
Inference of Population Splits and Mixtures from Genome-Wide Allele Frequency Data
Many aspects of the historical relationships between populations in a species are reflected in genetic data. Inferring these relationships from genetic data, however, remains a challenging task. In this paper, we present a statistical model for inferring the patterns of population splits and mixtures in multiple populations. In our model, the sampled populations in a species are related to their common ancestor through a graph of ancestral populations. Using genome-wide allele frequency data and a Gaussian approximation to genetic drift, we infer the structure of this graph. We applied this method to a set of 55 human populations and a set of 82 dog breeds and wild canids. In both species, we show that a simple bifurcating tree does not fully describe the data; in contrast, we infer many migration events. While some of the migration events that we find have been detected previously, many have not. For example, in the human data, we infer that Cambodians trace approximately 16% of their ancestry to a population ancestral to other extant East Asian populations. In the dog data, we infer that both the boxer and basenji trace a considerable fraction of their ancestry (9% and 25%, respectively) to wolves subsequent to domestication and that East Asian toy breeds (the Shih Tzu and the Pekingese) result from admixture between modern toy breeds and “ancient” Asian breeds. Software implementing the model described here, called TreeMix, is available at http://treemix.googlecode.com.
Published in the journal:
. PLoS Genet 8(11): e32767. doi:10.1371/journal.pgen.1002967
Category:
Research Article
doi:
https://doi.org/10.1371/journal.pgen.1002967
Summary
Many aspects of the historical relationships between populations in a species are reflected in genetic data. Inferring these relationships from genetic data, however, remains a challenging task. In this paper, we present a statistical model for inferring the patterns of population splits and mixtures in multiple populations. In our model, the sampled populations in a species are related to their common ancestor through a graph of ancestral populations. Using genome-wide allele frequency data and a Gaussian approximation to genetic drift, we infer the structure of this graph. We applied this method to a set of 55 human populations and a set of 82 dog breeds and wild canids. In both species, we show that a simple bifurcating tree does not fully describe the data; in contrast, we infer many migration events. While some of the migration events that we find have been detected previously, many have not. For example, in the human data, we infer that Cambodians trace approximately 16% of their ancestry to a population ancestral to other extant East Asian populations. In the dog data, we infer that both the boxer and basenji trace a considerable fraction of their ancestry (9% and 25%, respectively) to wolves subsequent to domestication and that East Asian toy breeds (the Shih Tzu and the Pekingese) result from admixture between modern toy breeds and “ancient” Asian breeds. Software implementing the model described here, called TreeMix, is available at http://treemix.googlecode.com.
Introduction
The extant populations in a species result from an often-complex demographic history, involving population splits, gene flow, and changes in population size. It has long been recognized that genetic data can be used to learn about this history [1]–[3]. In humans, early approaches to inferring history from genetics were limited to using a relatively small number of blood group or other protein polymorphisms [1], [4]–[6]. These types of studies were then superseded by analyses of DNA markers, which have progressed from single marker studies [3] to studies involving hundreds of thousands of markers [7]. It is now feasible to collect genome-wide genetic data in any species; to a large extent it is no longer the data collection, but rather the statistical models used for analysis, that limit the historical insight possible.
There are many statistical approaches to demographic inference from genetic data. One approach is to develop an explicit population genetic model for the history of a set of populations, framed in terms of the effective population sizes of the populations, the times of population splits, the times of demographic events (such as population bottlenecks), and other relevant parameters. The values of these parameters can then be learned from the data using a variety of techniques, often involving simulation [8]–[16]. These approaches have the advantage of allowing flexible modeling of a wide variety of demographic scenarios, but the disadvantage that they can only be applied to one or a few populations at a time.
Another type of approach to learning about population history uses methods that summarize the major components of genetic variation in a sample by clustering or principal components analysis [17]–[20]. Although these methods do not model history explicitly, the inferred components can often be interpreted post hoc as representing historical populations, and individuals or populations that are mixtures of different components as evidence of admixture between these populations (e.g., [17], [21]–[23]). However, these methods are not directly informative about history; indeed, the relationship between the major components of genetic variation and true underlying demography is not always intuitive [24]–[26].
A different class of approaches focuses on the relationships between populations, by representing a set of populations as a bifurcating tree [1], [27]–[32]. In these models, the details of the demographic histories of the population are absorbed into the branch lengths of the tree [1], [33]. This approach has the advantage of being applicable to large numbers of populations; however, a major caveat when modeling the history of populations as a tree is that gene flow violates the assumptions of the model [2], [34], [35]. It is often difficult to know, a priori, how well the history fits a simple bifurcating tree. Explicit tests for the violation of a tree model have been developed [35]–[40]. These tests have been used, most notably, to infer the existence of gene flow between modern and archaic humans [39], [41], [42], as well as between diverged modern human populations [37], [43], [44].
In this paper, we present a unified statistical framework for building population trees and testing for the presence of gene flow between diverged populations. In this framework, the relationship between populations is represented as a graph, allowing us to model both population splits and gene flow. Graph-based models are of growing interest in phylogenetics [45], [46], but have been rarely used in population genetics (with some exceptions [37], [40], [47]).
Results
The starting point for our model was first proposed by Cavalli-Sforza and Edwards [1], and we draw additionally on related models by Nicholson et al. [33] and Coop et al. [48]. Our goal is to provide a statistical framework for inferring population networks that is motivated by an explicit population genetic model, but sufficiently abstract to be computationally feasible for genome-wide data from many populations (say, 10–100). Our primary aim is to represent the topology of relationships between populations, rather than the precise times of demographic events.
Our approach to this problem is to first build a maximum likelihood tree of populations. We then identify populations that are poor fits to the tree model, and model migration events involving these populations. Below, we first describe this approach in an idealized setting, and then describe the modifications necessary for implementation in practice.
Model
In the most simple case, consider a single SNP, and let the allele frequency of one of the alleles at this SNP in an ancestral population be . (We use a lowercase to denote that this is a parameter rather than a random variable. We initially consider distributions conditional on ). Now consider a descendant population . We model , the allele frequency of the SNP in population , as:


Now consider a descendant population of ; let us call this population , and the allele frequency in the population . Using the same model:



We can write down the expectation and variance of as:







