
Web-Based, Participant-Driven Studies Yield Novel Genetic Associations for Common Traits
Despite the recent rapid growth in genome-wide data, much of human variation remains entirely unexplained. A significant challenge in the pursuit of the genetic basis for variation in common human traits is the efficient, coordinated collection of genotype and phenotype data. We have developed a novel research framework that facilitates the parallel study of a wide assortment of traits within a single cohort. The approach takes advantage of the interactivity of the Web both to gather data and to present genetic information to research participants, while taking care to correct for the population structure inherent to this study design. Here we report initial results from a participant-driven study of 22 traits. Replications of associations (in the genes OCA2, HERC2, SLC45A2, SLC24A4, IRF4, TYR, TYRP1, ASIP, and MC1R) for hair color, eye color, and freckling validate the Web-based, self-reporting paradigm. The identification of novel associations for hair morphology (rs17646946, near TCHH; rs7349332, near WNT10A; and rs1556547, near OFCC1), freckling (rs2153271, in BNC2), the ability to smell the methanethiol produced after eating asparagus (rs4481887, near OR2M7), and photic sneeze reflex (rs10427255, near ZEB2, and rs11856995, near NR2F2) illustrates the power of the approach.
Published in the journal:
. PLoS Genet 6(6): e32767. doi:10.1371/journal.pgen.1000993
Category:
Research Article
doi:
https://doi.org/10.1371/journal.pgen.1000993
Summary
Despite the recent rapid growth in genome-wide data, much of human variation remains entirely unexplained. A significant challenge in the pursuit of the genetic basis for variation in common human traits is the efficient, coordinated collection of genotype and phenotype data. We have developed a novel research framework that facilitates the parallel study of a wide assortment of traits within a single cohort. The approach takes advantage of the interactivity of the Web both to gather data and to present genetic information to research participants, while taking care to correct for the population structure inherent to this study design. Here we report initial results from a participant-driven study of 22 traits. Replications of associations (in the genes OCA2, HERC2, SLC45A2, SLC24A4, IRF4, TYR, TYRP1, ASIP, and MC1R) for hair color, eye color, and freckling validate the Web-based, self-reporting paradigm. The identification of novel associations for hair morphology (rs17646946, near TCHH; rs7349332, near WNT10A; and rs1556547, near OFCC1), freckling (rs2153271, in BNC2), the ability to smell the methanethiol produced after eating asparagus (rs4481887, near OR2M7), and photic sneeze reflex (rs10427255, near ZEB2, and rs11856995, near NR2F2) illustrates the power of the approach.
Introduction
Many common human traits have long been understood to have a genetic basis, yet in only a few cases have influential genes been identified. Even pigmentation, for which almost 40 years ago Cavalli-Sforza [1] estimated that there were four genes underlying variation, has yielded associations only recently [2]–[5] (showing that pigmentation is rather polygenic [6]). We have conducted, within a novel, web-based research framework, genome-wide association studies of 22 common human traits. These traits were selected based on indications of heritability or a simple mode of inheritance, ease of phenotype data collection via web-based self-report, and broad interest.
Data for these studies was collected within a research framework wherein research participants, derived from the customer base of 23andMe, Inc., a direct-to-consumer genetic information company, consented to the use of their data for research and were provided with access to their personal genetic information (Figure 1). They were then given the option of contributing phenotype data via a series of web-based surveys. The result is a single, continually expanding cohort, containing a self-selected set of individuals who participate in multiple studies in parallel.

The parallel and continual nature of this research framework facilitates the rapid recruitment of participants to many studies at once. Furthermore, the presentation of interpreted genetic data to the participants creates incentive for them to return to the website, lowering the marginal cost of recontacting for additional analyses. The participant-driven nature of this study design and the resulting heterogeneity of the data sets require that care be taken to eliminate population stratification and other possible sources of bias. However, the challenges of eliminating such stratification and biases are balanced by the continuous accrual of new data as participants sign up and respond to new surveys.
From the initial set of surveys released, we report results on the 22 traits meeting our sample size criteria (over 1500 unrelated northern European respondents with the additional requirement of at least 500 cases for binary traits). The phenotypes that met these criteria are described below.
Pigmentation
Pigmentation has been a fruitful area for genetic research since the 19th century, when scientists realized that the mice with varied coat colors that “mouse fanciers” had been developing for centuries provided easily tracked phenotypes for genetic analysis [7]. Many genetic variants underlying “normal” variation in human pigmentation have recently been discovered [2]–[5]. These variants account for a significant part of the known variation in pigmentation, (approximately 30% for hair color, 60% for eye color, see Results), but much remains unexplained.
Hair morphology
Human hair varies in thickness as well as in the extent of curl, which is related to the shape of the hair (round versus flat cross-section). Over 100 years ago Davenport and Davenport [8] reported a study of hair morphology in families, concluding that straight hair was recessive to curly hair. More recently, a candidate gene approach discovered that EDAR is associated with hair thickness in Asians [9].
Ability to smell the urinary metabolites of asparagus
The study of the ability to smell the urinary metabolites of asparagus (probably mostly methanethiol, a sulfur-containing compound) also dates back over 100 years [10]. Since then, authors have debated whether the variation among humans is in the ability to produce methanethiol (thought from family studies to be inherited in an autosomal dominant manner [10]) or in the ability to smell that compound [11]. No previous studies have reported genes or single nucleotide polymorphisms (SNPs) associated with this sensory ability.
Photic sneeze
Listed under “ACHOO (Autosomal-dominant Compelling Helio-Ophthalmic Outburst) syndrome” in Online Mendelian Inheritance in Man (OMIM), the “photic sneeze reflex” refers to the tendency to sneeze when moving from relative darkness into bright light—most often sunlight. Aristotle discussed the trait in a section of his Book of Problems called “Problems concerning the nose,” hypothesizing that heat-generated movement led to tickling of the nose. No previous studies have reported genes or SNPs associated with this particular reflex.
Other phenotypes
The other traits analyzed here fall into three broad categories. The first category consists of laterality preferences: handedness, footedness, ocular dominance, and hand-clasp (which thumb is on top when clasping one's hands). The second group consists of simple physical characteristics: whether participants have had cavities, have worn braces, have had wisdom teeth removed, have astigmatism, wear glasses, have attached earlobes, and suffer from motion sickness while riding in a car. The third group consists of personality traits and preferences: optimism, a preference for sweet versus salty food, and preference for night-time versus morning-time activity. None of these traits have well-established associations with SNPs, although handedness [12] and diurnal preference [13] have putative genetic associations.
Results
Of the 22 studies, eight yielded positive results, with novel associations discovered for four traits and replications for five traits (Table 1). All five replications are for pigmentation-related traits. The novel associations reveal SNPs associated with hair morphology, detection of a urinary metabolite of asparagus, photic sneeze reflex, and freckling. Manhattan and qqplots for the novel associations and replications are shown in Figure 2, Figure 3, and Figure 4.




The studies were performed on multiple overlapping datasets drawn from a single cohort. The cohort was derived from the subset of the customer base of 23andMe, Inc. who took surveys relevant to the 22 traits considered here. Of these individuals, only those assessed to be of northern European ancestry were included. In addition, individuals were eliminated until any pair of participants shared at most 700 cM of full or half identity by descent (IBD), approximately the lower end of sharing between a pair of first cousins. Average IBD between a pair of participants was 0.146cM, median IBD was 0 and only 123 pairs of individuals shared more than 100 cM. The resulting cohort consisted of a total of 9126 individuals who had answered at least one of the surveys considered here. Each individual was genotyped on the Illumina HumanHap550+ BeadChip platform (consisting of the HumanHap550 panel along with a custom set of approximately SNPs selected by 23andMe). After quality control (see Methods), SNPs were used from this platform.
Phenotypes were collected using 13 surveys posted on the 23andMe website. From these surveys, 22 traits met our criteria for inclusion, which required over unrelated participants who responded to the relevant survey questions and were assessed to be of northern European origin. In addition, for binary phenotypes we required at least participants with each outcome before analysis. See Text S5 for full descriptions of the phenotypes.
