
A Genome-Wide Association Analysis Reveals Epistatic Cancellation of Additive Genetic Variance for Root Length in
Complex traits, such as many human diseases or climate adaptation and production traits in crops, arise through the action and interaction of many genes and environmental factors. Classic approaches to identify contributing genes generally assume that these factors contribute mainly additive genetic variance. Recent methods, such as genome-wide association studies, often adhere to this additive genetics paradigm. However, additive models of complex traits do not reflect that genes can also contribute with non-additive genetic variance. In this study, we use Arabidopsis thaliana to determine the additive and non-additive genetic contributions to the phenotypic variation in root length. Surprisingly, much of the observed phenotypic variation in root length across genetically divergent strains was explained by epistasis. We mapped seven loci contributing to the epistatic genetic variance and validated four genes in these loci with mutant analysis. For three of these genes, this is their first implication in root development. Together, our results emphasize the importance of considering both non-additive and additive genetic variance when dissecting complex trait variation, in order not to lose sensitivity in genetic analyses.
Published in the journal:
. PLoS Genet 11(9): e32767. doi:10.1371/journal.pgen.1005541
Category:
Research Article
doi:
https://doi.org/10.1371/journal.pgen.1005541
Summary
Complex traits, such as many human diseases or climate adaptation and production traits in crops, arise through the action and interaction of many genes and environmental factors. Classic approaches to identify contributing genes generally assume that these factors contribute mainly additive genetic variance. Recent methods, such as genome-wide association studies, often adhere to this additive genetics paradigm. However, additive models of complex traits do not reflect that genes can also contribute with non-additive genetic variance. In this study, we use Arabidopsis thaliana to determine the additive and non-additive genetic contributions to the phenotypic variation in root length. Surprisingly, much of the observed phenotypic variation in root length across genetically divergent strains was explained by epistasis. We mapped seven loci contributing to the epistatic genetic variance and validated four genes in these loci with mutant analysis. For three of these genes, this is their first implication in root development. Together, our results emphasize the importance of considering both non-additive and additive genetic variance when dissecting complex trait variation, in order not to lose sensitivity in genetic analyses.
Introduction
Identifying the loci underlying quantitative phenotypes is among the central challenges in genetics. The current quantitative genetics paradigm is based on the assumption of additive gene action, despite an increasing body of evidence showing that non-additive effects are crucial to many, if not most, biological systems [1–4]. The key arguments for remaining within the additive paradigm are that many genetic architectures with non-additive gene action display considerable additive genetic variance in populations [5] and that additive model-based approaches have facilitated detection of thousands of loci associated with many complex traits [6]. However, the amount of additive variance contributed by epistasis for example, will vary with the allele-frequencies in populations and therefore be a dynamic property of studied populations [7–13 and references therein]. Therefore, the focus on additive variation alone can leave a considerable amount of genetic variance unexplored [3,14], and for a full dissection of a complex trait, it is often necessary to explore alternative approaches that capture non-additive variation. Statistical epistasis has been shown to be pervasive in both humans and model organisms [2,14]. Epistatic contributions to complex traits have primarily been identified in experimental populations using candidate gene approaches [1,2,4,15–19] and QTL mapping, for example [1,20]. Genome-wide association (GWA) analyses have more recently emerged as an effective method for mapping loci underlying phenotypic variation for complex traits also in natural populations. However, GWA analyses to detect epistatic interactions are still under-utilized in efforts to identify loci contributing to the genetic architecture of complex traits. To obtain a more complete compilation of the loci contributing to the variation of a complex trait, it would therefore be valuable to also account for epistatic interactions in addition to additive effects in existing and future datasets.
The drawbacks of studying epistasis in natural populations of higher organisms include the cost and time to collect large datasets, the lack of power due to noisy phenotypes, and the difficulties in performing the necessary follow-up studies to replicate the epistatic associations, identify the polymorphic genes, and dissect the underlying mechanisms leading to statistical epistatic associations. Efforts to utilize epistatic interactions for detection of novel loci, however, are of importance for enhancing sensitivity in statistical analyses [21], for selecting the most promising analytical approaches and experimental designs for future work, and for providing insights as to what type of genetic and biological mechanisms can lead to non-additive genetic variance and genotype-phenotype relationships. Public resources have recently been developed for studying genotype-phenotype associations with GWA analyses in model organisms such as Arabidopsis thaliana [22] and Drosophila melanogaster [23]. Many powerful experimental approaches are available in these species, making them attractive for studies aiming to functionally dissect more complex genetic mechanisms such as those underlying statistical epistatic associations. For these reasons, these resources have the potential to contribute to the fundamental work of clarifying how statistical epistatic analyses should more generally be interpreted and used in efforts to dissect the genetic architectures of complex traits.
Two major challenges have often been discussed in relation with GWA analyses based on statistical epistatic models: the lack of sufficiently large experimental datasets to obtain reasonable statistical power and the computational complexity when screening the genome for multi-locus epistasis. One of the causes of low power is the need to use stringent, multiple-testing corrected significance-thresholds to account for the large number of statistical tests performed when exploring epistasis between all possible combinations of loci [24]. As allele-frequencies are often skewed in the populations used for GWA analyses, power is decreased further due to the small number of observations in the multi-locus, minor-allele genotype classes. To some extent these challenges can be overcome by increasing the sample size and making efficient use of high-performance computing [25]. Leveraging genotyped populations of model organisms can also overcome statistical limitations. The genomes of model organisms are often smaller, which reduces the search-space during genome-wide scans. The existence of inbred populations, such the A. thaliana RegMap [26] or 1001 Genomes Project [14] or the D. melanogaster Drosophila Genetic Reference Panel [15] collections, provide advantages in power compared to analyses in general outbred populations with heterozygotes. This is particularly true in analyses of epistasis due to the simpler genotype-phenotype maps. Several standard additive GWA analyses have previously been performed for many traits using the publically available A. thaliana collections and data sets [27,28], including several studies of A. thaliana root phenotypes [29–31]. A. thaliana has a small genome (~125 Mb), large numbers of readily available inbred accessions, a large knowledge base on how to efficiently score quantitative phenotypes in large numbers of individuals, and powerful experimental resources, such as collections of knock-out lines. This makes such populations into particularly well-suited models for performing exhaustive scans for epistasis and for evaluating whether non-additive genetic analyses are able to uncover novel contributions of genes to the studied phenotypes. However, due to the advantages of the model populations outlined above, the power of a GWA will be considerably larger than in a segregating natural population of the same size in, for example, humans. Hence, advanced analyses are still worth considering, as the power to map novel loci will be considerably higher than expected based on sample size alone.