Multiple populations
Now consider a set of four populations, all related to an ancestral population by a tree, as depicted in Figure 1A. Let the allele frequencies in the four populations be denoted , , , and , respectively, and the vector of all four frequencies be . We want to write down a joint distribution for given the tree. We start by writing down the covariance between any two populations with respect to the ancestral allele frequency (i.e. ). This is simply the variance of the common ancestor of the two populations:




Let us use to denote the variance-covariance matrix of allele frequencies between populations implied by the tree. Now, if we knew the value of , we could model as:

Modeling migration
To extend this framework to include migration, we allow populations to have ancestry from multiple parental populations [35], [40]. The contribution of each parental population is weighted; if we assume admixture occurs in a single generation, these weights are related to the fraction of alleles in the descendant population that originated in each parental population. Consider population 3 in Figure 1C (recall that the allele frequency in this population is ). We have labeled the two parental populations and ; let the allele frequencies in these populations be and , respectively. We model as:

Additionally, there is a choice of whether the edge from or the edge from should be considered the “migration” edge; these two possibilities not identifiable in the model. In practice, we set the edge with the largest weight as the non-migration edge, and the other edge (or edges) as the “migration” edge(s).
With these simplifications, the variance of can be written in the mixture case as:


Normalization
As described above, depends on the ancestral allele frequency . This means that the true variance-covariance matrix will differ by a scaling factor between SNPs with different values of . In much work on this type of model, investigators have normalized allele frequencies to account for this. One potential normalization is the arcsine square-root transformation [1]. However, a drawback to this normalization is that it is non-linear; the expected value of the allele frequency in the descendant populations is no longer , but pushed towards the boundaries, which could induce spurious correlations between the most drifted populations [50]. Another plausible transformation would be to scale all allele frequencies by , where is the mean allele frequency across populations [19], [33]. Both of these transformations increase the influence of polymorphisms that were rare in the ancestral population. However, these are precisely the loci where the approximation of our model to a true population genetics model is most likely to break down. For these reasons, we choose to work directly with untransformed allele frequencies.
Properties of the sample covariance
In practice, the multivariate normal model in Equation 16 is impractical because we do not know the ancestral values of allele frequencies, but instead only the values in sampled descendant populations. This means that cannot be estimated directly from data. However, consider instead the sample covariance matrix , where , where , is the number of populations, and and are the sample allele frequencies in populations and . is closely related to as follows:




Estimation from finite samples and many SNPs
Now assume that we have genotyped SNPs in each of populations. Our goal is to use these data to estimate the population history graph : that is, is a rooted, directed, acyclic graph with specified branch lengths and mixture weights, as described above and in Text S1. Let the sample allele frequency at SNP in population be . We can estimate the sample covariance matrix :

We now want to write down a likelihood for given (which in turn implies the expected sample covariance matrix ). One possibility would be to use the Wishart distribution, since the sample covariance matrix of multivariate normal random variables has this form. However, computation of the Wishart density involves computationally-intensive matrix inversion, so we took an alternative approach. Consider the observed covariance between populations and , . If we had a large number of independent genomic regions and estimated this quantity separately in each independent region, the sampling distribution would be approximately normal with mean (by appeal to the central limit theorem). We thus model as:




Measuring model fit
Finally, we wanted to define measures for how well the model fits the data. First, we define the matrix of residuals in this model, . These quantities are useful for visualization and fitting:


Implementation
We implemented an algorithm, called TreeMix, that searches for the graph that maximizes the composite likelihood in Equation 28. A search that enumerates all graphs is infeasible unless is very small, so to simplify the search we make the assumption that the history of the sampled populations is approximately tree-like. We thus start by searching for the maximum likelihood tree, taking an algorithmic approach similar to Felsenstein [30].
After building the tree, we fix the position of the root. (In the tree model the position of the root is not identifiable, as the evolution of allele frequencies along the tree is reversible under the Gaussian model when drift is assumed to be small. In a graph model, though the position of the root is partially identifiable, in all applications we assume that the position of the root is fixed using prior information about known outgroups). We then calculate the residual covariance matrix, , and add migration edges in a directed matter. First, we find the pairs of populations with the maximum residuals. We then attempt adding a migration edge between populations in the vicinity of each of the population pairs. For each attempted graph (or tree) topology, we optimize the branch lengths and migration edge weights (Methods).
After finding the single migration edge that most increases the likelihood, we attempt a series of local changes to the graph structure (Methods). We then iterate over this procedure to add additional migration edges. In principle, migration edges could be added until they are no longer statistically significant (see the following paragraph). In our experience, however, we prefer to stop adding migration events well before this point so that the resulting graph remains interpretable.
Significance testing
After building the maximum likelihood graph, we would like to quantify our uncertainty in the resulting graph structure. In particular, we would like to quantify our confidence in individual migration events. However, because the likelihood in Equation 28 is a composite likelihood, it cannot be used directly for formal tests for significance. Instead, we take a resampling approach to test the support for individual migration edges.
Consider a given migration edge, with corresponding weight . We wish to calculate a p-value for this weight (under the null hypothesis that , and for a fixed graph structure). To do this, we use the Wald statistic , where is the standard error in the estimate of the weight, which is distributed under the null. To obtain the standard error, recall that we have split the genome into independent blocks. We use the jackknife estimates of both and the standard error in (where we jackknife over blocks). Let index blocks, and be the estimated weight computed using all blocks except . Then:


Simulations
We tested the performance of the TreeMix method in simulations. We generated coalescent simulations from several histories; the basic structure was a set of 20 populations produced by a serial bottleneck model like that used by DeGiorgio et al. [51] to model human history (Figure 2A). The parameters of the simulations were chosen to be reasonable for non-African human populations; we used an effective population size of 10,000, and a history where all 20 populations share a common ancestor 2000 generations in the past. Each individual simulation involved 400 regions of approximately 500 kb each, and thus recapitulated many aspects of real data, including hundreds of thousands of loci and the presence of linkage disequilibrium.

