CO patterning. These matches are also specifically supportive of the proposed mechanical stress-and-stress relief mechanism.
New Information about CO Patterning in Several Organisms
In budding yeast: (i) CO patterning has the same basic features for shorter and longer chromosomes; (ii) Mlh1 is required specifically for CO maturation not for CO patterning; and (iii) Precursors are evenly spaced, as shown by both CoC analysis and analysis of total (interfering-plus-non-interfering) COs.
In tomato (and, to be described elsewhere, in budding yeast), the metric of CO interference is physical chromosome length (µm) not genomic length (Mb). In the case of tomato, differences in CoC relationships expressed in the two different metrics is attributable to differential packaging of heterochromatin versus euchromatin along the chromosome plus differential proportions of heterochromatic versus euchromatic regions among different chromosomes.
In tomato and yeast, as previously described for grasshopper, human and several other organisms, crossover interference spreads across centromeres with the same metric as along chromosome arms.
In budding yeast, non-interfering COs arise from evenly-spaced precursors, most probably by occasional resolution of NCO-fated precursors to the CO fate.
New Insights into CO Homeostasis and the “Obligatory CO”
With respect to CO homeostasis, the importance of CO interference as a determinant in the strength of homeostasis is emphasized and BF simulations are shown to permit accurate quantitative descriptions of homeostasis. Also, the strength of homeostasis can be seen to reflect the ratio of interference distance (LCoC) to the distance between adjacent precursors.
With respect to the obligatory CO, the general logic of the BF model (Figure 1) suggests that occurrence of a low level of zero-CO chromosomes is independent of CO interference (and precursor spacing) and is achieved by an appropriate evolved constellation of all other parameters. Explanations can also be provided for several known cases where the level of zero-CO chromosomes is unusually high, but interference is robust, and potential explanations for other mutant phenotypes are suggested. Importantly, the logic of the beam-film model predicts the existence of mutants that lack interference but still exhibit the obligatory CO, evidence for which will be presented elsewhere.
Models and Mechanisms of CO Interference
The central issue for CO patterning is how information is communicated along the chromosomes. Three general types of mechanisms have been envisioned. (1) A molecular signal spreads along the chromosomes, e.g. as in the polymerization model of King and Mortimer [55] or the “counting model” of Stahl and colleagues [20], [35]. (2) A biochemical reaction/diffusion process surfs along the chromosomes [56], as recently described in detail for bacterial systems [57], [58]. (3) Communication occurs via redistribution of mechanical stress, as in the beam-film model [3], [4] or via other mechanical mechanisms (e.g. [59]).
The counting model can provide good explanations of experimental data; however, the underlying mechanism is contradicted by experimental findings ([43]; but see [60]). No specific reaction/diffusion mechanism has been suggested thus far for CO interference. The King and Mortimer model and the beam-film model are significantly different, in three respects. First, in the King and Mortimer model, the final array of COs reflects the relative rates of CO-designation and polymerization. Thus it is the kinetics of the system that governs its outcome. In the beam-film model, where interference arises immediately after each CO-designation, kinetics does not play a role. Second, in the King and Mortimer model, the interference signal continues to spread until it runs into another signal approaching from the opposite direction. In the beam-film model, the interference signal is nucleated and spreads for an intrinsically limited distance, with an intrinsic tendency to dissipate with distance from its nucleation site. Third, the King and Mortimer model envisioned that precursors were Poisson distributed among chromosomes. As a result, significant numbers of chromosomes would initially acquire no precursors if the average number of precursors is low and thus would never give a CO, thereby giving an unacceptably high level of zero-CO chromosomes. To compensate for this effect, the model proposed that the effect of interference was to release encountered precursors, which then rebound in regions that were not yet affected by interference (and thus on chromosomes with no precursors). This precursor turnover would ensure that all chromosomes achieved a precursor that could ultimately give a CO. Because of this feature, the King and Mortimer model envisions that interference is required to ensure a low level of zero-CO chromosomes (i.e. to ensure the “obligatory CO”). By the beam-film model, instead, precursors do not turn over and interference is not required to ensure a low level of zero-CO chromosomes, which results instead from an appropriate constellation of other features, as described above. The beam-film model predicts the existence of mutants that are defective in interference but do not exhibit an increase in the frequency of zero-CO chromosomes.