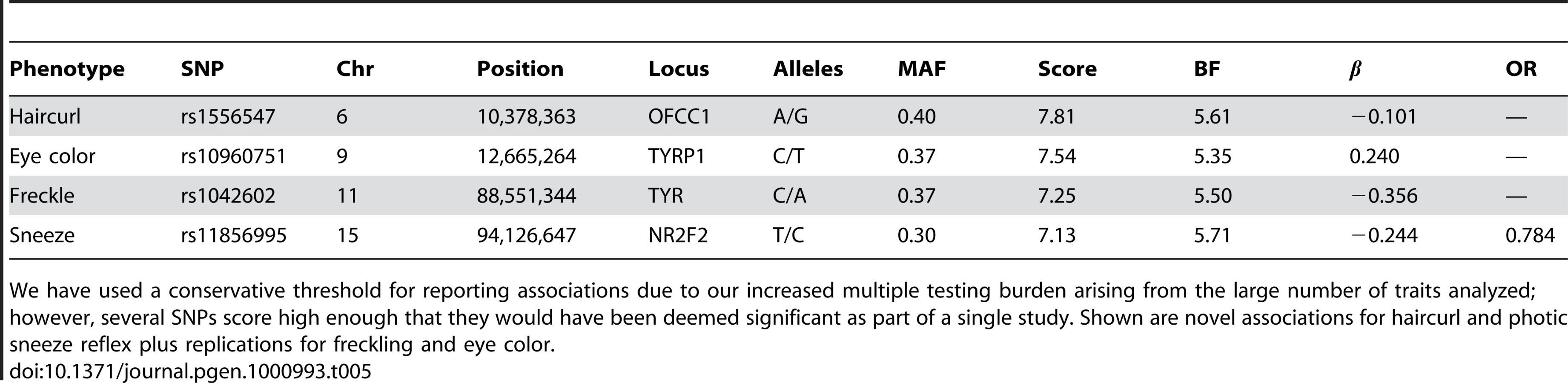
Detailed summaries of results are shown in Table 2, Table 3, and Table 4. These summaries include the SNPs selected within each associated region to give the best predictive model while attempting not to over-fit (using a stepwise regression approach with the AIC, see Methods). The reader should be warned that this approach is anti-conservative about the number of effects fitted and, in particular, all SNPs appearing in these tables are not necessarily independently associated. Throughout, “score” refers to the negative p-value for the association between a SNP and a trait. We also include Bayes factors (see Methods) in the tables and the plots of imputed and genotyped SNPs within each associated region due to their usefulness in comparing associations and their ability to incorporate uncertainty arising from imputation. Because we performed multiple (22) parallel studies, we used a very conservative threshold of for a SNP before it was claimed to reach genome-wide significance (see Methods). Associations significant under this correction for a single study but not for all studies (that is, with scores between and ) are called “suggestive” and are shown in Table 5.

Phenotype data
The collection of a broad range of data from each participant allows us to control for some sources of bias and to assess the error rate of the phenotype collection.
To control for sources of bias, phenotypes were checked for correlations with a set of covariates (age, sex, and principal components of population variation). Covariates showing significant correlations (at the level) were included in the analysis (Supplementary Table 2 in Text S4).
In addition, by asking participants the same question multiple times in different ways, we were able to assess the repeatability of responses. We asked about eye color, hair color, freckles, handedness and age twice each in different places or ways. A total of 177 people were removed from analysis based on a single discordant answer to one of these questions. Overall, a total of only 0.72% of participants answered any pair of these questions inconsistently.
One source of bias unique to our replication studies was the fact that participants were shown their genetic data along with analyses of their data for approximately 100 traits and diseases. In some cases, this led to a severe bias. For example, a survey examining perceived performance in sprint versus long-distance races was placed on a web page within 23andme.com where customers were shown their genotype for rs1815739 (a SNP in ACTN3 [14]). If they logged on before their genotype data had been processed, they saw the survey question alongside sample data. If their data was available, they were predicted to fall in a category including either world-class sprinters (carriers of the C allele) or endurance athletes (T homozygotes). The response distribution differed significantly () between respondents who had seen their genotypes with the suggested outcome versus those who hadn't. The results (Supplementary Table 1 in Text S5) of this comparison are consistent with large fractions (24.2% of C carriers, 41.2% of T homozygotes) of respondents answering differently than they would have if they had not seen their genotype data and interpretation.
Six of the 13 surveys were posted on pages where customers were shown their genotypes and predictions for related conditions. Due to the possibility of bias from this prediction, primary analysis of these six surveys considered only those participants who took the surveys before receiving their genetic data (so they only saw a sample prediction for the phenotype). As a result, none of these traits made our sample size cutoff.
For the 22 phenotypes considered here, participants were shown predictions for hair color, eye color, and freckling, although they were on separate pages from the surveys for these phenotypes. There was no evidence that for any of these traits participants who saw their genotypes gave different responses from those who did not (Methods). Therefore, we did not restrict attention to only those who hadn't seen their genotypes.
Survey response rates correlated with sex, age and the first (north-to-south) principal component of population structure. That is, women, people of northern European ancestry, and older people were more likely to answer more surveys than men, people of central European ancestry, and younger people (p-values , , and ), respectively. A genome-wide association study (GWAS) using the number of surveys answered as the trait analyzed did not show any significant associations (with p-values under ) when these covariates were taken into account.
Hair curl
We found regions associated with hair curl near the genes TCHH, LCE3E and WNT10A, as well as a region suggestively associated near OFCC1.
We found an association between a SNP near TCHH, rs17646946 and hair curl, with score 41.8, see Figure 5 and Table 6. The minor allele is associated with straighter hair, with each A conferring a reduction in curliness of about 0.29 points on a scale from 0 to 5. There is evidence of a second, possibly independent, association in this region: the SNP rs499697, about 430kb away near LCE3E, has a score of 9.9. Here the minor, derived allele is associated with curlier hair, 0.13 points per G. These SNPs lie in the epidermal differentiation complex, which contains a large number of genes required for late epidermal differentiation. Many of these genes are involved in the production of the cornified envelope (CE), the highly cross-linked outermost layer of skin that provides mechanical protection from the environment, or are involved in cross-linking the CE with the network of keratin filaments in the cells.


The LD block containing the most significant SNPs includes four genes: S100A11, TCHHL1 (trichohyalin-like 1), TCHH (trichohyalin), and RPTN (repetin). All four are putative calcium-binding proteins that contain two EF hand domains. S100A11, TCHH, and RPTN have all been shown to be associated with the CE [15]–[17]. Trichohyalin and repetin are both expressed at high levels in hair follicles—specialized epidermal structures that produce hair—specifically in the inner root sheath layer [17], [18].
We also found an association between rs7349332 and hair curl, with score 13.4, in an intron of WNT10A. The minor allele is associated with curly hair, each T is associated with a 0.2 point change. See Figure 6 and Table 7.


Finally, near OFCC1 (orofacial cleft candidate 1), rs1556547 has a score of 7.8 and the minor allele is associated with straighter hair (0.1 points per G, Table 8) and Figure 7.

Asparagus anosmia
Odorous urine after eating asparagus is thought to be due to the excretion of methanethiol, a volatile sulfur-containing compound that smells like rotten or boiling cabbage [19]. In mammals, odor detection is mediated through olfactory receptors (ORs), seven-transmembrane domain proteins that are expressed in the cell membranes of olfactory neurons and are responsible for detection of odorants. A number of ORs are known to have specific odor sensitivities, and account for some of the variation in an individual's ability to detect those odors [20].
We have found a region on chromosome 1 (Figure 8) containing a cluster of olfactory receptor genes that is significantly associated with the ability to smell asparagus metabolites. This region contains 39 OR genes (ten annotated as pseudogenes). The LD block that contains the most significant SNP found in this study rs4481887 (with a score of 23.21) includes ten genes, all olfactory receptors: OR2M2, OR2M3, OR2M4, OR2T33, OR2T12, OR2M7, OR5BF1, OR2T4, OR2T6, and OR2T1. Two of these (OR2M3, OR2T6) are annotated as pseudogenes in ORDB [21]. The most significant association, at rs4481887 (about 9kb upstream from OR2M7), has score 23.2 and appears to be acting in a dominant fashion decreasing the odds of anosmia, with an odds ratio under a dominant model of 0.48 (the odds ratio of 0.60 reported in Table 2 is under an additive model). See Table 9 for details.