Tree simulations
First, we tested the performance of the algorithm on truly tree-like data. We generated 100 independent simulations of 20 chromosomes from each population using the above demographic model without migration, and inferred population trees. The inferred trees perfectly matched the simulated model in all cases (Figure 2B, Figure S2), and the fitted tree model accounted for an average of 99.8% of the variance in . To test the effect of SNP ascertainment, we then inferred trees using only SNPs that were polymorphic in one of the populations (either population 1 or population 20); this ascertainment scheme did not decrease accuracy of the inferred topology, though it did alter the inferred branch lengths (Figure S3).
We used these simulations without migration to test the calibration of our p-values for migration events. For each simulation, after building the maximum likelihood tree, we introduced a migration event between two random populations and tested it for significance. As expected if the p-values are properly calibrated, their distribution is approximately uniform (Figure S4).
Finally, we performed tree simulations in a situation where fixed differences and new mutations (rather than shared polymorphisms inherited from a common ancestor) were common between the populations; in this context the population genetic interpretation of the model breaks down. We performed simulations where all the true branch lengths were 50 times longer than in the original model, corresponding to a history where the 20 populations share a common ancestor approximately 100,000 generations in the past. Again, we see no errors in the topology of the inferred trees (Figures S5, S6). In this situation, the covariances between closely-related populations tend to be slightly underestimated; in more extreme situations this could lead to spurious inferences of migration (Figures S5, S6). However, overall, these simulations suggest that the model will still be useful even in situations where the population genetic interpretation is not strictly correct.
Simulations with migration
We then introduced migration events into our simulations. We generated simulations under the same model described above; however, we now simulated an admixture event approximately 100 generations before the present where one population receives a fraction of its ancestry (either 10% or 30%) from one of the other populations. We tried ten different pairwise combinations of populations, and generated 100 simulations for each pair. For each simulation, we ran TreeMix and allowed it to infer a migration event. We then judged the error rate of the algorithm as the fraction of times the inferred topology of the graph was not exactly correct (this is a conservative estimate of the error rate, in that inferred graph topologies that are very close to the truth are counted as errors). In general, TreeMix was able to correctly infer the graph structure in these simulations (Figure 2C). However, accuracy dropped considerably when migration was between closely related populations without outgroups present in the data (these are populations 1 and 20 in the model; Figure 2C). The major types of errors produced in the simulations were incorrectly inferred directions of migration arrows and inference of admixture in populations related to the truly admixed population (Text S1, Figure S7).
We next asked whether the mixture “weights” inferred in the model can be interpreted as admixture proportions. To do this, we simulated admixture events of varying proportion between the first and tenth population in the serial bottleneck model described above, set the graph to the true topology, and estimated the mixture weight. The weights are indeed correlated with the true ancestry fraction, but underestimate relatively high admixture proportions in these simulations (Figure 2D). The precise bias in the estimation of this parameter will depend, in real data, on largely unknowable parameters (Text S1).
Application to humans
To test the performance of the TreeMix model with real data, we applied it to humans, whose genetic history has been studied extensively [7], [21], [52], [53]. We applied the model to a dataset consisting of about 125,000 SNPs ascertained by low-coverage genome sequencing in a single Yoruban individual and then genotyped in 55 modern and archaic human populations [54]. In all that follows, we excluded the two Oceanian populations because they gave inconsistent results across datasets. We believe this difficulty results from the fact that these populations contain ancestry from multiple sources, making the graph estimation somewhat unstable when they are included (Text S1, Figure S12). We first built the tree of all 53 remaining populations (Figure 3A). This tree largely recapitulates the known relationships among population groups [7], and explains 98.8% of the variance in relatedness between populations (though this is high, it is less than the 99.8% observed in the simulations of a true tree model). We examined the residuals of the model's fit to identify aspects of ancestry not captured by the tree (Figure 3B). A number of known admixed populations stand out: in particular, these include the Mozabite and Middle Eastern populations.

We then sequentially added migration events to the tree. In Figure 4, we show the inferred graph with ten migration edges; p-values for all reported migration edges are less than (we show the graph with the maximum likelihood over several independent runs of TreeMix with random orders of input populations). This graph model explains 99.8% of the variance in relatedness between populations. As expected from examination of Figure 3B, the migration events recapitulate many known events in human history. We infer that the Mozabite are the result of admixture between an African and a Middle Eastern population (with about 33% of their ancestry from Africa), and that Middle Eastern populations also have African ancestry (Palestinians and Bedouins: from Africa; Druze: ). This is consistent with previously reported admixture proportions from these populations [43], [55]. Additionally, we identify the known European ancestry in the Maya () [21], and infer that the Uyghur and Hazara populations are the result of admixture between west Eurasian and East Asian populations ( and from west Eurasia, respectively) [20], [21], [56].