Materials and Methods
Yeast Strains
Yeasts SK1 strains (Figure 6 and S7) are described in Table S1. In all strains, ZIP3 carries a MYC epitope tag; a construct expressing LacI-GFP and is integrated at either LEU2 or URA3, and a lacO array [61] is inserted at HMR (chromosome III), Scp1 (Chromosome XV) or Chromosome IV telomere (SGD1522198) to specifically label each chromosomes by binding of LacI-GFP.
Zip2/Zip3 Foci on Yeast Pachytene Chromosomes Correspond to Programmed (“Interfering”) COs
Pachytene chromosomes exhibit ∼65 foci of Zip2, Zip3 and Msh4, with strong colocalization of Zip3 and Msh4 foci ([31], [62]; this work). Zip2 foci [63] exhibit interference as defined by CoC relationships for random adjacent pairs of intervals [31]. We further show here that Zip2 and Zip3 foci exhibit interference as defined by full CoC relationships along specific individual chromosomes (Figure 6 and Figure S5). Zip2 and Zip3 foci also both occur specifically on association sites of zip1Δ chromosomes [31], [64]. The total number of COs per yeast nucleus as defined by microarray and genetic analysis is ∼90 [22], [52], [65] implying that Zip2/Zip3/Msh4 foci represent 65/90 = 70% of the total. Correspondingly, mutant analysis suggests that “non-interfering” COs comprise ∼30% of total COs (e.g. [50]). Additionally, BF analysis accurately explains CoC relationships for total COs on the assumption of 70% patterned COs and 30% “non-interfering” COs (Figure 14, Results).
Cytological Mapping Zip3 Foci in Yeast
Synchronous meiotic cultures (SPS sporulation procedure from [66]) were prepared and harvested at a time when pachytene nuclei are most abundant (∼4–5 hours). Cells were spheroplasted and chromosomes spread on glass slides according to Loidl et al. and Kim et al. [67], [68]. Primary antibodies were mouse monoclonal anti-myc, goat polyclonal anti-Zip1 (Santa Cruz) and rabbit polyclonal anti-GFP (Molecular Probes). Each was diluted appropriately in the above BSA/TBS blocking buffer. Secondary antibodies were donkey anti-mouse, donkey anti-goat, and donkey anti-rabbit IgG labeled with Alexa488, Alexa645 or 594 and Alexa555 (Molecular Probes), respectively. Stained slides were mounted in Slow Fade Light or Prolong Gold Antifade (Molecular Probes). Spread chromosomes were visualized on an Axioplan IEmot microscope (Zeiss) with appropriate filters. Images were collected using Metamorph (Molecular Devices) image acquisition and analysis software. Acquired images were then analyzed with Image J software (NIH), with total SC length and positions of Zip3 foci for the specifically labeled bivalent were measured from the lacO/LacIGFP-labeled end to the other end (Figure 6B bottom). For each type of chromosome analyzed (III, IV and XV) in each experiment, measurements were made for >300 bivalents, one from each of a corresponding number of spread nuclei. Resulting data were transferred into an EXCEL worksheet for further analysis.
CoC Calculations for Yeast Zip3 Foci
Coefficient of coincidence (CoC) curves were generated from SC length and Zip3 focus positions determined as described above. Each analyzed bivalent was divided into a series of intervals of 0.1 µm in length (corresponding to the resolution with which adjacent Zip3 foci can be resolved). Chromosome III, IV and XV were thus usually divided into 9, 42 and 30 intervals with equal size, respectively. Each chromosome length was normalized to 100% and each Zip3 focus position was also normalized correspondingly. Each Zip3 focus was then assigned to a specific interval according to its coordinate. The total frequency of bivalents having a Zip3 focus in each interval was calculated. For each pair of intervals, the frequency of bivalents having a Zip3 focus in both intervals was determined to give the “observed” frequency of double COs. For each pair of intervals, the total CO frequencies for the two intervals were multiplied to give the frequency of double COs “expected” on the hypothesis of independent occurrence. The ratio of these two values is the CoC. Thus in each pair of intervals, CoC = (Obs DCO)/(Pred DCO). CoC values for all pairs of intervals can be plotted as a function of the distance between the midpoints of the two involved intervals (“inter-interval distance”). However, for all of the data shown here, the CoC values from all pairs of intervals having same inter-interval distance were averaged and this average CoC was plotted as a function of inter-interval distance (e.g. Figure 6C and others).