Model organism GWA studies, however, are often based on a hundred or fewer individuals, and valid concerns have been raised regarding the challenges of testing for associations with hundreds of thousands of markers, or millions of combinations of epistatic markers in such small samples. In particular, the risk of detecting a random association will increase especially when the number of individuals in the minor two-locus genotype class is small. This situation is not accounted for by common statistical multiple-testing correction. Further, there is also a risk of statistical epistatic associations arising due to “apparent epistasis” [32] in which the multi-locus genotype tags an unobserved, single polymorphism in the genome. Here, the genetic variance used to detect the association originates from a true genetic effect in the genome, but this effect is hidden in a standard GWA due to its low correlation with the individual genotyped markers. Instead the high-order correlation between the hidden genetic variant and a multi-marker genotype leads to an epistatic variance that can be detectable in the epistatic GWA analysis. Although this scenario has only previously been discussed for linked variants [32], it could occur for unlinked loci if the analyzed population is small and the number of evaluated combinations of loci is large. Also, this scenario goes beyond standard statistics used to account for multiple testing in GWA analyses, as the increased risk for false positives is not due to the strength of the statistical association. Instead, it results from the inability to properly compare alternative explanatory genetic models for the association using the available genotype data. Unless particular care is taken, both of these scenarios could lead to an increased false-positive rate among the reported loci, as well as incorrect interpretations of the presence of biological interactions if significant pairwise statistical epistasis is interpreted as evidence of an underlying genetic architecture with genetic interactions. These potential risks associated with epistatic GWA analyses in small experimental populations should therefore be considered when such analyses are used.
Here, we conduct a GWA study to dissect the genetics underlying A. thaliana root length in a population of wild-collected accessions. The broad-sense heritability for this trait was of intermediate magnitude. However, very little additive, but considerable epistatic, genetic variance could be captured by the genomic relationships between the accessions. The genetic contribution to this trait was therefore unlikely to be detected using standard additive genetic models, and it was not surprising that no locus was associated with root-length in the standard additive-model based GWA analyses. An exhaustive GWA scan for two-locus interactions, however, revealed four genome-wide significant interacting pairs. All of these displayed genotype-phenotype relationships in which epistasis cancelled the marginal additive genetic effects of the interacting loci, explaining the low levels of additive genetic variance in the population. A new statistical method was used to evaluate the robustness of the GWA associations in the small population, and it was estimated that half of these pairs are at risk of being false positives. We also found low risk that the statistical epistatic interactions were caused by “apparent epistasis” [32]. Our experimental evaluations of genes in the associated regions using T-DNA insertion mutants identified functional candidates that affected root length in four regions that were part of three pairs, from which three genes were newly implicated in root development [33]. Together, our results illustrate the value of epistatic GWA analyses for revealing novel loci contributing to complex traits in small, inbred populations. Further, we noticed an increased risk for false-positive epistatic associations and “apparent epistasis” due to the small sample-size but the top-ranked associations proved, despite this, to be valuable in further experimental validation, as several functional candidate genes were identified in loci that would have been discarded based on stringent statistics alone. We also report several promising functional candidate genes for future studies to dissect the molecular mechanisms underlying root development in natural A. thaliana populations that would have remained undetected without an epistatic GWA analysis.
Results
Epistasis is the primary source of genetic variance for root length
To study the genetic regulation of mean root length, we generated a comprehensive data set containing the A. thaliana root mean lengths across 93 wild-collected accessions (S1 Fig, S1 Table, S1 Dataset). The 93 accessions used here were previously genotyped at ~215,000 single nucleotide polymorphisms (SNPs) and used in a standard GWA analysis for many plant phenotypes [27]. We grew seedlings in a randomized design on standard plant medium in temperature-controlled chambers to reduce environmental variation among individuals [34]. This experimental design allows for parsing of genetic and environmental factors underlying root length [35,36].
In our dataset, mean root length varied significantly across accessions (p < 1 × 10−10, ANOVA; Fig 1). To evaluate whether the observed variation in mean root length was under genetic control, we estimated both the narrow - and broad-sense heritability. The broad-sense heritability was first estimated by fitting an ANOVA on accession and found to be intermediate and significant (0.25; Table 1). To estimate the genomic heritability, i.e. the amount of genetic variance accounted for by the genomic kinships between the accessions, we used a linear mixed model that simultaneously estimated polygenic additive and epistatic genomic variance components using the R/hglm package [37]. We estimated the total genomic broad sense heritability (i.e. H2 = (VA+VAA)/VP) to be 0.24 (95% CI 0.10–0.38) for mean root length (Table 1), illustrating that most of the traditional broad-sense heritability could be captured by the additive and additive-by-additive epistatic genomic relationships between the accessions. We further partitioned the genetic variance explained by the markers into the individual additive and epistatic variance components and found that almost all the variance was epistatic (0.22; p = 1.32 × 10−6) and only a small, insignificant fraction was additive (0.01; p = 0.63). These results suggest that an epistatic GWA analysis might be needed to identify the loci explaining the heritable phenotypic variation in root length mean.


No additive genome-wide associations were detected for mean root length
Two GWA analysis methods were used to screen for additive loci contributing to the phenotypic variation in mean root length. The first method was a standard single-locus additive mixed-model based approach as implemented in the R-package GenABEL [38] that accounted for population-structure by modeling the genomic kinships between the accessions as a random effect. Significance testing was done using a Bonferroni-corrected significance threshold. The second method was based on a whole-genome generalized ridge regression heteroscedastic effects model (HEM), in which all SNPs were included simultaneously and their contributions estimated as random effects using the R/bigRR package [39]. Here, a 5% genome-wide significance threshold was determined by permutation testing. None of the tested SNPs were significantly associated with mean root length in either of these analyses (S1a and S1b Fig). Given that little additive genetic variance could be accounted for by the genomic relationships between the accessions (h2 = 0.01), this outcome was not surprising.