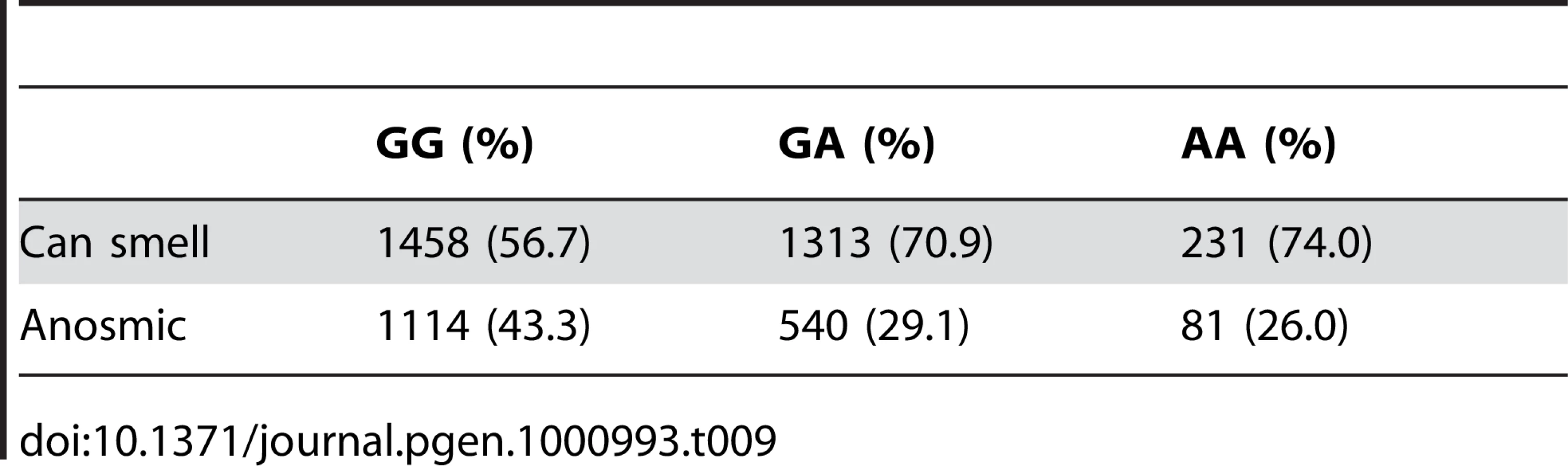
Another nearby SNP, rs7555310, with a similar odds ratio but slightly weaker score of 21.7, is a non-synonymous change in OR2M7. This SNP changes a valine to an alanine and is predicted to lie in one of the transmembrane domains of this protein. Though the valine is well conserved in mammals, the functional significance of this conservative amino acid change is not clear. Due to the extensive linkage disequilibrium in this region, it is impossible to tell without additional evidence which gene most likely codes for the receptor that detects this odorant.
Photic sneeze reflex
For photic sneeze reflex, we find a novel association with rs10427255 (score 10.9 and an OR of 1.32). This SNP lies in a large intergenic region of 2q22.3 between ZEB2 and (the annotated pseudogene) PABPCP2 (725kb and 1.2MB away, respectively).
We also find a suggestive association with rs11856995 (score 7.13 and OR of 0.78). It also lies in a large intergenic region of 15q26.2, with the nearest gene being NR2F2, some 560kb away. Details for the SNPs in these regions are shown in Figure 9, Table 10, and Table 11.



Freckling
We find one new association for freckling and replicate two known regions. The novel association is at rs2153271, in an intron of BNC2 (Zinc finger protein basonuclin-2), with a score of 9.4 and an estimated of −0.4 (on a 17 point scale). See Supplementary Table 2 in Text S6 for details.
Our most significant association, rs12203592, with score 90.7, lies in an intron in IRF4 (Figure 10). This SNP was previously associated with hair color, eye color, and tanning response to sunlight [5]. A more mildly associated SNP, rs1540771 (with score 13.2), in this region has previously been associated with freckling (as well as eye color, sensitivity to sun, and hair color) [4], however rs12203592 (60kb away) was not typed in that analysis. For eye and hair color and tanning ability it was suggested [5] that in fact rs12203592 was in closer LD with the causal SNP. Here we confirm this finding for hair and eye color and establish the same for freckling.

The other loci we associate with freckling are MC1R, ASIP, and TYR, all known associations [2], [22]. Although the SNPs selected by the regression procedure as most influential are slightly different than those for red hair, the sets are quite similar for these highly correlated phenotypes.
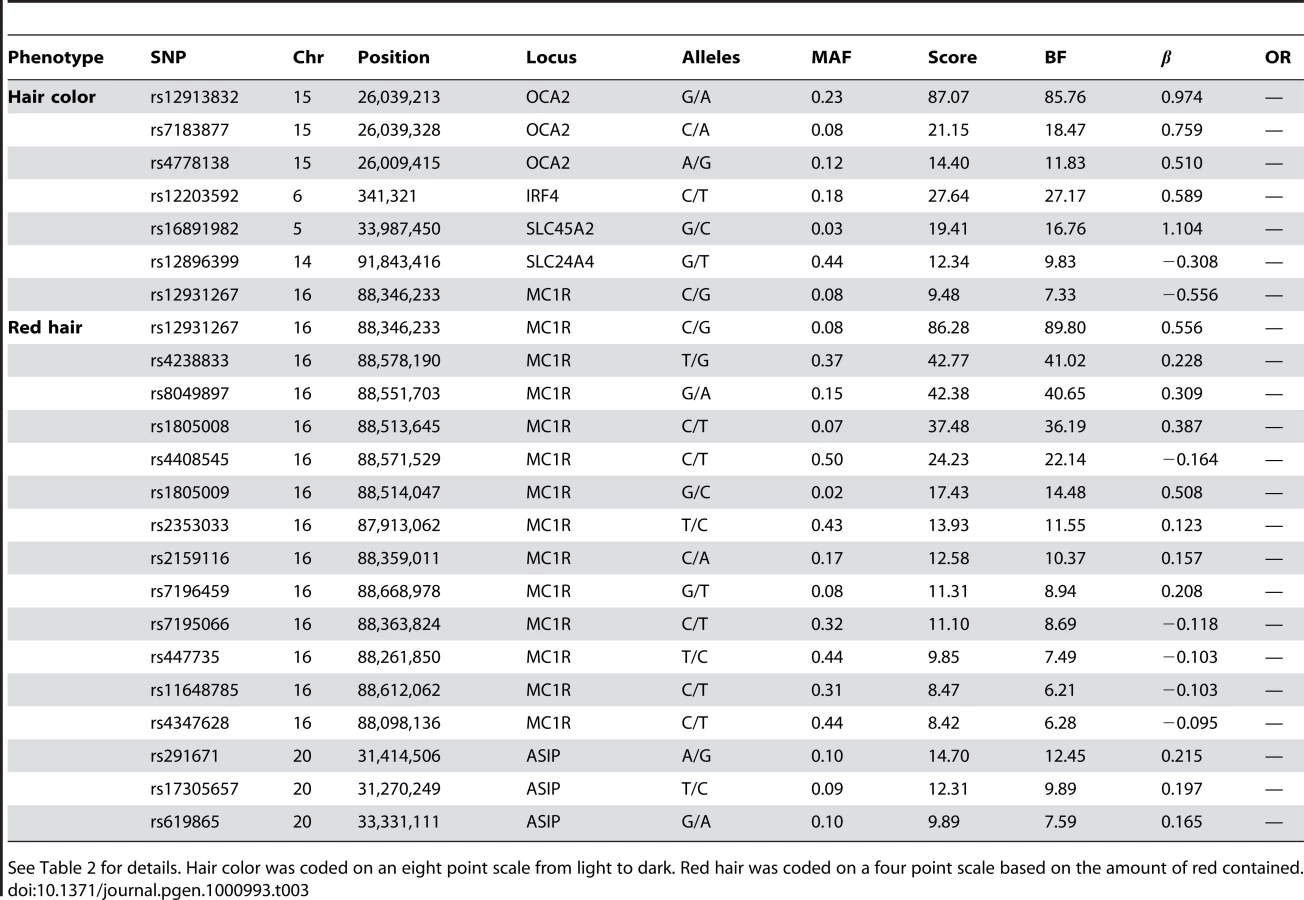
Hair color
We confirm known associations for hair color, both blond to brown and non-red to red. For blond to brown, excluding red, we find hits in five regions: OCA2/HERC2, IRF4, SLC24A4, SLC45A2, and MC1R (aside from MC1R, the same set of regions as [5] in their analysis excluding red hair). A multiple regression using the seven SNPs in Table 3 (with sex and five principal components) estimates that these five regions together explain about 28.1% of the variance in hair color (blond to brown) within northern Europe.
In the OCA2/HERC2 region, rs12913832, first found by [3], has a score of and of , explaining % of the variance. These numbers (as well as those for the other SNPs) concord well with those in [5] (which estimated % of the variance was explained by this SNP and using a five point scale from dark to light as compared to our eight point scale from light to dark). For IRF4, rs12203592 has an estimated of 0.59 and explains 3.9% of the variance. For SLC24A4, rs12896399 has an estimated of and explains 1.7% of the variance. In SLC45A2, rs16891982 has and explains % of the variance. Finally, rs12931267 near MC1R has of and explains % of the variance.
Sulem et al. [4] found associations for hair color in four of these five regions (excluding SLC45A2) as well as KITLG. The SNP rs12821256 in KITLG showed a mild but significant association with hair color in our study, with a score of 4.2 and of (95% CI from to ). This is similar to the relatively weak effect for this SNP found in [5].