BF Software and Simulations
The previous Beam Film program [3] was rewritten in MATLAB (R2010a) for easy use and modified to include more features as described in the text. Extensive details regarding program structure and application are provided in the Protocol S1 section. However, briefly, there are three options in the software that serve three different purposes:
-
Analyze existing CO data. This option allows the user to process an experimental CO data set. Outputs include a variety of different CO distribution descriptors including CoC curves, ED relationships including the average number of COs/bivalent, average inter-CO distance and evaluation of the gamma distribution shape parameter (ν).
-
Do a single BF simulation with a particular set of specified parameter values. This option gives the same outputs as for analysis of an existing CO data set. It can help the user to understand how the BF model works (e.g. by extension of examples presented in the Results). It also enables a skilled user to do a single round of BF simulation at some single particular parameter condition.
-
Scan a range of parameters to get a BF best-fit simulation of an experimental data set. This option automatically scans all parameter combinations (over specified ranges of each parameter) and outputs the results in rank order according to the goodness of fit levels calculated based on PLS (Projected Likelihood Score) as defined by Falque et al. [18], [19]. However, the rank order defined by PLS is not a maximum likelihood method. As a result, the best fit judged by PLS is not always the actual best fit. To overcome this drawback, the software outputs the results for all parameter combinations scanned, which the user can further evaluate to select the actual best fit. We normally choose the best fit by comparing experimental and simulated data sets with respect to the CoC curve, the average number of COs per bivalent and the distribution of CO number per bivalents (the ED distribution).
Other Data Used in This Study
The Chorthippus L3 chiasmata data were generously provided by Gareth Jones (University of Birmingham, UK). The Drosophila X-chromosome crossover data are from [33]. The tomato (S. lycopersicum) Mlh1 foci date are from [38] (generously provided by F. Lhuissier). Zip2 data in the S.cerevisiae BR background are from [31] (generously provided by J. Fung).
Supporting Information
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Zdroje
1. MullerHJ (1916) The Mechanism of Crossing Over. Am Nat 50 : 193–434.
2. SturtevantAH (1915) The behavior of the chromosomes as studied through linkage. Z indukt Abstamm-u VererbLehre 13 : 234–287.
3. KlecknerN, ZicklerD, JonesGH, DekkerJ, PadmoreR, et al. (2004) A mechanical basis for chromosome function. Proc Natl Acad Sci U S A 101 : 12592–12597.
4. BornerGV, KlecknerN, HunterN (2004) Crossover/noncrossover differentiation, synaptonemal complex formation, and regulatory surveillance at the leptotene/zygotene transition of meiosis. Cell 117 : 29–45.
5. Hunter N (2006) Meiotic recombination. In: Aguilera A, Rothstein R editors. Molecular Genetics of Recombination. pp 381–442.
6. DrouaudJ, MercierR, ChelyshevaL, BerardA, FalqueM, et al. (2007) Sex-specific crossover distributions and variations in interference level along Arabidopsis thaliana chromosome 4. PLoS Genet 3: e106.
7. PetkovPM, BromanKW, SzatkiewiczJP, PaigenK (2007) Crossover interference underlies sex differences in recombination rates. Trends Genet 23 : 539–542.
8. BillingsT, SargentEE, SzatkiewiczJP, LeahyN, KwakIY, et al. (2010) Patterns of recombination activity on mouse chromosome 11 revealed by high resolution mapping. PLoS One 5: e15340.
9. HillersKJ, VilleneuveAM (2003) Chromosome-wide control of meiotic crossing over in C. elegans. Curr Biol 13 : 1641–1647.
10. Oliver-BonetM, CampilloM, TurekPJ, KoE, MartinRH (2007) Analysis of replication protein A (RPA) in human spermatogenesis. Mol Human Reprod 13 : 837–844.
11. de BoerE, StamP, DietrichAJ, PastinkA, HeytingC (2006) Two levels of interference in mouse meiotic recombination. Proc Natl Acad Sci U S A 103 : 9607–9612.
12. StorlazziA, GarganoS, Ruprich-RobertG, FalqueM, DavidM, et al. (2010) Recombination proteins mediate meiotic spatial chromosome organization and pairing. Cell 141 : 94–106.
13. ZhangL, KimKP, KlecknerNE, StorlazziA (2011) Meiotic double-strand breaks occur once per pair of (sister) chromatids and, via Mec1/ATR and Tel1/ATM, once per quartet of chromatids. Proc Natl Acad Sci U S A 108 : 20036–41.