An epistatic genome-wide association analysis uncovered multiple interacting loci that contributed to mean root length
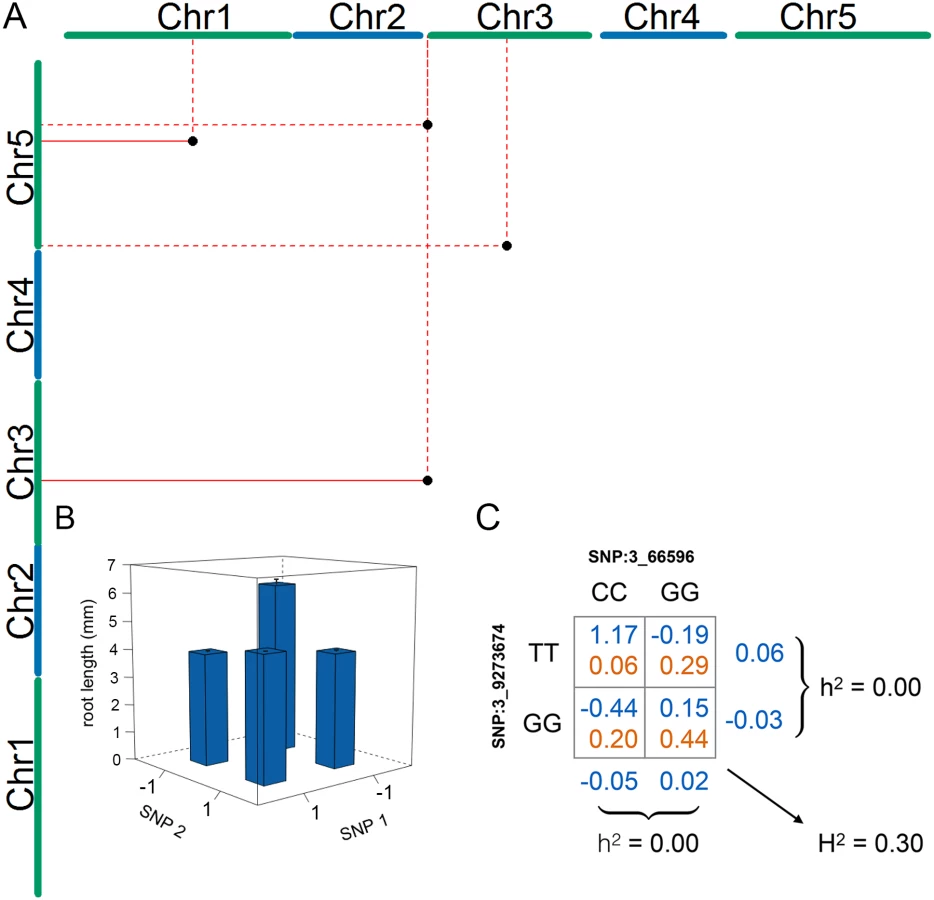
To identify loci that contributed to the epistatic genetic variance for mean root length, we performed an exhaustive two-locus SNP-by-SNP epistasis analysis (PLINKv1.07) [40]. Despite the limited population size, several factors increased our chances of finding novel loci using this approach: the small additive and large epistatic genetic variance (Table 1), the high precision in estimating the phenotypic values due to extensive replication, the presence of only four two-locus genotypes in the population of inbred accessions, and a reduced number of pairwise combinations to test in the small genome. To further enhance power and decrease the risk of false-positives, we excluded pairs of SNPs where the minor two-locus genotype class contained few observations. This was achieved by applying two data filters: first, only SNPs with a minor allele frequency greater than 0.25 were included, and second all SNP-by-SNP combinations with fewer than four accessions in the minor genotype class were removed. In the epistatic analyses, we accounted for population structure by performing the GWA analysis using a linear mixed model including the genomic kinship matrix. Significance for the pairs were determined using a standard Bonferroni-correction for the number of independent pair-wise tests across the independent linkage blocks across the A. thaliana genome [41]. In total, the epistatic analysis included approximately 78 million such independent tests. Six SNP-pairs, representing seven genomic locations and four unique combinations of loci, passed this threshold (Table 2). Two pairs were detected twice by associations to tightly linked SNPs located 1.5 kb and 505 bp apart (Chromosome 3 at 9,272,294 and 9,273,674 bp—SNPs 3_9272294/ 3_9273674—and Chromosome at 15,862,026 and 15,862,525 bp—SNPs 5_15862026/5_15862525, respectively), and one SNP (Chromosome 3 at 66,596 bp—SNP 3_66596) was part of two unique interacting pairs (Table 2). The other two SNP-pairs contained independent SNPs (R2 < 0.8).

Explorations of epistatic genotype-phenotype maps revealed an epistatic cancellation of the additive genetic variance
The four SNP pairs that were significant in the epistatic GWA (Table 2; Fig 2a) explained no additive variance, but together explained 51% of the phenotypic variance of mean root length (95% CI: 31.2% - 72.4% from bootstrap). To explore the origin of the low additive variance in the presence of the revealed epistasis, we estimated the multi-locus genotype-phenotype (G-P) maps and their respective genotype frequencies in the analyzed population. The G-P maps were highly related for the four pairs: the minor allele double-homozygote was always associated with the longest mean root length and the shortest mean root lengths were associated with the genotypes combining one major - and one minor-allele homozygote (Fig 2b; S2 Fig). Although this type of epistasis will lead to marginal additive genetic effects for the two loci for many allele-frequencies, there are also combinations of allele-frequencies where the epistasis will cancel the additive genetic variance completely. We illustrate this epistatic cancellation of the additive genetic variance for the G-P map and allele-frequencies of the most significant pair in Fig 2c. For this pair, there are minimal differences in the average (marginal) mean root lengths for the two genotypes at the individual loci, and hence a minor contribution to the additive genetic variance. Their joint contribution to the phenotypic variance, however, is large due to the large differences in root lengths among the four two-locus genotype classes. The epistatic GWA analysis is able to reveal these pairs in this population as the differences between these genotypes contribute to the epistatic genetic variance instead.
Evaluating the robustness of statistical epistatic associations to a small population size
We next applied a conservative genome-wide test to estimate the risk that the epistatic GWA associations were false positives due to the small population size. A pseudo-marker was created for each pair of SNPs in the epistatic scan, resulting in an epistatic pseudo-genome with 78 million markers. Given the epistatic effect estimated for the four pairs that reached genome-wide significance in the epistatic GWA, we computed the genome-wide probability of these pairs being false-positives using the R/p.exact package [42], assuming conservatively that all the pseudo-markers are independent [42] (Table 3). The pair 3_10891195/5_1027939 was found to be sensitive to population size (p = 0.94). The pairs 1_17257526/5_15862026 and 3_66596/5_18241640 were less sensitive (p = 0.28 and p = 0.37, respectively), and hence there is a 90% probability that at least one of these two signals is not false. The last pair 3_66596/3_9273674 was not sensitive to population-size (p = 0.003). We conclude that it is essential to consider the effect of population-size when interpreting the results from GWA analyses in small populations. In our particular case, half of the original associations were at risk of being false-positives due to small populations size.

Quantifying the risk of “apparent epistasis” for significant statistical epistatic associations
For “apparent epistasis” to be present, the hidden functional variant needs to be in high linkage disequilibrium (measured as r2) with one of the “epistatic pseudo-markers” described above. Therefore, “apparent epistasis” involving physically unlinked markers is only expected for very strong mutations. However, if any such hidden variant exists, by definition neither its genetic effect nor its linkage disequilibrium to the “epistatic pseudo-markers” can be estimated from the GWA datasets. However, if a GWA study is performed in a species with sequenced reference populations, the genomic data from that population can be used to estimate the risk of observing a high r2 between the tested markers and other polymorphisms in the genome. Here, we used the 1001 Genomes Project A. thaliana genomes [22] to perform this analysis for the four significant pairs in the epistatic GWA analysis. We defined bi-allelic “epistatic pseudo-markers” by assigning individuals with the two-locus minor-allele homozygote genotype the minor pseudo-marker genotype and all others the major pseudo-marker genotype. By using a bootstrap analysis based on samples of 93 accessions from the 728 whole-genome re-sequenced accessions from the 1001 Genomes Project data, we estimated the probability of observing a high r2 (r2>0.8) between any individual SNP in the re-sequencing data and the “epistatic pseudo-markers” for the four pairs. This analysis revealed that the “epistatic pseudo-markers” corresponding to the identified pairs have very low r2 to most of the hidden variants (mean r2 = 0.01). There is a very low risk to observe a high r2 (r2 > 0.8) to any hidden variant in our population for the most strongly associated pair (p < 0.005). For the other three pairs, this risk is still low (p = 0.18–0.42) but sufficiently large to indicate that the results should be interpreted with caution (Table 3).