Several additional migration events in the human data have not been previously examined in detail, but are consistent with previous clustering analysis of these populations [7], [20], [21]. These include migration from Africa to the Makrani and Brahui in Central Asia () and from a population related to East Asians and Native Americans (which we interpret as likely Siberian) to Russia ().
Two inferred edges were unexpected. First, perhaps the most surprising inference is that Cambodians trace about 16% of their ancestry to a population equally related to both Europeans and other East Asians (while the remaining 84% of their ancestry is related to other southeast Asians). This is partially consistent with clustering analyses, which indicate shared ancestry between Cambodians and central Asian populations [7]. To confirm that the Cambodians are admixed, we turned to less parameterized models. The predicted admixture event implies that allele frequencies in Cambodia are more similar to those in African populations than would be expected based on their East Asian ancestry. To test this, we used three-population tests [37]. We tested the trees [African, [Cambodian,Dai]] for evidence of admixture in the Cambodians (Methods). When using any African population, there is strong evidence of admixture (when using Yoruba, []; when using Mandenka, []; when using San, []). We conclude that the Cambodian population is the result of an admixture event involving a southeast Asian population related to the Dai and a Eurasian population only distantly related to those present in these data.
Finally, we infer an admixture edge from the Middle East (a population related to the Mozabite, a Berber population from northern Africa) to southern European populations (). This migration edge is the one edge that is not consistent across independent runs of TreeMix on these data (Figure S8). In particular, an alternative graph (albeit with lower likelihood) places the Mozabite as an admixture between southern Europe and Africa (rather than the Middle East and Africa), and does not include an edge from the middle East to southern Europe. We thus hesitate to interpret this result, except to note that the relationship between northern African, the Middle East, and southern Europe involves complex patterns of gene flow that merit further investigation [43], [57].
To test the robustness of our results to SNP ascertainment, we additionally ran TreeMix on the same set of populations using a set of SNPs ascertained in a single French individual. The inferred graph was nearly identical (Figure S10). Additionally, as noted above, different random input orders for the populations gave very similar results (Figure S8). We conclude from this that the model is able to consistently and accurately infer the major mixture events in the history of a species. This approach is computationally efficient: building the tree took around five minutes on a standard desktop computer (with a processor speed of 3.1 GHz), and adding ten migration events to the tree took about four and a half hours (the major computational cost is in the iterative estimation of migration weights).
Application to dogs
While human populations have been extensively studied, we next applied the model to dogs, a species where considerably less is known about population history. In particular, we applied the model to a dataset consisting of about 60,000 SNPs genotyped in 82 dog breeds or wild canids [58]. As for humans, we first inferred the maximum likelihood tree (Figure 5A). The differences in history between dogs and humans are striking: there are long terminal branches leading to each dog breed in the inferred tree (Figure 5A, recall that the terminal branch lengths account for sample size). This is consistent with the known strong bottlenecks in the establishment of dog breeds [23]. However, examining the residuals from the model revealed a number of populations that do not fit a strict tree model (Figure 5B); indeed, the tree model explained 94.7% of the variance in relatedness between breeds, somewhat less than between human populations.
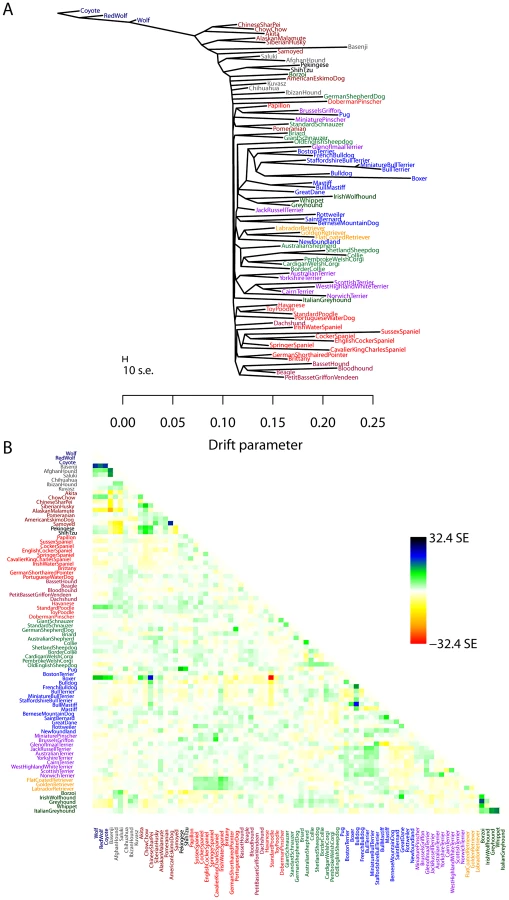
We sequentially added migration events to the tree in Figure 5A. In Figure 6, we show the inferred graph with ten migration events, which explains 96.8% of the variance in relatedness between breeds (which suggests that additional events exist in the data). In the following paragraphs, we describe some of these events.