For the other direction of variation in hair color (red versus non-red hair) we found many associated SNPs in the MC1R region, long known to be associated with this phenotype [2]. Although some of the SNPs contributing to the model in this region lie far from MC1R, some of the biggest effects are from rs1805008 and rs1805009, non-synonymous changes in the MC1R gene. This region is strongly associated with common variation in red hair [4], [5]. We also replicated the claim that a large haplotype containing the pigmentation gene ASIP is associated with red hair (also associated with burning and freckling in [22]). While rs291671 is about 900kb away from ASIP, it appears to be tagging the same haplotype found there.
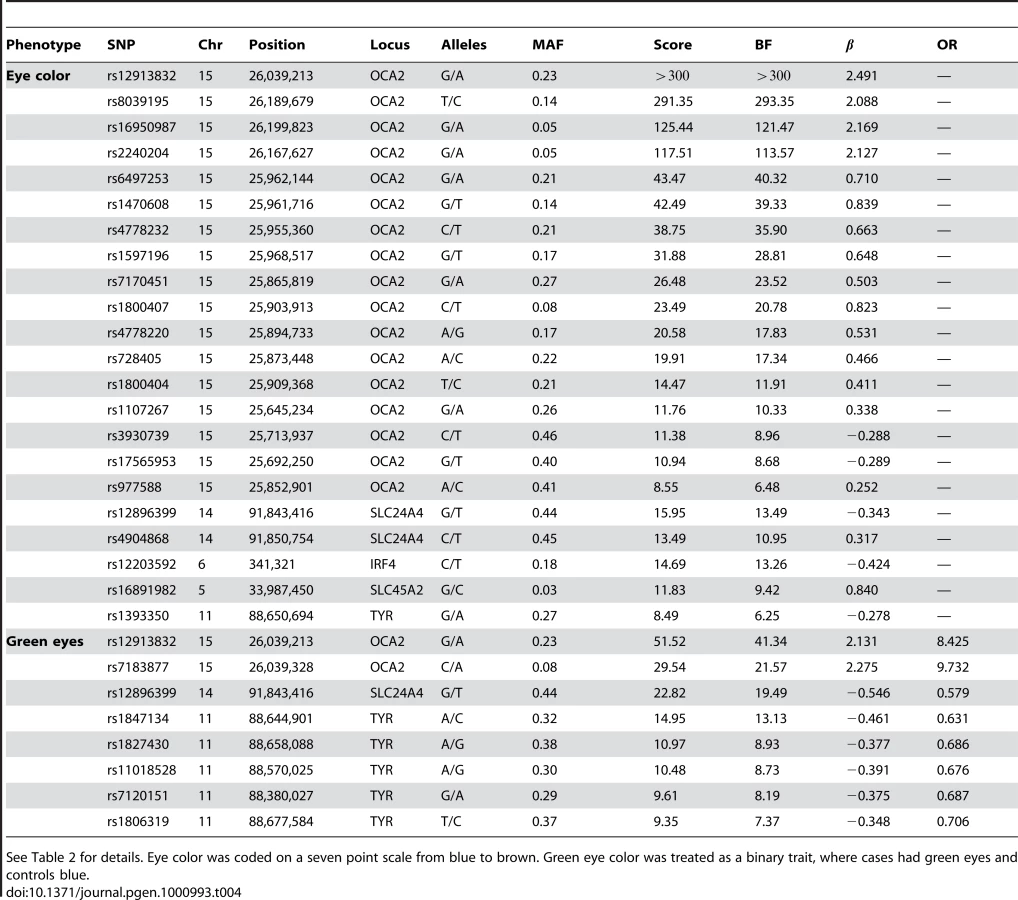
Eye color
We confirm known associations for each of two traits: blue to brown and green versus blue eye color (Table 4). For blue to brown, we confirm six regions: OCA2/HERC2, SLC24A4, IRF4, SLC45A2, TYR, and TYRP1. In HERC2, the well-known SNP rs12913832 has a score over 300 and of (thus the A allele is associated with darker eyes). This single SNP explains % of the variance in eye color. In SLC24A4, rs12896399 has a score of 15.9 and of , explaining 1.6% of the variance in eye color. In IRF4, rs12203592 has a score of 14.7 and of , explaining 1.4% of the variance. In SLC45A2, rs16891982 has a score of 11.8, of , and explains % of the variance. In TYR, rs1393350 has a score of 8.5, of , and explains % of the variance. Finally, as shown in Table 5, (as it does not quite meet our strict genome-wide significance levels), rs10960751 in TYRP1 has a score of 7.5, of , and explains % of the variance.
For green versus blue eyes, three regions show associations: OCA2/HERC2, SLC24A4, and TYR. For this trait, SNP rs12913832 in OCA2/HERC2 has a score of 51.5 and an estimated allelic OR of . The SNP rs1667394 in this same region has an estimated OR of (4.85–10.06), very close to the ORs in [4], which range from to in their three populations. In SLC24A4, rs12896399 has a score of 22.8 and OR of 0.58 (0.52–0.65), again similar to [4], where the ORs range from to . In TYR, we report rs1847134 with a score of . The nearby SNP rs1393350, which was reported to have ORs between and in Sulem et al. has an OR of 0.64 (0.57–0.72) in our data.
Discussion
We have conducted genome-wide association studies for 22 traits. The sheer size of this study was possible due to an original, web-based, parallel design. We have found novel associations for hair curl, freckling, photic sneeze reflex, and the ability to smell the urinary metabolites of asparagus. In addition, we have replicated a wide array of associations for pigmentation traits; these replications show great consistency with the numbers reported in other studies.
Associations
Hair curl
We have found associations between hair curl and SNPs near the genes TCHH, LCE3E, WNT10A, and OFCC1. that together explain about 6% of the variance in hair curl within northern Europe. The association with TCHH replicates the finding of [23] (which also mentions WNT10A as a non-significant but interesting association).
In the TCHH region, the strongly associated imputed SNP rs11803731 (in an exon of TCHH, causing the change M790L) is of note. This position is a possible helix initiator (between two prolines and a probable helix [24]), and differences in the ability to initiate the helix due to mutations at this position could lead to changes in protein behavior.
Experiments with in vitro cultures of curly and straight human hairs have shown that hair shape appears to be programmed from the basal area of the follicle, which includes the inner root sheath. Curly hairs originate from follicles that have a golf-club like bend at the base, while straight hairs originate from straight follicles [25]. Asymmetry in the thickness of the inner root sheath, which surrounds and provides protection for the growing hair at the base of the follicle, may play a role in moulding the shape of the hair [26]. Wool follicles from sheep also have a curved bulb, and exhibit an asymmetry in the thickness of trichohyalin containing structures, with more trichohyalin on the concave side [27]. Biochemical studies of the trichohyalin protein suggest that trichohyalin provides mechanical strength to the hair follicle by cross-linking the CE with the cytoplasmic keratin filament network in inner root sheath cells [28].
The bulk of this evidence points to TCHH as the most likely candidate for controlling hair curl in this region. However, due to the related nature of these genes, it is difficult to rule out S100A11, TCHHL1, or RPTN as playing a role. A second association 400kb away appears to be independent, but again there are many genes nearby (LCE3E, LCE5A, etc.) that could play a role.
For WNT10A, there appears to be a direct connection to hair morphology: mutations in this gene are known to cause odonto-onycho-dermal dysplasia, which includes dry, misformed hair as a symptom [29]. Also, WNT10A is upregulated in hair follicles at the beginning of a new growth cycle [30].
Finally, a translocation breakpoint in OFCC1 has been associated with orofacial clefting [31]. Orofacial clefting and ectodermal dysplasia can appear together, for example in EEC, Rapp-Hodgkin, and Hay-Wells syndromes [32].
Asparagus anosmia
It has been debated whether variance in the production or the detection of methanethiol explains the differences in the reporting of the ability to detect asparagus metabolites in urine. One study suggested that production is an autosomal dominant trait [10]; a second study concluded that the variation is instead in the ability to detect the compound and that it is a roughly bimodal trait with respect to the dilution at which the odor is detected [11].
We have identified a locus associated with this trait. This locus lies within a region containing many olfactory receptors and appears to act in a dominant fashion. Both of these facts suggest that the genetic variation in this trait is in the ability to detect the odorant.
Freckling
We have found a novel association between freckling and rs2153271 in an intron of BNC2. BNC2 is a potential transcriptional regulator in keratinocytes based on its close similarity to BNC1 (basonuclin 1) [33] (which is involved in keratinocyte proliferation), however there is evidence that BNC1 and BNC2 have different functions [34]. As the pigment that shows up in freckles is housed in keratinocytes, there could well be a link between BNC2 and freckling.