Functional exploration of candidate genes in the associated regions using T-DNA insertion lines
Our statistical analyses suggest that half of the pairs with genome-wide significant statistical epistasis might be false-positives due to the small population-size. As only four pairs were found, we decided to also perform an initial experimental and bioinformatics analysis that included all these pairs to evaluate whether the statistical risk of false-positives was reflected also by the presence of known, or novel, functional candidate genes for root-length in the associated regions.
We therefore first extracted the genotypes for 13 million genome-wide SNPs from the whole-genome re-sequencing data from the 1001 Genomes Project [43]. SNPs that were in LD (r2 > 0.8) and located within 5kb upstream or downstream of the leading SNP in the epistatic GWA were considered further as candidate functional mutations. In Table 4, we list the predicted functional effects of the SNPs that fulfill these criteria, together with their locations, for each pair. In total, thirteen genes and two transposons were found in LD with the leading SNPs in the seven regions detected in the epistatic GWA analysis to root length.

Further, we identified T-DNA insertion lines for 12/15 genes and transposons comprising the seven statistically epistatic loci and experimentally evaluated them for effects on root length (Table 5). For three of these loci (NAC6, TFL1, At2g28880), we are the first to show that these underlying genes contribute to root growth, and for one locus (ATL5), our results confirm previous findings.

T-DNA mutant analysis reveals four functional candidate genes for root development in regions detected using an epistatic genome-wide association analysis
Decreased root length in ATL5/OLI5/PGY3 T-DNA insertion mutants
Two linked SNPs on chromosome 3 (3_9272294 and 3_9273674; Table 2) were associated with A. thaliana root length through an epistatic interaction with a distal SNP on the same chromosome (3_66596). Twenty-one SNPs located in four genes were in high LD with the two linked SNPs (Tables 4 and 5). For three of these (At3g25520, At3g25530 and At3g25540), we were able to obtain insertion mutants and scored their mean root length compared to wild-type (Col-0) controls. The insertion mutant for At3g25520 had significantly shorter roots than wild type (p = 1.2 × 10−4; Tukey’s post-hoc test); the insertion mutants for At3g25530 and At3g25540 did not differ significantly (p = 1.00 and p = 0.23, respectively) from wild type (Fig 3).

At3g25520 encodes ATL5/OLI5/PGY3, a 5S rRNA binding protein whose promoter is highly accessible in seedling roots [45], corresponding to expression in roots [44]. Our finding agrees with earlier studies, in which the loss-of-function mutant oli5-1 exhibits shorter primary roots than wild-type [33]. In the tested accessions, three SNPs were found in the ATL5 promoter and a fourth in an intron, suggesting variable transcriptional regulation across accessions.
A novel role for NAC6 in the regulation of root length
Two linked SNPs on chromosome 5 (5_15862026 and 5_15862525; Table 2) were detected by their statistical epistatic interaction with an SNP on chromosome 1 (17,257,526 bp—SNP 1_17257526; Table 2). Both of these linked SNPs, as well as the other SNPs in high LD, were intergenic with the nearest gene, NAC6 (At5g39610; Table 5), which is located 1.9 kb away. NAC6 is a transcription factor regulating leaf senescence [46] and is highly expressed in senescing leaves and in maturing seeds [44]. We phenotyped the available At5g39610 insertion mutant for NAC6 and found a significant decrease in mean root length (p = 5.82 × 10−10; Tukey’s post-hoc test; Fig 4), strongly implicating NAC6 in the regulation of root length.

The previously uncharacterized gene At3g28880 contributes to root length
A locus on chromosome 3 (10,891,195—SNP 3_10891195; Table 2) was identified due to its statistical epistatic interaction with a locus on chromosome 5 (1,027,939 bp—SNP 5_1027939; Table 2). SNPs in LD with 3_10891195 were found in three genes: At3g28865, At3g28870, and At3g28880 (Table 5). None of these genes previously had been associated with root length. By examining available insertion mutants, we established a novel role for the gene At3g28880 in root development; its mutant showed significantly decreased mean root length compared to wild-type controls (p = 4.5 × 10−10; Fig 4), whereas At3g28865 did not. At3g28880 encodes a previously uncharacterized ankyrin family protein. There is no information on developmental expression patterns for this gene; although the gene’s putative regulatory region is accessible in seeds and seedling tissue [45]. Across the tested accessions, a number of promoter-proximal SNPs were found in At3g28880, possibly altering gene regulation.
Mutant TFL1 increases mean root length
The SNP 5_1027939 was detected via its epistatic interaction with the At3g28880 locus on chromosome 3 (Table 2). This polymorphism and the only other polymorphism in LD are both intergenic between the genes At5g03840 and At5g03850 (Table 5). Phenotyping the insertion mutants for these genes revealed that the mutant for At5g03840, which encodes TFL1, showed significantly longer roots than wild-type controls (p = 5.7 × 10−10; Tukey post-hoc test; Fig 4), whereas no significant phenotypic effect was found for the At5g03850 mutant. Interestingly, these results implicate TFL1 as a repressor of root growth.
TFL1’s role in floral initiation and morphology are well-established in many plant species [47]. It also plays a role in regulating protein storage in vegetative tissues, such as roots or seeds [48]. TFL1 is highly expressed in both adult and seedling roots [44]. Our finding that TFL1 controls root length is particularly poignant as a previous study reported no root length defects for a different tfl1 mutant with multiple other pleiotropic phenotypes [49]. Our finding extends the functional reach of this multi-functional regulator.
Discussion
This study was designed to identify genes regulating seedling root length. The genomic narrow-sense heritability for this trait was not significantly different from zero in our population, whereas there was significant broad-sense heritability (Table 1). Notably, we observed a very large contribution of epistatic variance to the phenotypic variation in mean root length. With these findings in hand, we completed a comprehensive set of GWA analyses to identify additive and epistatic loci affecting this trait.