We infer that the bull mastiff is the result of an admixture event between bulldogs and mastiffs. This is a known event [59]; we estimate the admixture proportions as 33% bulldog and 67% mastiff. We further examined this event using four-population tests for treeness. As expected given the known history, the tree [[boxer,bulldog],[mastiff,bull mastiff]] fails the four-population test (, ), while replacing the bull mastiff with other related breeds that we do not predict to be involved in the admixture event results in trees that pass this test. For example, the tree [[boxer,bulldog],[mastiff,Boston terrier]] passes the four-population test with .
The most visually apparent residuals in Figure 5B are accounted for in the graph by an admixture event from the grey wolf into the basenji, an ancient African breed of dog (). Such a high mixture fraction is consistent with previous clustering analyses of these data [23], [60]. We again sought to confirm this signal in a less-parameterized model. We tested the four-population tree [[wolf,ancient breed],[basenji, Afghan hound]] with various “ancient” dog breeds. We could not find a tree that passed the four-population test (with Akita as the ancient breed, ; with Alaskan Malamute, ), confirming the presence of gene flow in these trees. Replacing the basenji with the saluki in these analyses resulted in trees that pass the four-population test (for example, the tree [[wolf, Akita],[Afghan hound, saluki]] passes with ). Though we cannot have complete confidence in the precise migration events, these results are consistent with admixture between gray wolves and the basenji.
Another breed that stands out in this analysis is the boxer (Note that many of the SNPs used in this study were ascertained using a boxer individual, so we may have increased power to identify migration events involving this breed). We infer a significant genetic contribution from wolves to the boxer (), and migration between the boxer and the Chinese shar-pei, a distantly-related ancient breed (). To further examine these events, we again turned to four-population tests. To evaluate the wolf mixture, we tested the tree [[wolf, ancient breed],[boxer, bulldog]]. We did not find a tree that passed the four-population test (with Akita as the ancient breed, ; with Afghan Hound, ). Replacing the Boxer with the Mastiff in these analyses led to trees that passed the four-population test (for example, with Akita as the ancient breed, ). To evaluate the gene flow from the Boxer to the Chinese shar-pei, we tested the tree [[Chinese shar-pei, Akita],[boxer, bulldog]]; this tree fails the four-population test (), while the tree [[Chow Chow, Akita],[boxer,bulldog]] passes ().
Previous analyses of these data have noted that the “toy breeds” of dog cluster together Vonholdt:2010uq. We find that the Chinese toy breeds (the Pekingese and the Shi Tzu) result from admixture between a population related to ancient East Asian dog breeds and a modern population related to the Brussels griffon and the pug ( from the East Asian breeds). To confirm the presence of gene flow, we tested four-population trees of the form [[Asian toy breed, Akita/Chow Chow],[Pug,mastiff]]. These trees fail, with varying levels of significance, ranging from [[Chow Chow, Shi Tzu],[Pug, mastiff]] () to [[Akita, Pekingese],[Pug, mastiff]] ().
Finally, we noticed that two of the sighthounds (the Borzoi and the Italian greyhound) do not cluster with the other sight hounds in the tree, namely greyhound, whippet and Irish wolfhound (Figure 5A); however, they do show evidence of having sighthound admixture in the graph (Figure 6). These are the borzoi (which appear to be admixed between an ancient or spitz-breed dog, with 47% ancestry from the sighthounds) and the Italian Greyhound (which appears to be admixed with a toy breed, with 34% ancestry from the sighthounds). This is consistent with the known phenotypic characteristics of these dogs; the borzoi is considered a saluki-like breed, and the Italian greyhound is phenotypically a small version of a greyhound [59].
Overall, we conclude that there has been considerable gene flow between dog breeds over the course of domestication; there are many additional migration events that merit further examination (Figure 6, Text S1).
Discussion
In this paper, we have developed a unified model for inferring patterns of population splits and mixtures from genome-wide allele frequency data. We have shown that this model is accurate in simulations, largely recapitulates the known relationships between well-studied human populations, and is able to identify new relationships between populations in both humans and dogs.
The TreeMix model can be thought of as a complement to methods for the identification of population structure [18]–[20]. These latter methods are powerful tools for clustering together individuals into relatively homogenous populations (and to identify individuals that are genetic outliers in their population) [18]–[20]. However, once population structure in a species has been identified, these methods are not well-suited for describing how it arose, and are only indirectly informative about the historical relationships between different populations. The model developed in this paper is designed to more directly address these historical questions.
Modeling assumptions
There are a number of assumptions, both implicit and explicit, in the interpretation of the TreeMix model. First, we have motivated the model in terms of inferring the historical splits and mixtures of populations. However, a given covariance structure of allele frequencies between populations can be a consequence of either a non-equilibrium demography (population splits and mixtures) or an equilibrium demography (populations at long-term stasis with a fixed migration structure) [2]. For the species analyzed in this paper, population equilibrium over the entire species range is not a tenable hypothesis; however, some subsets of populations may be at equilibrium, and there may be species where this alternative historical interpretation of the model is plausible.
We have also modeled migration between populations as occurring at single, instantaneous time points. This is, of course, a dramatic simplification of the migration process. This model will work best when gene flow between populations is restricted to a relatively short time period. Situations of continuous migration violate this assumption and lead to unclear results (Figure S14). The relevance of this assumption will depend on the species and the populations considered. In humans, the relevance of continuous versus discrete mixture events is an open question–some aspects of genetic variation appear compatible with continuous migration [61], while other aspects do not [37]. Indeed, both sorts of models are likely relevant at different time scales [62].