We have also found a strong association between rs12203592 in an intron of IRF4 and freckling. This region has previously been associated with freckling, however this SNP appears to more closely tag the causal variant than the previous association in this region [4]. Like many other genes associated with pigmentation, IRF4 appears to be regulated by MITF [35]. Also, there is a striking, sudden drop-off in significance around this SNP that does not appear to be due to the presence of any recombination hotspots nearby. There is evidence of substantial copy-number variation (CNV) in this region (cf. [36], [37]). Although we are unable to detect CNVs here, it could explain the LD pattern.
Hair color
We replicated many known associations for hair color, both blond to black and red versus non-red. Of interest is the fact that rs12821256 in KITLG, discovered in [4], does not have a large effect size either here or in [5]. This raises the question of whether the OR of 1.9 reported in [4] is an overestimate or whether the discordant results are due to differences in the populations studied (as Han et al. studied a U.S. population probably similar to our cohort while Sulem et al. studied Icelandic and Dutch populations).
Photic sneeze
There is evidence that photic sneeze reflex is genetic: Peroutka and Peroutka [38] concluded that this trait is inherited in an autosomal dominant fashion. We find one region associated with photic sneeze reflex about 725kb away from ZEB2 and a second suggestively associated about 550kb away from NR2F2.
ZEB2 is mutated in individuals with Mowat-Wilson syndrome, which has seizures as a common symptom. There may be a link between photosensitive epileptic seizures and photic sneeze reflex (triggered by a sudden switch from being dark-adjusted to light) [39], providing a possible link between this region and photic sneeze reflex.
NR2F2 (also known as COUP-TFII), also has a possible link to sneezing: it interacts with NR2F6 [40] and NR2F6 knockout mice show defects in the locus ceruleus (part of the brainstem) [41]. Certain stimulations cause signals to be sent to the brainstem to cause a sneeze; it is thought that photic sneeze reflex also progresses through this fashion [42], [43]. Also, the locus ceruleus is disrupted in Rett syndrome, which also has seizures as a common symptom [44], [45].
Handedness
Handedness has putative genetic associations [12] (an association found only in dyslexic siblings). The haplotype there associated with left-handedness (when paternally inherited) was at most moderately associated with left-handedness in our data (estimated OR of 1.17, 95% CI of 0.96–1.42, p-value of 0.06). However, we are underpowered to detect such a small OR in this fairly rare (8% frequency) haplotype.
Looking at the laterality measures (handedness, footedness, ocular-dominance, and hand-clasp) as a whole, there is no overlap between the marginal hits for any of these phenotypes: no SNP has a score of above 5 for more than a single one of these measures.
Research framework
In this initial set of results, we have shown parallel, web-based phenotype collection to be quick and reliable. The population structure present in the wider dataset makes statistical analysis more involved than in a typical GWAS, however it does not influence the results. Furthermore, this complex population structure facilitates studies of multiple ethnicities simultaneously. It also compels the development of robust methods for genetic research in populations reflecting the complexities of human populations.
This design has several statistical advantages over traditional studies. By centralizing many studies, we have the ability to avoid publication bias by reporting statistics on a large collection of independent association studies, including both positive and negative results. Such a bias is a concern [46]. For example, imagine that 20 separate groups each perform a GWAS on a phenotype with no true association. One of them will probably find a result by chance, and this will be the only result submitted and published. While false positives are unavoidable in a statistical test, we can reduce them by incorporating the total number of simultaneous trials into the multiple testing calculation. We thus formalize the notion of a significance and testing burden across multiple scans, rather than with respect to a single GWAS.
Ignoring linkage disequilibrium (i.e., if one assumes the approximately 10 million tests performed in this paper are all independent), one would expect to see one or two suggestive associations (with scores between 7.1 and 8.4) by chance in about half of all studies similar to ours. This is a conservative estimate; the false-discovery rate (FDR) analysis estimates a FDR of about 5.2% for a cutoff of 7.1, meaning that we would expect 5.2% of the associations with scores in this range to be false positives.
In addition, genotypes for cases and controls are collected and treated the same way, avoiding sources of bias (cf. [47]). In fact, an individual will typically be a case for several studies and a control for several others. This is an extension of the model used in [48], where controls were shared across seven studies.
This new research model raises interesting methodological questions. For example, since new participants join the study continuously, results are constantly changing. For this study, we chose to set an end date and inclusion criteria in advance to avoid possible bias due to choosing a stop date according to the latest results. However, it is an interesting problem to design a criteria for significance using a continually expanding cohort to replace the traditional design of phased data collection with discovery followed by replication. For example, Figure 11 shows the history of two SNPs from this study that both had scores over 8.4 at one point in time. Further data shows that one appears to have been a true positive and one a false positive.

While we have not formalized this notion in this paper, we note that the novel associations we report here have been steadily increasing in significance (cf. Figure 11A and Supplementary Figure 7 in Text S6) and that they have several other significant SNPs in the same LD block. These facts are strong evidence that these novel associations are not the result of some genotyping artifact.
Our research model makes possible studies that might be infeasible otherwise due to the low marginal cost of asking additional questions over the web and the speed of broadcasting recruitment messages in parallel online. This speed and flexibility allows us to easily study traits for which funding may not be readily available, such as asparagus anosmia.
We believe that providing participants with well-explained descriptions of their genetic data can substantially benefit genetic research as a whole. It is an opportunity to harness the public interest in genetics and make the participants a part of the study. This participation provides a wonderful chance to educate the public about genetics, statistics and research and to give something back to the individuals who contribute to genetic research.
Methods
Cohort
Participants were drawn from the customer base of 23andMe. After purchase, customers were shipped a kit for saliva collection, containing a bar-coded tube to be returned and a code to claim that kit online. They entered this code on the 23andme.com website, created an account, and agreed to a Consent and Legal Agreement. Upon signing up for 23andWe (the portion of the website that allows participants to enter phenotype data through a series of surveys), participants were reminded that they had consented to the use of survey responses for research.
The Consent and Legal Agreement stated that participants' genotype data and whatever phenotype data they entered would be used for internal research after being coded and stripped of individually identifying information (“anonymized”). Individually identifying information refers to personal information that is collected during purchase, such as name, credit card information, billing and shipping addresses, and contact information such as an email address or telephone number. The consent form stated that aggregate genetic data might be shared publicly (as it is in this paper). However, it provided that individual-level genetic data would not be shared with outside researchers without separate consent. For this study, all access to individual-level data occurred at 23andMe by full-time 23andMe employees. One author (IP) was working as a 23andMe consultant and did not access individual-level data. Another author with a secondary, non-23andMe affiliation (JM) was acting in her capacity as a 23andMe employee during her work on this study.
As part of the consent form, participants were told they could withdraw from all future research at any time by emailing 23andMe. This information was also present as a FAQ on the 23andMe website. A small number of customers have elected this option and those who did so before January 30, 2010 were not included in any analysis in this paper.
All anonymized data was placed in a secure research environment accessible only by 23andMe scientists. These scientists had no access to individually identifying information that was held separately at the company. The scientists also had no interaction with study participants.
To obtain formal recognition of this strict partitioning of the research, following consultation with the editors at PLoS, we sought and were granted an independent determination by a commercial Institutional Review Board (IRB) that this research did not involve human subjects under the Department of Health and Human Services definition, 45 CFR 46.102(f). This definition states that research performed on anonymized data with no contact between investigators and participants does not constitute research on human subjects. It is 23andMe policy that every scientist who obtains access to the restricted research environment first undergo online human subject assurance training made available by the Office for Human Research Protections (OHRP).
23andMe is committed to an ongoing evaluation of our process of Institutional Review and oversight of Consent as part of our commitment to protection of participant rights. There are significant novel challenges in this process relating to the evolution of policies concerning privacy of genetic data, the ongoing nature of our study, and the return of data to participants. Our study participants arguably have greater opportunity to review and consent to their involvement than most participants in genetic studies. However, they also have greater access to their own genetic data and hence to personal results that may impact their self-perception. We expect the definition of human subjects research to evolve along with standards for protecting individual identity and providing public access to GWAS results. We are continually evaluating our protocols with an external, AAHRPP accredited IRB in an effort to set the standard for web-based genetic studies.
Genotyping and SNP quality control
DNA extraction and genotyping were performed on saliva samples by National Genetics Institute (NGI), a CLIA licensed clinical laboratory and a subsidiary of Laboratory Corporation of America. Samples were genotyped on the Illumina HumanHap550+ BeadChip platform, which included SNPs from the standard HumanHap550 panel in addition to a custom set of about 25,000 SNPs selected by the 23andMe staff. Every sample that failed to reach 98.5% call rate was re-analyzed. Individuals whose analyses failed repeatedly were re-contacted by 23andMe customer service to provide additional samples, as is done for all 23andMe customers.