14. BerchowitzLE, CopenhaverGP (2010) Genetic interference: don't stand so close to me. Curr Genomics 11 : 91–102.
15. ColeF, KauppiL, LangeJ, RoigI, WangR, et al. (2012) Homeostatic control of recombination is implemented progressively in mouse meiosis. Nat Cell Biol 14 : 424–430.
16. MetsDG, MeyerBJ (2009) Condensins regulate meiotic DNA break distribution, thus crossover frequency, by controlling chromosome structure. Cell 139 : 73–86.
17. McPeekS, SpeedTP, MorH (1995) Modeling Interference in Genetic Recombination. Genetics 1044 : 1031–1044.
18. FalqueM, AndersonLK, StackSM, GauthierF, MartinOC (2009) Two types of meiotic crossovers coexist in maize. Plant Cell 21 : 3915–3925.
19. GauthierF, MartinOC, FalqueM (2011) CODA (crossover distribution analyzer): quantitative characterization of crossover position patterns along chromosomes. BMC Bioinformatics 12 : 27.
20. FossE, LandeR, StahlFW, SteinbergCM (1993) Chiasma interference as a function of genetic distance. Genetics 133 : 681–691.
21. PanJ, SasakiM, KniewelR, MurakamiH, BlitzblauHG, et al. (2011) A hierarchical combination of factors shapes the genome-wide topography of yeast meiotic recombination initiation. Cell 144 : 719–731.
22. ChenSY, TsubouchiT, RockmillB, SandlerJS, RichardsDR, et al. (2008) Global analysis of the meiotic crossover landscape. Dev Cell 15 : 401–415.
23. BordeV, LinW, NovikovE, PetriniJH, LichtenM, et al. (2004) Association of Mre11p with double-strand break sites during yeast meiosis. Mol Cell 13 : 389–401.
24. GertonJL, DerisiJ, ShroffR, LichtenM, BrownPO, et al. (2000) Global mapping of meiotic recombination hotspots and coldspots in the yeast Saccharomyces cerevisiae. Proc Natl Acad Sci U S A 97 : 11383–11390.
25. BlatY, ProtacioRU, HunterN, KlecknerN (2002) Physical and functional interactions among basic chromosome organizational features govern early steps of meiotic chiasma formation. Cell 111 : 791–802.
26. BuhlerC, BordeV, LichtenM (2007) Mapping meiotic single-strand DNA reveals a new landscape of DNA double-strand breaks in Saccharomyces cerevisiae. PLoS Biol 5: e324.
27. KauppiL, BarchiM, LangeJ, BaudatF, JasinM, et al. (2013) Numerical constraints and feedback control of double-strand breaks in mouse meiosis. Genes Dev 27 : 873–886.
28. JoyceEF, McKimKS (2010) Chromosome axis defects induce a checkpoint-mediated delay and interchromosomal effect on crossing over during Drosophila meiosis. PLoS Genet 6: e1001059.
29. JoyceEF, McKimKS (2011) Meiotic checkpoints and the interchromosomal effect on crossing over in Drosophila females. Fly (Austin) 5 : 134–140.
30. HigginsJD, PerryRM, BarakateA, RamsayL, WaughR, et al. (2012) Spatiotemporal asymmetry of the meiotic program underlies the predominantly distal distribution of meiotic crossovers in barley. Plant Cell 24 : 4096–4109.
31. FungJC, RockmillB, OdellM, RoederGS (2004) Imposition of crossover interference through the nonrandom distribution of synapsis initiation complexes. Cell 116 : 795–802.
32. MalkovaA, SwansonJ, GermanM, McCuskerJH, HousworthEA, et al. (2004) Gene conversion and crossing over along the 405-kb left arm of Saccharomyces cerevisiae chromosome VII. Genetics 168 : 49–63.
33. CharlesDR (1938) The spatial distribution of cross-overs in X-chromosome tetrads of Drosophila melanogaster. J Genetics 36 : 103–126.
34. MehrotraS, McKimKS (2006) Temporal analysis of meiotic DNA double-strand break formation and repair in Drosophila females. PLoS Genet 2: e200.
35. LandeR, StahlFW (1993) Chiasma interference and the distribution of exchanges in Drosophila melanogaster. Cold Spring Harb Symp Quant Biol 58 : 543–552.