Consistent with the low additive genetic variance for mean root length that could be captured by the genotyped markers, we were unable to identify any additive loci that reached the Bonferroni-corrected significance threshold in our analyses. By accounting for the contribution of pairwise epistatic interactions to the genetic variance of root length, however, we identified seven loci involved in four unique epistatically interacting pairs of loci that together explained a large fraction of the phenotypic variance in the population (Table 2). One of these pairs is highly significant also when accounting for the small population-size, whereas there is a risk that two of the three remaining pairs are false-positives due to this. We also showed that it is unlikely that the statistical epistatic interaction for the most significant pair would result from “apparent epistasis” due to a major, hidden variant in the genome. This risk is, however, not negligible for the three less significant pairs. Based on this, we conclude that despite the fact that much of the genetic variance present in this population can be explained by the genome-wide significant pairwise epistasis detected amongst these loci, additional evidence is needed before any firm conclusions can be drawn based on the other three epistatic pairs detected in the GWA analysis.
All four pairs detected in the initial epistatic GWA display an epistatic cancellation of additive genetic variance (Fig 2c). The presence of this type of genetic architecture for root-length in this population explains the low narrow-sense heritability in the population and why no loci could be found in the standard GWA analyses. Although further studies are needed to explore how general this phenomenon is, our result contrasts the common view in quantitative genetics that most genetic variance for complex traits is expected to be additive [5]. It further illustrates the importance of taking a richer modeling approach in GWA analyses to improve the sensitivity as a too strict focus on additive effects in the initial statistical analyses might lead to important findings being missed and lead to an underestimation of the full adaptive potential due to the epistatic suppression of selectable additive genetic variance [10–12].
Our finding of extensive statistical epistasis in this study should not be interpreted as evidence for root development being a biological trait with exceptionally high levels of biological interactions. Rather it is important to notice that, although the levels of statistical epistasis detected here originate in the epistatic genotype-phenotype maps for these pairs, the exceptionally high levels of epistatic variance in the population is even more due to the allele-frequencies for the involved loci in the population (Fig 2c). Hence if the loci displaying the G-P map in Fig 2c instead, for example, would be present at intermediary and equal frequencies, they would contribute high levels of additive genetic variance instead. Consequently, our results is an important reinforcement of the fact that the levels of epistatic variance for a trait in a population will be a dynamic outcome of changes in genotype-frequencies over time even though the underlying genotype-phenotype map might be constant [7–13].
In practice, however, neither allele frequencies nor genotype-phenotype maps will be known for the loci contributing to a particular trait. As illustrated by our findings for root length in this population, it is important to utilize GWA analysis methods that account for both additive and non-additive genetic variance to detect the contributing loci. Once this is done, further theoretical and experimental work is needed to identify the underlying genotype-phenotype maps and dissect the molecular underpinnings of the statistical associations regardless of whether these were detected mainly via their contributions to the additive and/or epistatic genetic variance. We here propose how to statistically quantify the risks of each inferred epistatic GWA association to guide further experimental work based on these findings. We find that there were statistical reasons to interpret three of the detected epistatic pairs with caution, both due to an increased risk of false-positives due to the small population-size and an inflated risk for “apparent epistasis”. Three novel functional candidate genes were, however, identified in loci detected as part of these associations. This illustrates clearly that the ultimate contribution from a study will rely on the combined use of appropriate statistical analyses to quantify the confidence in a particular locus and an in-depth experimental dissection of the detected associations before a conclusion can be reached about which loci contribute to a particular trait.
Functional dissection of epistasis, however, is a daunting task in natural populations and therefore model organisms are an indispensable resource in this work. A first step in taking on this challenge is to reduce the list of potential candidate genes and mutations for further, in-depth functional explorations. Here, we use mutational analysis of the genes that harbor SNPs in LD with the associated SNPs in the epistatic GWA analysis to identify the most likely candidate genes for the inferred associations. Detection of functional candidate genes using T-DNA analyses in regions identified using GWA analyses is also a potential way to functionally validate the associations. However, its value for this purpose depends on generally unknown mutational target size; what proportion of randomly mutated genes will affect the studied phenotype? Although the majority of evaluated single-gene mutations do not affect root length [4,35,50], root length is regulated by many classes of genes containing hundreds or perhaps even thousands of genes [51]. To our knowledge, no comprehensive analysis is available that estimates the proportion of T-DNA lines that affects root length. However, a previous study including thousands of A. thaliana T-DNA lines identified that rosette size or leaf number phenotypes were significantly affected in about 10% of the lines and foliar metabolic phenotypes were significantly affected in about 5% of the lines based on different amino acid traits (plastid.msu.edu) [52]. Another study [53] of glucosinolate traits in a random T-DNA collection identified a 5% rate of significant phenotypes. A reasonable base-level estimate for the mutation target size of a complex trait in A. thaliana based on these earlier studies would thus be in the range between 5–10% of the evaluated T-DNA lines.
We tested six of the seven epistatic regions with 13 available T-DNA insertion mutants (S2 Table). For four of the loci, we succeeded in identifying candidate genes affecting root length, three of which were newly implicated in root development. Our results demonstrate the benefits of using statistical epistatic analyses in combination with experimental analysis of T-DNA insertion mutants to identify novel functional candidate genes involved in root development and provide a basis for future detailed studies of the complex gene networks involved in this trait (Fig 4). The proportion of evaluated T-DNA mutants found to affect root-length in this study is 3–6 fold higher than the available estimates of how often random T-DNA mutants affect a complex trait in A. thaliana, suggesting that the current approach increases not only the efficiency to find candidate loci for root-length, but that it also is valuable for validating the importance of the detected associations in shaping natural variation in the studied population.
It will be a major endeavor to functionally explore the biological mechanisms contributing to the statistical epistatic associations. None of the genes affecting root development contain non-synonymous mutations with likely phenotypic effects. Also, none of these genes have previously been described to interact with their respective epistatic locus. Future functional studies will have to explore the effects of the observed regulatory SNPs in transgenic plants in several backgrounds to study the whether these statistical interactions are the result of an underlying biological interaction or not. This endeavor will require significant time and resources, yet we believe that A. thaliana root length represents an excellent model trait for future in-depth studies of this type of complex signals arising from GWA studies.
Materials and Methods
Phenotyping
In order to reduce environmental variation among accessions, eighteen individuals from each of the 93 accessions studied in Atwell et al (2010) (S1 Table) were vernalized at 4° as seedlings for six weeks to synchronize growth and flowering. The five most developmentally advanced seedlings from each accession were then transferred to soil in a randomized design. Plants were grown in long-day conditions at 22°. Flats were rotated three times per week to reduce position effects on plant development. Seeds were collected over a period of three months as the plants dried. Equal numbers of seeds were pooled from 3–5 parent plants to reduce the environmental contribution of plant placement across flats of plants. Ethanol sterilized seeds were planted on 1× Murashige and Skoog (MS) basal salt medium supplemented with 1× MS vitamins, 0.05% MES (wt/vol), and 0.3% (wt/vol) phytagel in a semi-randomized design with n = 70 per accession. Four sets of twenty-three accessions plus a control accession (Col-0) made up a set. Each set was replicated three times providing the standard error for variance, with a total n = 210 planted for each accession. The seeds were stratified at 4° for three days and then grown for seven days in darkness with the plates in a vertical position. A photograph of each plate was taken, and root length was measured manually using the ‘freehand’ function in ImageJ1.46r [54]. Non-germination, missing organs, and delayed development were noted.