We also rely on the implicit assumption that the history of the species being analyzed is largely tree-like. We have made this assumption to simplify the search for the maximum likelihood graph; additionally, we speculate that in graphs with complex structure, there will be many graphs that lead to identical covariance matrices, and thus several different histories will be compatible with the data. That said, improvements to the search algorithm could allow the assumption of approximate treeness to be somewhat relaxed. Currently, if the number of admixed populations is large relative to the number of unadmixed populations, this assumption breaks down. For example, in the human data, note that we see no evidence of the documented gene flow from Neandertals to all non-African populations [39] (Figure 3B). The reason for this is that the large number of populations with admixture can be accommodated in the tree by allowing the branch from Neandertals to Africans to be slightly underestimated (additionally, by using SNPs ascertained in Africa, we have selected against sites that are informative about Neandertal ancestry). If only a single non-African population is included in the analysis, the relationship between Neandertals and the non-African population is clearer (Figure S15).
Conclusions
A number of extensions to the sort of model described here are of potential interest. First, the historical relationships between populations could be useful as null demographic models for the detection of natural selection [48], [63], [64]. Second, in a given individual, the best-fit graph relating the individual to other populations may change along a chromosome; this sort of information could be of use in local ancestry inference. Finally, we have not used the information about demographic history present in linkage disequilibrium; approaches that explicitly use this information may provide additional power to detect migration events and estimate their timing, at an additional computational cost [20], [53], [65].
Methods
Graph estimation
As described in the Results, we developed an algorithm called TreeMix that uses the composite likelihood in Equation 28 to search for the maximum likelihood graph. Estimation involves two major steps. First, for a given graph topology, we need to find the maximum likelihood branch lengths and migration weights. Second, we need to search the space of possible graphs. First consider a given graph topology. We iterate between optimizing the branch lengths and weights. If the edge weights are known, the observed entries of the covariance matrix can be written down as an overdetermined system of linear equations (as in Equations 13–15). We solve this system by non-negative least squares [66]. Though the least squares solution is the maximum composite likelihood solution in the case where all entries of the covariance matrix have equal variance, it is not strictly the maximum likelihood solution in cases with unequal variances. The algorithm could be extended to unequal variances using a weighted least squares approach, but we have not implemented this. We then do a golden section search for the optimal weight (between zero and one) on each migration edge [67]. At each step in the golden section search, we update the branch lengths. We optimize the weight of each migration edge in turn, and iterate over migration edges until convergence.
To search the space of possible graphs, we take a hill-climbing approach. We start by finding a local optimum tree, taking an algorithmic approach similar to Felsenstein [30]. We randomly select three populations, optimize the branch lengths for all three possible trees, and choose the best (in terms of the composite likelihood) tree. Then, we add the remaining populations one by one in a random order. To add a population, we try attaching it to all branches of the current tree, optimizing the branch lengths for each one as described above, and find the most likely spot. We then perform a round of local rearrangements (i.e., nearest-neighbor interchanges [50]) around each internal node, keeping the resulting tree only if it increases the likelihood.
After adding all populations, we calculate the residual covariance matrix, . We then add migration edges in a directed matter. First, we find the pairs of populations with the maximum residuals (these are the pairs of populations with the worst fit under the model). In the results reported, . We define a “neighborhood” around each population of a pair as the tips within a distance of edges of the focal population. In applications above, we use . This defines a set of pairs of populations that either have a poor fit, or are located in the graph near populations with a poor fit. We take each of these pairs in turn. For each pair, we identify the set of nodes in the path from each member of the pair to the root of the graph. This gives us two sets of nodes. We take all pairwise combinations of nodes in each set, and look at residuals between the populations that are the descendants of each node. If all of the residuals are positive, we add a migration edge between the two nodes and estimate its maximum likelihood weight. We then keep only the single edge that most increases the likelihood of the graph. After adding a migration edge, we attempt nearest-neighbor interchanges at the source and destination of the migration event, attempt changing the source and destination of all migration events, and attempt changing the direction of all migration arrows. Once we have reached the local maximum by this method, we attempt nearest-neighbor interchanges at all internal nodes. We iterate over this procedure for a predetermined number of migration edges. We then test the migration edges for significance as described.
The TreeMix source code is available at http://treemix.googlecode.com.
Three - and four-population tests of treeness
We implemented three - and four-population tests as described in Reich et al. [37]. For the relationship between the statistics and the covariance model underlying TreeMix, see the Text S1. For the three-population test, we estimated as in Reich et al. [37], and tested whether is it less than zero. We report the Z-score for this test. To obtain a standard error on the estimate of , we used a block jackknife similar to Reich et al. [37]. However, Reich et al. [37] split the genome into blocks based on distance (with variable numbers of SNPs per block); we split the genome into blocks of SNPs (and thus the blocks will be of variable size).
For the four-population test for treeness, we calculate the statistic as in Reich et al. [37], and test whether it is different than zero. Again, we report a Z-score for this test. Standard errors for the statistic were obtained as for the statistic.
Human data
The human data we used were downloaded from http://www.cephb.fr/en/hgdp/ on August 16th, 2011 (the data set labeled Harvard HGDP-CEPH genotypes). They consist of several panels of SNPs ascertained from low-coverage genome sequencing of single individual from different populations and then genotyped in the Human Genome Diversity Panel [54]. Additionally, at each site, a single sequencing read from the Denisova and Neandertal genome sequencing projects was sampled and the allele reported. These data have the property that they allow for complete control of the ascertainment strategy, and allow us to test the robustness of inference to different ascertainment schemes. For the main analyses, we used the panel of autosomal SNPs ascertained in a single Yoruban individual; there are 124,115 such sites. For some analyses, we also used the panel of autosomal SNPs ascertained in a single French individual; there are 111,970 such sites. For all analyses with TreeMix, we used a window size () of 500; this corresponds to a window size of approximately 10 Mb. For all TreeMix analyses, we set the Neandertal and Denisova samples as the outgroups.