36. LaurieDA, JonesGH (1981) Inter-individual variation in chiasma distribution in Chorthippus brunneus (Orthoptera: Acrididae). Heredity 47 : 409–416.
37. JonesGH (1984) The control of chiasma distribution. Symp Soc Exp Biol 38 : 293–320.
38. LhuissierFG, OffenbergHH, WittichPE, VischerNO, HeytingC (2007) The mismatch repair protein MLH1 marks a subset of strongly interfering crossovers in tomato. Plant Cell 19 : 862–876.
39. ColomboPC, JonesGH (1997) Chiasma interference is blind to centromeres. Heredity (Edinb) 79(Pt 2): 214–227.
40. SaintenacC, FalqueM, MartinOC, PauxE, FeuilletC, et al. (2009) Detailed recombination studies along chromosome 3B provide new insights on crossover distribution in wheat (Triticum aestivum L.). Genetics 181 : 393–403.
41. LianJ, YinY, Oliver-BonetM, LiehrT, KoE, et al. (2008) Variation in crossover interference levels on individual chromosomes from human males. Hum Mol Genet 17 : 2583–2594.
42. BromanKW, RoweLB, ChurchillGA, PaigenK (2002) Crossover interference in the mouse. Genetics 160 : 1123–1131.
43. MartiniE, DiazRL, HunterN, KeeneyS (2006) Crossover homeostasis in yeast meiosis. Cell 126 : 285–295.
44. RosuS, LibudaDE, VilleneuveAM (2011) Robust crossover assurance and regulated interhomolog access maintain meiotic crossover number. Science 334 : 1286–1289.
45. YokooR, ZawadzkiKA, NabeshimaK, DrakeM, ArurS, et al. (2012) COSA-1 reveals robust homeostasis and separable licensing and reinforcement steps governing meiotic crossovers. Cell 149 : 75–87.
46. GlobusST, KeeneyS (2012) The joy of six: how to control your crossovers. Cell 149 : 11–12.
47. JonesGH, FranklinFC (2006) Meiotic crossing-over: obligation and interference. Cell 126 : 246–248.
48. HawleyRS, TheurkaufWE (1993) Requiem for distributive segregation: achiasmate segregation in Drosophila females. Trends Genet 9 : 310–317.
49. ArguesoJL, KijasAW, SarinS, HeckJ, WaaseM, et al. (2003) Systematic mutagenesis of the Saccharomyces cerevisiae MLH1 gene reveals distinct roles for Mlh1p in meiotic crossing over and in vegetative and meiotic mismatch repair. Mol Cell Biol 23 : 873–886.
50. ArguesoJL, WanatJ, GemiciZ, AlaniE (2004) Competing crossover pathways act during meiosis in Saccharomyces cerevisiae. Genetics 168 : 1805–1816.
51. ZakharyevichK, TangS, MaY, HunterN (2012) Delineation of joint molecule resolution pathways in meiosis identifies a crossover-specific resolvase. Cell 149 : 334–347.
52. ManceraE, BourgonR, BrozziA, HuberW, SteinmetzLM (2008) High-resolution mapping of meiotic crossovers and non-crossovers in yeast. Nature 454 : 479–485.
53. FranklinWS, FossHM (2010) A two-pathway analysis of meiotic crossing over and gene conversion in Saccharomyces cerevisiae. Genetics 186 : 515–536.
54. BzymekM, ThayerNH, OhSD, KlecknerN, HunterN (2010) Double holliday junctions are intermediates of DNA break repair. Nature 464 : 937–941.
55. KingJS, MortimerRK (1990) A polymerization model of chiasma interference and corresponding computer simulation. Genetics 126 : 1127–1138.
56. FujitaniY, MoriS, KobayashiI (2002) A reaction-diffusion model for interference in meiotic crossing over. Genetics 161 : 365–372.
57. HanYW, MizuuchiK (2010) Phage Mu transposition immunity: protein pattern formation along DNA by a diffusion-ratchet mechanism. Mol Cell 39 : 48–58.
58. VecchiarelliAG, HwangLC, MizuuchiK (2013) Cell-free study of F plasmid partition provides evidence for cargo transport by a diffusion-ratchet mechanism. Proc Natl Acad Sci U S A 110: E1390–1397.
59. HultenMA (2011) On the origin of crossover interference: A chromosome oscillatory movement (COM) model. Mol Cytogenet 4 : 10.