Data standardization
Thirty-one seedlings with hypocotyls less than 5mm were removed because it is likely that germination was severely delayed [34]. Between-set differences were corrected by subtracting the difference between Col-0 in each replicate and set and the global mean for Col-0. Systematic differences between replicates were still present and corrected within each set by using the residuals from a model in which root length was explained by the within-set replicates.
Heritability estimation
Heritability of root length variance and mean were estimated using the repeated measures with genotype as a fixed effect using ANOVA. To parse the contribution of additive and epistatic effects, a linear mixed model including both additive and epistatic effects as random effects was fitted using the R/hglm package [37], i.e.



Genome-wide association analysis
Using the transformed mean and the genotypes for the 93 accessions from Atwell et al. (2010), we performed a series of analyses to detect marker-trait associations. For the standard additive GWA analysis with population structure controlled, we used the function egscore() from R/GenABEL [38]. The functions bigRR() and bigRR_update() in the R/bigRR package [39] were used to perform a GWA analysis, in which all genome-wide SNP effects are modeled simultaneously as random effects, and the effects were estimated via the generalized ridge regression method HEM. The maximum absolute effect sizes in 1000 permutations were extracted to determine an empirical 5% genome-wide significance threshold (p = 0.0020).
To screen the genome for pairs of epistatic SNPs, we used the PLINK–epistasis procedure [40] that is based on the model:

We filtered out the pairs where there were fewer than four accessions in the minor two-locus genotype-class. Further, all combinations in which the p-value was > 1 × 10−8 were also removed as it was considered unlikely that they would be significant after correction for population structure and applying a multiple-testing corrected significance threshold. For the remaining pairs, a linear mixed model including fixed, additive and epistatic effects, as in the PLINK based initial scan, were fitted together with a kinship correction for population stratification, as in the single locus analyses, using the package R/hglm. We derived a multiple-testing corrected significance threshold for this epistatic analysis (p = 3.2 × 10−10) by estimating the number of independent tests based on the number of estimated LD blocks in the genome. For this, we used the fact that the A. thaliana genome is approximately 125Mb with average LD-blocks of about 10kb (12,500; [41]), and then applied a Bonferroni correction for the 78 million independent tests performed. Using data on the sixty-three accessions from the GWAs that were unambiguously identified in the 1001 Genomes data [22], we then identified additional SNPs in LD with the leading SNP using the function LD in the genetics package in R across a 10kb region around the marker.
Testing the robustness of epistatic associations in small GWA datasets
To estimate the risk of an increased false positive rate due to low allele frequencies at the loci involved in an epistatic interaction, we created seventy-eight million double-recessive pseudo markers, and used the R/p.exact package [42] to double-assess the exact false discovery rate of each detected epistatic pair based on its estimated epistatic effect size and allele frequency. The method implemented in this package is described in detail elsewhere [42], but in short it analytically derives this estimate based on the genome-wide distribution of pseudo-marker allele-frequencies in the analyzed population, the number of included samples and the estimated genetic effect of the epistatic pair. This estimate is a computationally efficient analytical equivalent of a permutation-test for this purpose under the conditions stated below. As shown in [42], the experiment-wise false positive rate for a particular SNP effect in a given GWA dataset is entirely determined by the allele frequency distribution across the genome under the assumptions that i) all markers in the dataset are independent, ii) the genetic effect is correctly estimated, iii) the GWA analysis accounts for population structure, iv) the number of pseudo-markers are fixed, and v) the sample size is fixed. Assumption iii)—v) generally hold for a GWA dataset and violations of these will generally be rare. There will, however, often be considerable LD between the analyzed markers, leading to a conservative estimate of the false-positive rate as the number of effective, independent markers is lower than the total number of markers accounted for. As the statistical approaches used to estimate genetic effects in GWA analyses are generally unbiased, no systematic violation of assumption ii) is expected. However, if the precision in the genetic estimates is low the estimate of the false positive rate obtained from this method will be decreased.
High-order LD between epistatic pseudo markers and whole-genome sequencing variants
From 728 whole-genome sequences in A. thaliana 1001 Genomes Project (http://www.1001genomes.org), we extracted all the sequencing variants. All four significant pseudo-markers had at least four accessions with the double-recessive genotype (i.e. the minor allele for the epistatic pseudo-marker) in the 728 sequenced accessions. For each of the pseudo-markers, we therefore sampled 93 accessions from the 728 sequenced ones, keeping the same allele frequency as for the pseudo-marker representing the epistatic pair detected in the GWA dataset, and obtained the genome-wide, high-order LD r2 distribution across all the sequenced variants. This procedure was repeated 50 times for each pseudo-marker, and we calculated the estimates and standard errors of the r2mean, r2max and estimated the risk for “apparent epistasis” as the probability of observing an r2max > 0.8 in a particular random sample.
Examination of SNP-associated genes
The Ensembl Variant Effect Predictor based on the TAIR10 release of the A. thaliana genome was used to determine the effects of the leading SNPs and the SNPs in high LD with them. Genes were considered as candidates if they were within 1kb of a variant. Expression of the candidate genes was determined using the BAR eFP Arabidopsis browser [44].
Validation of interacting loci
T-DNA lines were obtained for the candidate genes (S2 Table). Root length was ascertained as described above (n = 20). Tukey’s HSD post hoc test was used to compare root lengths between the T-DNA lines and the wild-type accession (Col-0).
Supporting Information
Zdroje
1. Huang W, Richards S, Carbone MA, Zhu D, Anholt RRH, Ayroles JF, et al. Epistasis dominates the genetic architecture of Drosophila quantitative traits. Proc Natl Acad Sci U S A. 2012;109 : 15553–9. doi: 10.1073/pnas.1213423109 22949659
2. Mackay TFC. Epistasis and quantitative traits: using model organisms to study gene-gene interactions. Nat Rev Genet. Nature Publishing Group, a division of Macmillan Publishers Limited. All Rights Reserved.; 2014;15 : 22–33. Available: http://dx.doi.org/10.1038/nrg3627
3. Nelson RM, Pettersson ME, Li X, Carlborg Ö. Variance Heterogeneity in Saccharomyces cerevisiae Expression Data: Trans-Regulation and Epistasis. PLoS One. Public Library of Science; 2013;8: e79507.