Two slightly different versions of the genotyping platform were used in this study. See Text S3 for details about the two versions and quality control measures used to eliminate a subset of poorly performing assays.
SNPs with a call rate under 98% were excluded from analysis, as were those with minor allele frequency under or a p-value for Hardy-Weinberg equilibrium (using the test from [49] within all the northern Europeans in the database) under . Both minor allele frequency and Hardy-Weinberg statistics were calculated within our dataset. Due to the two slightly different platforms in the analysis the no-call rate was calculated only among individuals genotyped on a given platform. However, all SNPs discussed in this paper are contained in the intersection of the two platforms. In addition, a total of 1553 SNPs with Mendelian discordance rates (the fraction of trios within the entire 23andMe customer database in which the called SNPs followed an impossible inheritance pattern) of at least 1% were discarded. In the end, SNPs were used with an average call rate per person on these SNPs of 99.91% and a median call rate of 99.97%.
Statistical analysis
All p-values were calculated using linear or logistic regressions as appropriate (or the corresponding score tests in the case of analyses without covariates). For linear regressions with covariates, we used a simple multilevel model: first we performed the regression of the phenotype solely on the covariates and then regressed the residuals against individual SNPs. This multilevel model is similar to the model in EIGENSTRAT [50]. In addition to being faster this multilevel model avoids multicollinearity. Regressions were performed using R [51], PLINK [52], [53], or internal software packages. The estimated regression coefficient for each SNP, denoted by throughout, refers to a coding of genotypes as 0, 1, 2 counting the number of minor alleles present. The strand used was determined from NCBI build 36 of the human genome. Codings for the phenotypes discussed are given below and in Text S5.
Bayes factors (shown in region plots and in Text S6) were calculated using the default prior in BIMBAM [54], [55]. Regions of interest were further analyzed by imputation against the phased HapMap CEU subset [56] using BIMBAM.
Manhattan and quantile-quantile plots were trimmed at a p-value of in order to better show the details and also since for extremely small p-values the standard approximations become less exact.
For the tables (e.g., Table 2), the set of significant SNPs was pared down within each region using a backwards stepwise regression procedure that attempted to minimize the AIC (Akaike's information criterion, using the step command in R). As input to this procedure, all SNPs within the region with p-values under were included and only those that contributed to the optimal model were displayed. Of particular note is that the displayed SNPs were not necessarily all significant upon correction for the other SNPs in that region, only that the AIC judged that a SNP usefully contributed to the joint model. See Table S1 for all SNPs in these studies with scores above 6.0.
Multiple testing
We give two estimates for the multiple testing burden over all analyses. Most conservatively, a Bonferroni correction that takes into account the number of SNPs tested and the number of phenotypes tested yields a score of corresponding to a significance level of 0.05 for all 22 studies simultaneously.
In order to estimate the chance that the suggestive associations are true positives, we calculated the false-discovery rate (FDR) [57] over the set of p-values for all 22 studies. For each study we excluded all SNPs within 100kb of a SNP with score over 8.4 from the FDR analysis (removing the “true positives” and most SNPs in LD with them from the analysis). The analysis concluded that a cutoff of 7.1 corresponds to an estimated FDR of 5.2% (meaning that 5.2% of the SNPs with scores between 7.1 and 8.4 would be expected to be false positives). A cutoff of 6.5 raises the FDR to 10.4% and a cutoff of 6.0 raises the FDR to 19.8%.
Analysis of related individuals
We measured identity by descent (IBD) for all pairs of participants using a novel algorithm that acts on unphased data by comparing homozygous calls in a window (Text S2). A set of “unrelated” participants was defined by requiring that no two individuals share over 700 cM IBD, counting both full (diploid) and half (haploid) levels of identity by descent. This level of relatedness (approximately 20% of the genome) corresponds approximately to the minimal expected sharing between first-cousins in an outbred population (Supplementary Figure 1 of Text S2).
Population stratification
Extensive population structure exists in the customer base as a whole, which includes individuals from around the world. This structure might yield spurious associations if not taken into account [50]. We selected a subset of individuals having northern European ancestry (including western Europe as well) using multi-dimensional scaling (MDS) and a support vector machine (SVM) trained on three datasets containing individuals of known ancestry. Two of these datasets were the 1043 HGDP-CEPH individuals [58] and 326 individuals of European ancestry from Illumina's iControlDB and Peter Gregersen. The third dataset consisted of several hundred customers who reported having four grandparents either of Ashkenazi descent or having lived in a single European country for several countries chosen to complement the existing datasets. See Text S1 for details.
Only unrelated (in the aforementioned sense) individuals from this subset were considered during the present association studies. Although the sample included only individuals of northern European ancestry, mild population structure still existed. Inspection of the eigenvalues showed that the first five principal components captured the majority of this structure (Supplementary Figure 2 of Text S1). Thus, to guard against spurious associations we included each individual's first five principal components as covariates in the regression model for those traits that showed association with the principal components. For each phenotype, we also computed genomic control inflation factors () [59]. They were quite close to unity for the adjusted models (Table 1). See Text S1 for details.
Phenotypes
Phenotype data was collected via 13 surveys administered to research participants via the 23andMe.com web site. See Figure 1 and Text S5 for further details.
Inclusion criteria
Due to the frequent release of new questions and the continual accumulation of responses, criteria for inclusion of genotype and phenotype data were established before the writing of this paper. We analyzed all phenotypes derived from the 13 surveys released between May and October of 2008 that met our criteria. Only responses and genotypes obtained before January 30, 2010 were used.
Our requirements for selection of phenotypes were as follows:
-
At least 1500 responses among unrelated northern Europeans.
-
For binary phenotypes, at least 500 cases.
-
For surveys that were displayed alongside genetic predictions, only respondents who answered before their data was ready were included.
-
For phenotypes with significant correlations with covariates, only respondents who had provided those covariates were included.
Twenty-two traits met these criteria, they came from the six surveys “Ten Things About You,” “Ocular Dominance,” “Handedness,” “Optimism,” “Ten More Things About You,” “Footedness” and “Pigmentation.” The phenotypes analyzed in the paper are described in detail below, see Text S5 for details on the others.
For the analysis of whether seeing genotypes influenced survey responses, we looked at SNPs that were reported to the customer as influencing five traits analyzed here: rs12896399 and rs1393350 (green eye color), rs12913832 (eye color), rs1805007 (red hair), rs1667394 (hair color), rs4778138 and rs1805007 (freckling). For each SNP, we tested whether seeing their data influenced their responses, controlling for their genotype at that SNP, sex, age, and five principal components. Unadjusted p-values (using a logistic regression) were all over 0.1 except for rs1667394 and hair color, which had a p-value of 0.02. After adjusting for the seven tests performed, we fail to reject the hypothesis that seeing the data did not influence people's responses.