60. GetzTJ, BanseSA, YoungLS, BanseAV, SwansonJ, et al. (2008) Reduced mismatch repair of heteroduplexes reveals “non”-interfering crossing over in wild-type Saccharomyces cerevisiae. Genetics 178 : 1251–1269.
61. StraightAF, Belmont AS, RobinettCC, MurrayAW (1996) GFP tagging of budding yeast chromosomes reveals that protein-protein interactions can mediate sister chromatid cohesion. Curr Biol 6 : 1599–1608.
62. HollingsworthNM, PonteL, HalseyC (1995) MSH5, a novel MutS homolog, facilitates meiotic reciprocal recombination between homologs in Saccharomyces cerevisiae but not mismatch repair. Genes Dev 9 : 1728–1739.
63. AgarwalS, RoederGS (2000) Zip3 provides a link between recombination enzymes and synaptonemal complex proteins. Cell 102 : 245–255.
64. ChuaPR, RoederGS (1998) Zip2, a meiosis-specific protein required for the initiation of chromosome synapsis. Cell 93 : 349–359.
65. CherryJM, BallC, WengS, JuvikG, SchmidtR, et al. (1997) Genetic and physical maps of Saccharomyces cerevisiae. Nature 387 : 67–73.
66. KoszulR, KlecknerN (2009) Dynamic chromosome movements during meiosis: a way to eliminate unwanted connections? Trends Cell Biol 19 : 716–724.
67. LoidlJ, KleinF, EngebrechtJ (1998) Genetic and morphological approaches for the analysis of meiotic chromosomes in yeast. Methods Cell Biol 53 : 257–285.
68. KimPK, WeinerBM, ZhangL, JordanA, DekkerJ, et al. (2010) Sister cohesion and structural axis components mediate homolog bias of meiotic recombination. Cell 143 : 924–937.
69. QiaoH, LohmillerLD, AndersonLK (2011) Cohesin proteins load sequentially during prophase I in tomato primary microsporocytes. Chromosome Res 19 : 193–207.
70. DolezelJ, BartosJ, VoglmayrH, GreilhuberJ (2003) Nuclear DNA content and genome size of trout and human. Cytometry A 51 : 127–128.
71. SantosJ, del CerroA, DíezM (1993) Spreading synaptonemal complexes from the grasshopper Chorthippus jacobsi: pachytene and zygotene observations. Hereditas 118 : 235–241 Hereditas 118 : 235–241.
72. PageSL, HawleyRS (2001) c(3)G encodes a Drosophila synaptonemal complex protein. Genes Dev 15 : 3130–3143.
73. CarpenterAT (1979) Recombination nodules and synaptonemal complex in recombination-defective females of Drosophila melanogaster. Chromosoma 75 : 259–292.
74. PetersonDG, StackSM, PriceJH, JohnstonJS DNA content of heterochromatin and euchromatin in tomato (Lycopersicon esculentum) pachytene chromosomes. Genome 39 : 77–82.
75. ShermanJD, StackSM (1995) Two-dimensional spreads of synaptonemal complexes from solanaceous plants. VI. High-resolution recombination nodule map for tomato (Lycopersicon esculentum). Genetics 141 : 683–708.
Štítky
Genetika Reprodukční medicínaČlánek vyšel v časopise
PLOS Genetics
2014 Číslo 1
- Kazuistika – Perspektivy využití precizované medicíny v rámci personalizované specifické terapie onkologických pacientů
- Nobelova cena za chemii pro genetické nůžky: Objev, který změní naši budoucnost?
- Technologie na bázi RNA v klinické praxi: od přebarvených petúnií k terapii vzácných a dosud jen obtížně léčitelných chorob u lidí
- „Nepředstavovali jsme si, že náš výzkum povede přímo ke vzniku nových léků, dokonce ještě za našeho života“
- Bezplatné služby pro diagnostiku ATTRv amyloidózy pro kardiology
Nejčtenější v tomto čísle
- GATA6 Is a Crucial Regulator of Shh in the Limb Bud
- Large Inverted Duplications in the Human Genome Form via a Fold-Back Mechanism
- Differential Effects of Collagen Prolyl 3-Hydroxylation on Skeletal Tissues
- Affects Plant Architecture by Regulating Local Auxin Biosynthesis
Zvyšte si kvalifikaci online z pohodlí domova
Mazová zátka a její řešení
nový kurzVšechny kurzy