4. Queitsch C, Carlson KD, Girirajan S. Lessons from model organisms: phenotypic robustness and missing heritability in complex disease. PLoS Genet. 2012/11/21 ed. Public Library of Science; 2012;8: e1003041. doi: 10.1371/journal.pgen.1003041 PGENETICS-D-12-00749 [pii] 23166511
5. Hill WG, Goddard ME, Visscher PM. Data and theory point to mainly additive genetic variance for complex traits. Mackay TFC, editor. PLoS Genet. Public Library of Science; 2008;4: e1000008. doi: 10.1371/journal.pgen.1000008
6. Visscher PM, Brown MA, McCarthy MI, Yang J. Five years of GWAS discovery. Am J Hum Genet. 2012;90 : 7–24. doi: 10.1016/j.ajhg.2011.11.029 22243964
7. Goodnight CJ. Population Differentiation and the Transmission of Density Effects between Generations. Evolution (N Y). Society for the Study of Evolution; 1988;42 : 399–403 CR–Copyright © 1988 Society for th. 10.2307/2409244
8. Goodnight CJ. Quantitative trait loci and gene interaction: the quantitative genetics of metapopulations. Heredity (Edinb). Nature Publishing Group; 2000;84 : 587–598.
9. Whitlock MC, Phillips PC, Moore FB-G, Tonsor SJ. Multiple fitness peaks and epistasis. Annu Rev Ecol Syst. JSTOR; 1995; 601–629.
10. Eitan Y, Soller M. Selection induced genetic variation. Evolutionary theory and processes: Modern horizons. Springer; 2004. pp. 153–176.
11. Le Rouzic A, Siegel PB, Carlborg Ö. Phenotypic evolution from genetic polymorphisms in a radial network architecture. BMC Biol. BioMed Central Ltd; 2007;5 : 50.
12. Le Rouzic A, Carlborg Ö. Evolutionary potential of hidden genetic variation. Trends Ecol Evol. Elsevier; 2008;23 : 33–37.
13. Monnahan PJ, Kelly JK. Epistasis Is a Major Determinant of the Additive Genetic Variance in Mimulus guttatus. Carlborg Ö, editor. PLOS Genet. 2015;11: e1005201. doi: 10.1371/journal.pgen.1005201 25946702
14. Carlborg O, Haley CS. Epistasis: too often neglected in complex trait studies? Nat Rev Genet. Nature Publishing Group; 2004;5 : 618–25. doi: 10.1038/nrg1407
15. Mackay TF. The genetic architecture of quantitative traits. Annu Rev Genet. Annual Reviews 4139 El Camino Way, P.O. Box 10139, Palo Alto, CA 94303–0139, USA; 2001;35 : 303–39. doi: 10.1146/annurev.genet.35.102401.090633 11700286
16. Rowe HC, Hansen BG, Halkier BA, Kliebenstein DJ. Biochemical networks and epistasis shape the Arabidopsis thaliana metabolome. Plant Cell. 2008;20 : 1199–216. doi: 10.1105/tpc.108.058131 18515501
17. Pyun J-A, Kim S, Cha DH, Kwack K. Epistasis between polymorphisms in TSHB and ADAMTS16 is associated with premature ovarian failure. Menopause (New York, NY). 2013;
18. Sapkota Y, Mackey JR, Lai R, Franco-Villalobos C, Lupichuk S, Robson PJ, et al. Assessing SNP-SNP interactions among DNA repair, modification and metabolism related pathway genes in breast cancer susceptibility. PLoS One. Public Library of Science; 2013;8: e64896.
19. Vanhaeren H, Gonzalez N, Coppens F, De Milde L, Van Daele T, Vermeersch M, et al. Combining growth-promoting genes leads to positive epistasis in Arabidopsis thaliana. Elife. eLife Sciences Publications Limited; 2014;3: e02252. doi: 10.7554/eLife.02252
20. Carlborg Ö, Jacobsson L, Åhgren P, Siegel P, Andersson L. Epistasis and the release of genetic variation during long-term selection. Nat Genet. Nature Publishing Group; 2006;38 : 418–420.
21. Carlborg Ö, Andersson L, Kinghorn B. The use of a genetic algorithm for simultaneous mapping of multiple interacting quantitative trait loci. Genetics. Genetics Soc America; 2000;155 : 2003–2010.
22. Cao J, Schneeberger K, Ossowski S, Günther T, Bender S, Fitz J, et al. Whole-genome sequencing of multiple Arabidopsis thaliana populations. Nat Genet. Nature Publishing Group; 2011;43 : 956–963.
23. Mackay TFC, Richards S, Stone EA, Barbadilla A, Ayroles JF, Zhu D, et al. The Drosophila melanogaster genetic reference panel. Nature. Nature Publishing Group; 2012;482 : 173–178.
24. Gibson G. Rare and common variants: twenty arguments. Nat Rev Genet. Nature Publishing Group; 2012;13 : 135–145. doi: 10.1038/nrg3118
25. Hemani G, Shakhbazov K, Westra H-J, Esko T, Henders AK, McRae AF, et al. Detection and replication of epistasis influencing transcription in humans. Nature. Nature Publishing Group; 2014;
26. Horton MW, Hancock AM, Huang YS, Toomajian C, Atwell S, Auton A, et al. Genome-wide patterns of genetic variation in worldwide Arabidopsis thaliana accessions from the RegMap panel. Nat Genet. Nature Publishing Group; 2012;44 : 212–216.
27. Atwell S, Huang YS, Vilhjalmsson BJ, Willems G, Horton M, Li Y, et al. Genome-wide association study of 107 phenotypes in Arabidopsis thaliana inbred lines. Nature. 2010/03/26 ed. 2010;465 : 627–631. 20336072
28. Filiault DL, Maloof JN. A genome-wide association study identifies variants underlying the Arabidopsis thaliana shade avoidance response. PLoS Genet. Public Library of Science; 2012;8: e1002589. doi: 10.1371/journal.pgen.1002589
29. Meijón M, Satbhai SB, Tsuchimatsu T, Busch W. Genome-wide association study using cellular traits identifies a new regulator of root development in Arabidopsis. Nat Genet. Nature Publishing Group, a division of Macmillan Publishers Limited. All Rights Reserved.; 2014;46 : 77–81. doi: 10.1038/ng.2824
30. Slovak R, Göschl C, Su X, Shimotani K, Shiina T, Busch W. A Scalable Open-Source Pipeline for Large-Scale Root Phenotyping of Arabidopsis. Plant Cell. 2014;26 : 2390–2403. doi: 10.1105/tpc.114.124032 24920330
31. Rosas U, Cibrian-Jaramillo A, Ristova D, Banta JA, Gifford ML, Fan AH, et al. Integration of responses within and across Arabidopsis natural accessions uncovers loci controlling root systems architecture. Proc Natl Acad Sci U S A. 2013;110 : 15133–8. doi: 10.1073/pnas.1305883110 23980140
32. Wood AR, Tuke MA, Nalls MA, Hernandez DG, Bandinelli S, Singleton AB, et al. Another explanation for apparent epistasis. Nature. Nature Publishing Group; 2014;514: E3–E5.