Hair curl
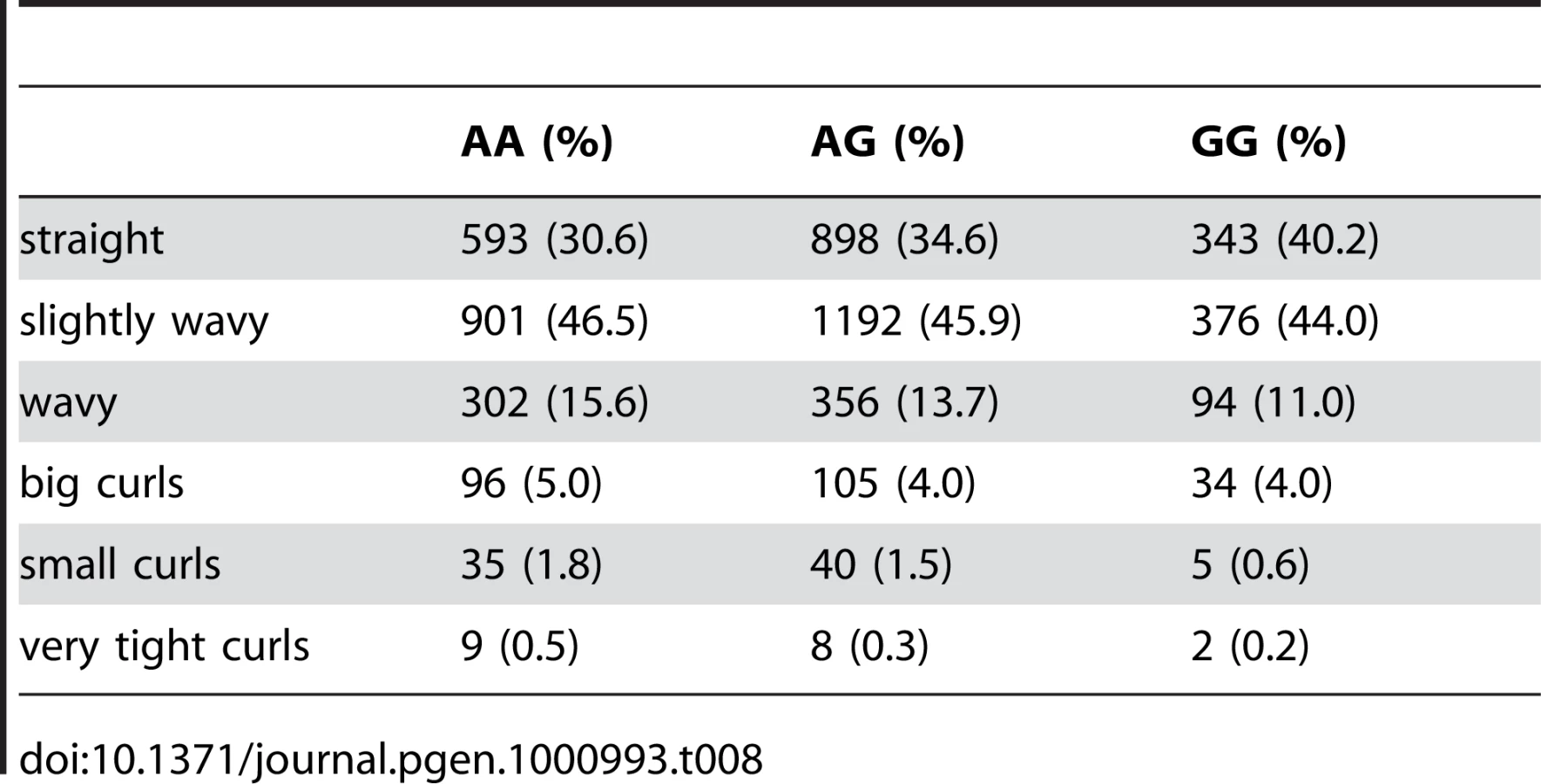
Participants were asked “Is your hair naturally straight or curly?” Answer choices were presented as a series of six pictures with accompanying descriptive text. Analysis used the codings (0 = “stick straight,” 1 = “Slightly wavy,” 2 = “Wavy,” 3 = “Big curls,” 4 = “Small curls,” 5 = “Very tight curls”) in a linear regression. The pictures are shown in Supplementary Figure 1 of Text S5.
Ability to smell the urinary metabolites of asparagus
The question asked was “Have you ever noticed a peculiar odor when you pee after eating asparagus?” This phenotype was scored as cases and controls where those who could not smell the odor after eating asparagus were considered cases. Participants who answered that they did not know or did not eat asparagus were excluded.
Freckling
Participants were asked to compare the amount of freckling on their face, arms, and shoulders to three series of images (Supplementary Figure 2 of Text S5). There were six images in the “arms” and “shoulders” categories and seven images in the “face” category. Each category was scored from zero to five or six and then the three categories were summed, leading to a score between zero and sixteen ranging from not-freckled to heavily freckled.
Hair color
We performed two analyses of hair color: blond to brown and red versus not red. For blond to brown, we regressed an ordinal coding (0 = blond, 1 = dark blond, 2 = light brown, 3 = reddish brown, 4 = medium brown, 5 = dark brown, 6 = black) for hair color on the ordinal coding for genotype (0, 1, 2) as well as five principal components and sex.
For red versus non-red hair color, participants were asked to “describe the amount of red in my hair (before I went gray, if I am gray now)” with available choices “No red at all,” “A tinge of red,” “Some red” and “A lot of red” which were coded from 0 to 3 in a linear regression.
Eye color
We performed two analyses of eye color: blue to brown and blue versus green. Eye color was assessed by asking participants to match their eye color to a set of 7 pictures (without accompanying text) ranging from blue to dark brown. These were coded as 0 = blue through 6 = dark brown for the main analysis. See Supplementary Figure 4 of Text S5 for the pictures.
For blue versus green eye color, blue eyes were treated as controls and greenish-blue or green eyes were treated as cases.
Photic sneeze reflex
Participants were asked one question for this trait: “Do you have a tendency to sneeze when exposed to bright sunlight?” Available answers were “Yes” and “No, what are you talking about?” People who did sneeze were treated as cases, those who did not were controls.
Sweet taste preference
Participants were asked “When you're in the mood for a snack, what kind of snack do you usually reach for?” Available answers were “Sweet” “Salty or savory” “Both” or “Neither.” People answering either both or neither were disregarded. People reaching for sweet snacks were treated as cases.
Handedness
Handedness was scored on an eight-point scale (where 1 was “pure right” and 8 was “pure left”) using the questions and scoring from [60]. The haplotype analysis used Beagle [61] to phase data on chromosome 2 between positions 80375000 and 80523000. To calculate an odds ratio, we collapsed the eight-point scale to a binary scale, using people scored as pure right-handed or right-handed with weak left-handed tendencies as controls and all others as cases.
Supporting Information
Zdroje
1. Cavalli-SforzaL
BodmerW
1971 The Genetics of Human Populations. Freeman Company
2. ValverdeP
HealyE
JacksonI
ReesJL
ThodyAJ
1995 Variants of the melanocyte-stimulating hormone receptor gene are associated with red hair and fair skin in humans. Nat Genet 11 328 330
3. DuffyDL
MontgomeryGW
ChenW
ZhaoZZ
LeL
2007 A three-single-nucleotide polymorphism haplotype in intron 1 of OCA2 explains most human eye-color variation. Am J Hum Genet 80 241 252
4. SulemP
GudbjartssonDF
StaceySN
HelgasonA
RafnarT
2007 Genetic determinants of hair, eye and skin pigmentation in europeans. Nat Genet 39 1443 1452
5. HanJ
KraftP
NanH
GuoQ
ChenC
2008 A genome-wide association study identifies novel alleles associated with hair color and skin pigmentation. PLoS Genet 4 e1000074 doi:10.1371/journal.pgen.1000074
6. SturmRA
2009 Molecular genetics of human pigmentation diversity. Hum Mol Genet 18 9 17
7. SteingrímssonE
CopelandNG
JenkinsNA
2006 Mouse coat color mutations: from fancy mice to functional genomics. Dev Dyn 235 2401 2411
8. DavenportG
DavenportC
1908 Heredity of hair-form in man. Am Nat 42 341
9. FujimotoA
KimuraR
OhashiJ
OmiK
YuliwulandariR
2008 A scan for genetic determinants of human hair morphology: EDAR is associated with asian hair thickness. Hum Mol Genet 17 835 843
10. MitchellSC
WaringRH
LandD
ThorpeWV
1987 Odorous urine following asparagus ingestion in man. Experientia 43 382 383
11. LisonM
BlondheimSH
MelmedRN
1980 A polymorphism of the ability to smell urinary metabolites of asparagus. Br Med J 281 1676 1678
12. FrancksC
MaegawaS
LaurénJ
AbrahamsBS
Velayos-BaezaA
2007 LRRTM1 on chromosome 2p12 is a maternally suppressed gene that is associated paternally with handedness and schizophrenia. Mol Psychiatry 12 1129 1139
13. von SchantzM
2008 Phenotypic effects of genetic variability in human clock genes on circadian and sleep parameters. J Genet 87 513 519
14. YangN
MacArthurDG
GulbinJP
HahnAG
BeggsAH
2003 ACTN3 genotype is associated with human elite athletic performance. Am J Hum Genet 73 627 631
15. RobinsonNA
LapicS
WelterJF
EckertRL
1997 S100A11, S100A10, annexin I, desmosomal proteins, small proline-rich proteins, plasminogen activator inhibitor-2, and involucrin are components of the cornified envelope of cultured human epidermal keratinocytes. J Biol Chem 272 12035 12046
16. LeeSC
KimIG
MarekovLN
O'KeefeEJ
ParryDA
1993 The structure of human trichohyalin. potential multiple roles as a functional ef-hand-like calcium-binding protein, a cornified cell envelope precursor, and an intermediate filament-associated (cross-linking) protein. J Biol Chem 268 12164 12176
17. HuberM
SiegenthalerG
MiranceaN
MarenholzI
NizeticD
2005 Isolation and characterization of human repetin, a member of the fused gene family of the epidermal differentiation complex. J Invest Dermatol 124 998 1007
18. RothnagelJA
RogersGE
1986 Trichohyalin, an intermediate filament-associated protein of the hair follicle. J Cell Biol 102 1419 1429
19. MitchellSC
2001 Food idiosyncrasies: beetroot and asparagus. Drug Metab Dispos 29 539 543
20. MalnicB
GodfreyPA
BuckLB
2004 The human olfactory receptor gene family. Proc Natl Acad Sci USA 101 2584 2589
21. OlenderT
LancetD
ZozulyaS
CroningM
NeiM
Comparative sequence analysis of human olfactory receptors. http://senselab.med.yale.edu/ORDB/files/humanorseqanal.html
22. SulemP
GudbjartssonDF
StaceySN
HelgasonA
RafnarT
2008 Two newly identified genetic determinants of pigmentation in europeans. Nat Genet 40 835 837
23. MedlandSE
NyholtDR
PainterJN
McEvoyBP
McRaeAF