Since we have only a single allele from the Neandertal and Denisova populations, we cannot calculate heterozygosity in these populations for unbiased estimation of the covariance matrix (see ). To account for this, we simply chose a relatively low level of heterozygosity and assigned it to both populations. In the Yoruba ascertained SNPs, we used a heterozygosity of 0.13, and for the French ascertained SNPs, we used a heterozygosity of 0.2. In practice, this only affected the lengths of the terminal branches to Neandertal and Denisova; running TreeMix with a heterozygosity of zero in both populations resulted in the same graph topologies (not shown).
Dog data
Allele counts for the dog breeds and wild canids reported in Boyko et al. Boyko:2010fk were downloaded from http://genome-mirror.bscb.cornell.edu/ on July 30, 2011. These data consist of counts of reference and alternate alleles at 61,468 sites in 85 dog breeds and wild canids. We removed the Jackal and Scottish Deerhound for having relatively high amounts of missing data, and the village dogs because it is unclear if they represent a coherent population. We also removed all SNPs on the X chromosome. This left us with 60,615 SNPs in 82 populations. We ran TreeMix with a window size () of 500. This corresponds to a window size of approximately 20 Mb. For all TreeMix analyses, we set the coyote as the outgroup.
The ascertainment scheme used for SNP discovery in dogs was complicated [68]. The largest set of SNPs were ascertained by virtue of being different between the boxer and poodle assemblies. This should lead to an overestimation of the distance between the boxer and the poodle in our analysis. Indeed, in Figure 5B, a considerable negative residual between the boxer and poodle is visible. Another set of SNPs were ascertained by being heterozygous within a boxer individual, and a third set were ascertained by comparison between a boxer and wild canids. These latter SNPs should lead to an overestimation of the distance between the boxer and the wolf in our analysis (as we see for the poodle); in fact, we infer migration between the boxer and the wolf. This ascertainment issue may have led us to underestimate the amount of gene flow in the comparison.
Simulations
All simulations were performed using ms [69]. The exact commands used are listed in Text S1. When running TreeMix on simulations without ascertainment, we used a window size of 5000 SNPs; for simulations with ascertainment we used windows of 1000 SNPs. Consensus trees were generated using SumTrees v.3.1.0 [70].
Supporting Information
Zdroje
1. Cavalli-SforzaLL, EdwardsAW (1967) Phylogenetic analysis. Models and estimation proce-dures. Am J Hum Genet 19 : 233–57.
2. FelsensteinJ (1982) How can we infer geography and history from gene frequencies? J Theor Biol 96 : 9–20.
3. CannRL, StonekingM, WilsonAC (1987) Mitochondrial DNA and human evolution. Nature 325 : 31–6.
4. NeiM, RoychoudhuryAK (1974) Genic variation within and between the three major races of man, Caucasoids, Negroids, and Mongoloids. Am J Hum Genet 26 : 421–43.
5. NeiM, RoychoudhuryAK (1993) Evolutionary relationships of human populations on a global scale. Mol Biol Evol 10 : 927–43.
6. Cavalli-SforzaLL, PiazzaA, MenozziP, MountainJ (1988) Reconstruction of human evolution: bringing together genetic, archaeological, and linguistic data. Proc Natl Acad Sci U S A 85 : 6002–6.
7. LiJZ, AbsherDM, TangH, SouthwickAM, CastoAM, et al. (2008) Worldwide human rela-tionships inferred from genome-wide patterns of variation. Science 319 : 1100–1104.
8. PritchardJK, SeielstadMT, Perez-LezaunA, FeldmanMW (1999) Population growth of human Y chromosomes: a study of Y chromosome microsatellites. Mol Biol Evol 16 : 1791–8.
9. BeaumontMA, ZhangW, BaldingDJ (2002) Approximate Bayesian computation in popula-tion genetics. Genetics 162 : 2025–35.
10. SchaffnerSF, FooC, GabrielS, ReichD, DalyMJ, et al. (2005) Calibrating a coalescent simulation of human genome sequence variation. Genome Res 15 : 1576–1583.
11. GutenkunstRN, HernandezRD, WilliamsonSH, BustamanteCD (2009) Inferring the joint demographic history of multiple populations from multidimensional SNP frequency data. PLoS Genet 5: e1000695 doi:10.1371/journal.pgen.1000695.
12. HeyJ, NielsenR (2004) Multilocus methods for estimating population sizes, migration rates and divergence time, with applications to the divergence of Drosophila pseudoobscura and D. persimilis. Genetics 167 : 747–60.
13. BeerliP, FelsensteinJ (1999) Maximum-likelihood estimation of migration rates and effective population numbers in two populations using a coalescent approach. Genetics 152 : 763–73.
14. BecquetC, PrzeworskiM (2007) A new approach to estimate parameters of speciation models with application to apes. Genome Res 17 : 1505–19.
15. KubatkoLS (2009) Identifying hybridization events in the presence of coalescence via model selection. Syst Biol 58 : 478–88.
16. GronauI, HubiszMJ, GulkoB, DankoCG, SiepelA (2011) Bayesian inference of ancient human demography from individual genome sequences. Nat Genet 43 : 1031–4.
17. MenozziP, PiazzaA, Cavalli-SforzaL (1978) Synthetic maps of human gene frequencies in Europeans. Science 201 : 786–92.
18. PritchardJK, StephensM, DonnellyP (2000) Inference of population structure using multi-locus genotype data. Genetics 155 : 945–59.
19. PattersonN, PriceAL, ReichD (2006) Population structure and eigenanalysis. PLoS Genet 2: e190 doi:10.1371/journal.pgen.0020190.
20. LawsonDJ, HellenthalG, MyersS, FalushD (2012) Inference of Population Structure using Dense Haplotype Data. PLoS Genet 8: e1002453 doi:10.1371/journal.pgen.1002453.
21. RosenbergNA, PritchardJK, WeberJL, CannHM, KiddKK, et al. (2002) Genetic structure of human populations. Science 298 : 2381–2385.
22. LitiG, CarterDM, MosesAM, WarringerJ, PartsL, et al. (2009) Population genomics of domestic and wild yeasts. Nature 458 : 337–41.
23. vonHoldtBM, PollingerJP, LohmuellerKE, HanE, ParkerHG, et al. (2010) Genome-wide SNP and haplotype analyses reveal a rich history underlying dog domestication. Nature 464 : 898–902.
24. FrançoisO, CurratM, RayN, HanE, ExcoffierL, et al. (2010) Principal component analysis under population genetic models of range expansion and admixture. Mol Biol Evol 27 : 1257–68.
25. McVeanG (2009) A genealogical interpretation of principal components analysis. PLoS Genet 5: e1000686 doi:10.1371/journal.pgen.1000686.
26. NovembreJ, StephensM (2008) Interpreting principal component analyses of spatial popula-tion genetic variation. Nat Genet 40 : 646–9.
27. SaitouN, NeiM (1987) The neighbor-joining method: a new method for reconstructing phy-logenetic trees. Mol Biol Evol 4 : 406–25.
28. FelsensteinJ (1973) Maximum-likelihood estimation of evolutionary trees from continuous characters. Am J Hum Genet 25 : 471–92.
29. RoyChoudhuryA, FelsensteinJ, ThompsonEA (2008) A two-stage pruning algorithm for likelihood computation for a population tree. Genetics 180 : 1095–105.
30. FelsensteinJ (1981) Evolutionary trees from gene frequencies and quantitative characters: finding maximum likelihood estimates. Evolution 35 : 1229–1242.