33. Fujikura U, Horiguchi G, Ponce MR, Micol JL, Tsukaya H. Coordination of cell proliferation and cell expansion mediated by ribosome‐related processes in the leaves of Arabidopsis thaliana. Plant J. Wiley Online Library; 2009;59 : 499–508.
34. Sangster TA, Salathia N, Undurraga, Milo R, Schellenberg K, Lindquist SL, et al. HSP90 affects the expression of genetic variation and developmental stability in quantitative traits. Proc Natl Acad Sci U S A. 2008/02/22 ed. 2008;105 : 2963–2968. doi: 10.1073/pnas.0712200105 18287065
35. Lempe J, Lachowiec J, Sullivan AM, Queitsch C. Molecular mechanisms of robustness in plants. Curr Opin Plant Biol. 2013/01/03 ed. 2012; S1369-5266(12)00172-0 [pii] doi: 10.1016/j.pbi.2012.12.002
36. Geiler-Samerotte K, Bauer C, Li S, Ziv N, Gresham D, Siegal M. The details in the distributions: why and how to study phenotypic variability. Curr Opin Biotechnol. 2013;24 : 752–9. doi: 10.1016/j.copbio.2013.03.010 23566377
37. Rönnegård L, Shen X, Alam M. hglm: A Package for Fitting Hierarchical Generalized Linear Models. R J. 2010;2.
38. Aulchenko YS, Ripke S, Isaacs A, Van Duijn CM. GenABEL: an R library for genome-wide association analysis. Bioinformatics. Oxford Univ Press; 2007;23 : 1294–1296.
39. Shen X, Alam M, Fikse F, Rönnegård L. A novel generalized ridge regression method for quantitative genetics. Genetics. Genetics Soc America; 2013;193 : 1255–1268.
40. Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MAR, Bender D, et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet. Elsevier; 2007;81 : 559–575.
41. Kim S, Plagnol V, Hu TT, Toomajian C, Clark RM, Ossowski S, et al. Recombination and linkage disequilibrium in Arabidopsis thaliana. Nat Genet. Nature Publishing Group; 2007;39 : 1151–1155.
42. Shen X. Flaw or discovery? Calculating exact p-values for genome-wide association studies in inbred populations. bioRxiv. 2015; Available: http://biorxiv.org/content/early/2015/02/17/015339.abstract
43. Ossowski S, Schneeberger K, Clark RM, Lanz C, Warthmann N, Weigel D. Sequencing of natural strains of Arabidopsis thaliana with short reads. Genome Res. Cold Spring Harbor Lab; 2008;18 : 2024–2033.
44. Winter D, Vinegar B, Nahal H, Ammar R, Wilson G V, Provart NJ. An “Electronic Fluorescent Pictograph” browser for exploring and analyzing large-scale biological data sets. PLoS One. Public Library of Science; 2007;2: e718.
45. Sullivan AM, Arsovski AA, Lempe J, Bubb KL, Weirauch MT, Sabo PJ, et al. Mapping and Dynamics of Regulatory DNA and Transcription Factor Networks in A. thaliana. Cell Rep. 2014;8 : 2015–2030. doi: 10.1016/j.celrep.2014.08.019 25220462
46. Aeong Oh S, Park J-H, In Lee G, Hee Paek K, Ki Park S, Gil Nam H. Identification of three genetic loci controlling leaf senescence in Arabidopsis thaliana. Plant J. Blackwell Science Ltd; 1997;12 : 527–535. doi: 10.1046/j.1365-313X.1997.00489.x
47. Jack T. Molecular and genetic mechanisms of floral control. Plant Cell. 2004;16 Suppl: S1–17. doi: 10.1105/tpc.017038 15020744
48. Sohn EJ, Rojas-Pierce M, Pan S, Carter C, Serrano-Mislata A, Madueño F, et al. The shoot meristem identity gene TFL1 is involved in flower development and trafficking to the protein storage vacuole. Proc Natl Acad Sci U S A. 2007;104 : 18801–6. doi: 10.1073/pnas.0708236104 18003908
49. Larsson AS, Landberg K, Meeks-Wagner DR. The TERMINAL FLOWER2 (TFL2) Gene Controls the Reproductive Transition and Meristem Identity in Arabidopsis thaliana. Genetics. 1998;149 : 597–605. Available: http://www.genetics.org/content/149/2/597.full 9611176
50. Bolle C, Huep G, Kleinbölting N, Haberer G, Mayer K, Leister D, et al. GABI-DUPLO: a collection of double mutants to overcome genetic redundancy in Arabidopsis thaliana. Plant J. 2013;75 : 157–71. doi: 10.1111/tpj.12197 23573814
51. Jung JKH, McCouch S. Getting to the roots of it: Genetic and hormonal control of root architecture. Front Plant Sci. Frontiers; 2013;4 : 186. doi: 10.3389/fpls.2013.00186
52. Ajjawi I, Lu Y, Savage LJ, Bell SM, Last RL. Large-scale reverse genetics in Arabidopsis: case studies from the Chloroplast 2010 Project. Plant Physiol. 2010;152 : 529–40. doi: 10.1104/pp.109.148494 19906890
53. Chan EKF, Rowe HC, Corwin JA, Joseph B, Kliebenstein DJ. Combining genome-wide association mapping and transcriptional networks to identify novel genes controlling glucosinolates in Arabidopsis thaliana. PLoS Biol. Public Library of Science; 2011;9: e1001125. doi: 10.1371/journal.pbio.1001125
54. Schneider CA, Rasband WS, Eliceiri KW. NIH Image to ImageJ: 25 years of image analysis. Nat Methods. 2012;9 : 671–675. 22930834
Štítky
Genetika Reprodukční medicínaČlánek vyšel v časopise
PLOS Genetics
2015 Číslo 9
- Kazuistika – Perspektivy využití precizované medicíny v rámci personalizované specifické terapie onkologických pacientů
- Nobelova cena za chemii pro genetické nůžky: Objev, který změní naši budoucnost?
- Technologie na bázi RNA v klinické praxi: od přebarvených petúnií k terapii vzácných a dosud jen obtížně léčitelných chorob u lidí
- „Nepředstavovali jsme si, že náš výzkum povede přímo ke vzniku nových léků, dokonce ještě za našeho života“
- Bezplatné služby pro diagnostiku ATTRv amyloidózy pro kardiology
Nejčtenější v tomto čísle
- Arabidopsis AtPLC2 Is a Primary Phosphoinositide-Specific Phospholipase C in Phosphoinositide Metabolism and the Endoplasmic Reticulum Stress Response
- Bridges Meristem and Organ Primordia Boundaries through , , and during Flower Development in
- KLK5 Inactivation Reverses Cutaneous Hallmarks of Netherton Syndrome
- XBP1-Independent UPR Pathways Suppress C/EBP-β Mediated Chondrocyte Differentiation in ER-Stress Related Skeletal Disease
Zvyšte si kvalifikaci online z pohodlí domova
Mazová zátka a její řešení
nový kurzVšechny kurzy