2009 Common variants in the trichohyalin gene are associated with straight hair in Europeans. Am J Hum Genet 85 750 755
24. LeeS
KimI
MarekovL
O'KeefeE
ParryD
1993 The structure of human trichohyalin. Potential multiple roles as a functional EF-hand-like calcium-binding protein, a cornified cell envelope precursor, and an intermediate filament-associated (cross-linking) protein. Journal of Biological Chemistry 268 12164 12176
25. ThibautS
GaillardO
BouhannaP
CannellDW
BernardBA
2005 Human hair shape is programmed from the bulb. Br J Dermatol 152 632 638
26. BarnicotNA
1959 Paper chromatography of human hair follicles and hair extracts. Br J Dermatol 71 303 308
27. AuberL
1950–1 The anatomy of follicles producing wool-fibres, with special reference to keratinization. Trans R Soc Edin 62 191 254
28. SteinertPM
ParryDA
MarekovLN
2003 Trichohyalin mechanically strengthens the hair follicle: multiple cross-bridging roles in the inner root shealth. J Biol Chem 278 41409 41419
29. AdaimyL
ChoueryE
MegarbaneH
MrouehS
DelagueV
2007 Mutation in WNT10A is associated with an autosomal recessive ectodermal dysplasia: the odonto-onycho-dermal dysplasia. Am J Hum Genet 81 821 828
30. ReddyS
AndlT
BagasraA
LuMM
EpsteinDJ
2001 Characterization of Wnt gene expression in developing and postnatal hair follicles and identification of Wnt5a as a target of Sonic hedgehog in hair follicle morphogenesis. Mech Dev 107 69 82
31. DaviesSJ
WiseC
VenkateshB
MirzaG
JeffersonA
2004 Mapping of three translocation breakpoints associated with orofacial clefting within 6p24 and identification of new transcripts within the region. Cytogenet Genome Res 105 47 53
32. FoskoSW
StennKS
BologniaJL
1992 Ectodermal dysplasias associated with clefting: significance of scalp dermatitis. J Am Acad Dermatol 27 249 256
33. RomanoRA
LiH
TummalaR
MaulR
SinhaS
2004 Identification of Basonuclin2, a DNA-binding zinc-finger protein expressed in germ tissues and skin keratinocytes. Genomics 83 821 833
34. VanhoutteghemA
DjianP
2006 Basonuclins 1 and 2, whose genes share a common origin, are proteins with widely different properties and functions. Proc Natl Acad Sci USA 103 12423 12428
35. LinL
GerthAJ
PengSL
2004 Active inhibition of plasma cell development in resting B cells by microphthalmia-associated transcription factor. J Exp Med 200 115 122
36. RedonR
IshikawaS
FitchKR
FeukL
PerryGH
2006 Global variation in copy number in the human genome. Nature 444 444 454
37. PerryGH
Ben-DorA
TsalenkoA
SampasN
Rodriguez-RevengaL
2008 The fine-scale and complex architecture of human copy-number variation. Am J Hum Genet 82 685 695
38. PeroutkaSJ
PeroutkaLA
1984 Autosomal dominant transmission of the “photic sneeze reflex”. N Engl J Med 310 599 600
39. SchrockK
2008 Looking at the sun can trigger a sneeze. Sci Am, Jan 10, URL http://www.sciam.com/article.cfm?id=looking-at-the-sun-can-trigger-a-sneeze
40. AvramD
IshmaelJE
NevrivyDJ
PetersonVJ
LeeSH
1999 Heterodimeric interactions between chicken ovalbumin upstream promoter-transcription factor family members ARP1 and Ear2. J Biol Chem 274 14331 14336
41. WarneckeM
OsterH
RevelliJP
Alvarez-BoladoG
EicheleG
2005 Abnormal development of the locus coeruleus in Ear2(Nr2f6)-deficient mice impairs the functionality of the forebrain clock and affects nociception. Genes Dev 19 614 625
42. EverettHC
1964 Sneezing in response to light. Neurology 14 483 490
43. HydenD
ArlingerS
2009 On light-induced sneezing. Eye (Lond) 23 2112 2114
44. AmirRE
Van den VeyverIB
WanM
TranCQ
FranckeU
1999 Rett syndrome is caused by mutations in X-linked MECP2, encoding methyl-CpG-binding protein 2. Nat Genet 23 185 188
45. RouxJC
PanayotisN
DuraE
VillardL
2009 Progressive noradrenergic deficits in the locus coeruleus of Mecp2 deficient mice. J Neurosci Res
46. IoannidisJP
2008 Why most discovered true associations are inflated. Epidemiology 19 640 648
47. ClaytonDG
WalkerNM
SmythDJ
PaskR
CooperJD
2005 Population structure, differential bias and genomic control in a large-scale, case-control association study. Nat Genet 37 1243 1246
48. Wellcome Trust Case Control Consortium 2007 Genome-wide association study of 14,000 cases of seven common diseases and 3,000 shared controls. Nature 447 661 678
49. WiggintonJE
CutlerDJ
AbecasisGR
2005 A note on exact tests of Hardy-Weinberg equilibrium. Am J Hum Genet 76 887 893
50. PriceAL
PattersonNJ
PlengeRM
WeinblattME
ShadickNA
2006 Principal components analysis corrects for stratification in genome-wide association studies. Nat Genet 38 904 909
51. R Development Core Team 2007 R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. URL http://www.R-project.org. ISBN 3-900051-07-0
52. PurcellS
NealeB
Todd-BrownK
ThomasL
FerreiraM
2007 PLINK: a toolset for whole-genome association and population-based linkage analysis. Am J Hum Genet 81
53. PurcellS
2009 PLINK version 1.05. Software available at http://pngu.mgh.harvard.edu/purcell/plink/
54. ServinB
StephensM
2007 Imputation-based analysis of association studies: candidate regions and quantitative traits. PLoS Genet 3 e114 doi:10.1371/journal.pgen.0030114
55. GuanY
StephensM
2008 Practical issues in imputation-based association mapping. PLoS Genet 4 e1000279 doi:10.1371/journal.pgen.1000279
56. International HapMap Consortium 2005 A haplotype map of the human genome. Nature 437 1299 1320
57. StoreyJD
TibshiraniR
2003 Statistical significance for genomewide studies. Proc Natl Acad Sci USA 100 9440 9445
58. CannHM
de TomaC
CazesL
LegrandMF
MorelV
2002 A human genome diversity cell line panel. Science 296 261 262
59. DevlinB
RoederK
1999 Genomic control for association studies. Biometrics 55 997 1004
60. AnnettM
1970 A classification of hand preference by association analysis. Br J Psychol 61 303 321
61. BrowningSR
BrowningBL
2007 Rapid and accurate haplotype phasing and missing-data inference for whole-genome association studies by use of localized haplotype clustering. Am J Hum Genet 81 1084 1097
Štítky
Genetika Reprodukční medicínaČlánek vyšel v časopise
PLOS Genetics
2010 Číslo 6
- Kazuistika – Perspektivy využití precizované medicíny v rámci personalizované specifické terapie onkologických pacientů
- Nobelova cena za chemii pro genetické nůžky: Objev, který změní naši budoucnost?
- Technologie na bázi RNA v klinické praxi: od přebarvených petúnií k terapii vzácných a dosud jen obtížně léčitelných chorob u lidí
- „Nepředstavovali jsme si, že náš výzkum povede přímo ke vzniku nových léků, dokonce ještě za našeho života“
- Bezplatné služby pro diagnostiku ATTRv amyloidózy pro kardiology
Nejčtenější v tomto čísle
- Web-Based, Participant-Driven Studies Yield Novel Genetic Associations for Common Traits
- The IG-DMR and the -DMR at Human Chromosome 14q32.2: Hierarchical Interaction and Distinct Functional Properties as Imprinting Control Centers
- Cushing's Syndrome and Fetal Features Resurgence in Adrenal Cortex–Specific Knockout Mice
- Amplification of a Cytochrome P450 Gene Is Associated with Resistance to Neonicotinoid Insecticides in the Aphid
Zvyšte si kvalifikaci online z pohodlí domova
Mazová zátka a její řešení
nový kurzVšechny kurzy