31. SirénJ, MarttinenP, CoranderJ (2011) Reconstructing population histories from single nu-cleotide polymorphism data. Mol Biol Evol 28 : 673–83.
32. NielsenR, MountainJL, HuelsenbeckJP, SlatkinM (1998) Maximum-likelihood estimation of population divergence times and population phylogeny in models without mutation. Evolution 52 : 669–677.
33. NicholsonG, SmithAV, JónssonF, GústafssonÓ, StefánssonK, et al. (2002) Assessing Pop-ulation Differentiation and Isolation from Single-Nucleotide Polymorphism Data. Journal of the Royal Statistical Society Series B (Statistical Methodology) 64 : 695–715.
34. Cavalli-SforzaLL (1973) Analytic review: some current problems of human population genet-ics. Am J Hum Genet 25 : 82–104.
35. Cavalli-SforzaLL, PiazzaA (1975) Analysis of evolution: evolutionary rates, independence and treeness. Theor Popul Biol 8 : 127–65.
36. KeinanA, MullikinJC, PattersonN, ReichD (2007) Measurement of the human allele fre-quency spectrum demonstrates greater genetic drift in East Asians than in Europeans. Nat Genet 39 : 1251–5.
37. ReichD, ThangarajK, PattersonN, PriceAL, SinghL (2009) Reconstructing Indian popula-tion history. Nature 461 : 489–94.
38. DurandEY, PattersonN, ReichD, SlatkinM (2011) Testing for Ancient Admixture between Closely Related Populations. Mol Biol Evol 28 : 2239–52.
39. GreenRE, KrauseJ, BriggsAW, MaricicT, StenzelU, et al. (2010) A draft sequence of the Neandertal genome. Science 328 : 710–22.
40. LathropGM (1982) Evolutionary trees and admixture: phylogenetic inference when some populations are hybridized. Ann Hum Genet 46 : 245–55.
41. ReichD, GreenRE, KircherM, KrauseJ, PattersonN, et al. (2010) Genetic history of an archaic hominin group from Denisova Cave in Siberia. Nature 468 : 1053–60.
42. ReichD, PattersonN, KircherM, DelfinF, NandineniMR, et al. (2011) Denisova admixture and the first modern human dispersals into Southeast Asia and Oceania. Am J Hum Genet 89 : 516–28.
43. MoorjaniP, PattersonN, HirschhornJN, KeinanA, HaoL, et al. (2011) The history of African gene flow into Southern Europeans, Levantines, and Jews. PLoS Genet 7: e1001373 doi:10.1371/journal.pgen.1001373..
44. RasmussenM, GuoX, WangY, LohmuellerKE, RasmussenS, et al. (2011) An Aboriginal Australian genome reveals separate human dispersals into Asia. Science 334 : 94–8.
45. Huson D, Rupp R, Scornavacca C (2010) Phylogenetic Networks. Concepts, Algorithms and Applications. Cambridge University Press.
46. HusonDH, BryantD (2006) Application of phylogenetic networks in evolutionary studies. Mol Biol Evol 23 : 254–67.
47. DyerRJ, NasonJD (2004) Population Graphs: the graph theoretic shape of genetic structure. Mol Ecol 13 : 1713–27.
48. CoopG, WitonskyD, Di RienzoA, PritchardJK (2010) Using environmental correlations to identify loci underlying local adaptation. Genetics 185 : 1411–23.
49. WeirBS, HillWG (2002) Estimating F-statistics. Annu Rev Genet 36 : 721–50.
50. Felsenstein J (2003) Inferring Phylogenies. Sinauer Associates, 2nd edition.
51. DeGiorgioM, JakobssonM, RosenbergNA (2009) Out of Africa: modern humanorigins special feature: explaining worldwide patterns of human genetic variation using a coalescent - based serial founder model of migration outward from Africa. Proc Natl Acad Sci U S A 106 : 16057–62.
52. JakobssonM, ScholzSW, ScheetP, GibbsJR, VanLiereJM, et al. (2008) Genotype, haplotype and copy-number variation in worldwide human populations. Nature 451 : 998–1003.
53. HellenthalG, AutonA, FalushD (2008) Inferring human colonization history using a copying model. PLoS Genet 4: e1000078 doi:10.1371/journal.pgen.1000078..
54. PattersonN, MoorjaniP, LuoY, MallickS, RohlandN, et al. (2012) Ancient admixture. Genetics In Press.
55. PriceAL, TandonA, PattersonN, BarnesKC, RafaelsN, et al. (2009) Sensitive detection of chromosomal segments of distinct ancestry in admixed populations. PLoS Genet 5: e1000519 doi:10.1371/journal.pgen.1000519..
56. XuS, HuangW, QianJ, JinL (2008) Analysis of genomic admixture in Uyghur and its implication in mapping strategy. Am J Hum Genet 82 : 883–94.
57. HennBM, BotiguéLR, GravelS, WangW, BrisbinA, et al. (2012) Genomic ancestry of North Africans supports back-to-Africa migrations. PLoS Genet 8: e1002397 doi:10.1371/journal.pgen.1002397..
58. BoykoAR, QuignonP, LiL, SchoenebeckJJ, DegenhardtJD, et al. (2010) A simple genetic architecture underlies morphological variation in dogs. PLoS Biol 8: e1000451 doi:10.1371/journal.pbio.1000451..
59. American Kennel Club (2006) The complete dog book. Ballantine Books.
60. ParkerHG, KimLV, SutterNB, CarlsonS, LorentzenTD, et al. (2004) Genetic structure of the purebred domestic dog. Science 304 : 1160–4.
61. NovembreJ, JohnsonT, BrycK, KutalikZ, BoykoAR, et al. (2008) Genes mirror geography within Europe. Nature 456 : 98–101.
62. NovembreJ, RamachandranS (2011) Perspectives on human population structure at the cusp of the sequencing era. Annu Rev Genomics Hum Genet 12 : 245–74.
63. BhatiaG, PattersonN, PasaniucB, ZaitlenN, GenoveseG, et al. (2011) Genome-wide com-parison of African-ancestry populations from CARe and other cohorts reveals signals of natural selection. Am J Hum Genet 89 : 368–81.
64. BonhommeM, ChevaletC, ServinB, BoitardS, AbdallahJ, et al. (2010) Detecting selection in population trees: the Lewontin and Krakauer test extended. Genetics 186 : 241–62.
65. Myers S, Hellenthal G, Lawson D, Busby G, Leslie S, et al.. (2011). LD patterns in dense variation data reveal information about the history of human populations worldwide. URL http://www.ichg2011.org/cgi-bin/ichg11s?&sort=ptimes&sbutton=Detail&absno=21708&sid=806980.
66. Lawson CL, Hanson RJ (1995) Solving least squares problems. Philadelphia, PA: Society for Industrial Mathematics, 3rd edition.
67. Press WH, Teukolsky SA, Vetterling WT, Flannery BP (1992) Numerical recipes in C (2nd ed.): the art of scientific computing. New York, NY, USA: Cambridge University Press.
68. Lindblad-TohK, WadeCM, MikkelsenTS, KarlssonEK, JaffeDB, et al. (2005) Genome sequence, comparative analysis and haplotype structure of the domestic dog. Nature 438 : 803–19.
69. HudsonRR (2002) Generating samples under a Wright-Fisher neutral model of genetic varia-tion. Bioinformatics 18 : 337–8.
70. SukumaranJ, HolderMT (2010) DendroPy: a Python library for phylogenetic computing. Bioinformatics 26 : 1569–71.
Štítky
Genetika Reprodukční medicínaČlánek vyšel v časopise
PLOS Genetics
2012 Číslo 11
- Kazuistika – Perspektivy využití precizované medicíny v rámci personalizované specifické terapie onkologických pacientů
- Nobelova cena za chemii pro genetické nůžky: Objev, který změní naši budoucnost?
- Technologie na bázi RNA v klinické praxi: od přebarvených petúnií k terapii vzácných a dosud jen obtížně léčitelných chorob u lidí
- „Nepředstavovali jsme si, že náš výzkum povede přímo ke vzniku nových léků, dokonce ještě za našeho života“
- Bezplatné služby pro diagnostiku ATTRv amyloidózy pro kardiology
Nejčtenější v tomto čísle
- Mechanisms Employed by to Prevent Ribonucleotide Incorporation into Genomic DNA by Pol V
- Inference of Population Splits and Mixtures from Genome-Wide Allele Frequency Data
- Zcchc11 Uridylates Mature miRNAs to Enhance Neonatal IGF-1 Expression, Growth, and Survival
- Histone Methyltransferases MES-4 and MET-1 Promote Meiotic Checkpoint Activation in
Zvyšte si kvalifikaci online z pohodlí domova
Mazová zátka a její řešení
nový kurzVšechny kurzy