
Risk Models to Predict Chronic Kidney Disease and Its Progression: A Systematic Review
Background:
Chronic kidney disease (CKD) is common, and associated with increased risk of cardiovascular disease and end-stage renal disease, which are potentially preventable through early identification and treatment of individuals at risk. Although risk factors for occurrence and progression of CKD have been identified, their utility for CKD risk stratification through prediction models remains unclear. We critically assessed risk models to predict CKD and its progression, and evaluated their suitability for clinical use.
Methods and Findings:
We systematically searched MEDLINE and Embase (1 January 1980 to 20 June 2012). Dual review was conducted to identify studies that reported on the development, validation, or impact assessment of a model constructed to predict the occurrence/presence of CKD or progression to advanced stages. Data were extracted on study characteristics, risk predictors, discrimination, calibration, and reclassification performance of models, as well as validation and impact analyses. We included 26 publications reporting on 30 CKD occurrence prediction risk scores and 17 CKD progression prediction risk scores. The vast majority of CKD risk models had acceptable-to-good discriminatory performance (area under the receiver operating characteristic curve>0.70) in the derivation sample. Calibration was less commonly assessed, but overall was found to be acceptable. Only eight CKD occurrence and five CKD progression risk models have been externally validated, displaying modest-to-acceptable discrimination. Whether novel biomarkers of CKD (circulatory or genetic) can improve prediction largely remains unclear, and impact studies of CKD prediction models have not yet been conducted. Limitations of risk models include the lack of ethnic diversity in derivation samples, and the scarcity of validation studies. The review is limited by the lack of an agreed-on system for rating prediction models, and the difficulty of assessing publication bias.
Conclusions:
The development and clinical application of renal risk scores is in its infancy; however, the discriminatory performance of existing tools is acceptable. The effect of using these models in practice is still to be explored.
Please see later in the article for the Editors' Summary
Published in the journal:
. PLoS Med 9(11): e32767. doi:10.1371/journal.pmed.1001344
Category:
Research Article
doi:
https://doi.org/10.1371/journal.pmed.1001344
Summary
Background:
Chronic kidney disease (CKD) is common, and associated with increased risk of cardiovascular disease and end-stage renal disease, which are potentially preventable through early identification and treatment of individuals at risk. Although risk factors for occurrence and progression of CKD have been identified, their utility for CKD risk stratification through prediction models remains unclear. We critically assessed risk models to predict CKD and its progression, and evaluated their suitability for clinical use.
Methods and Findings:
We systematically searched MEDLINE and Embase (1 January 1980 to 20 June 2012). Dual review was conducted to identify studies that reported on the development, validation, or impact assessment of a model constructed to predict the occurrence/presence of CKD or progression to advanced stages. Data were extracted on study characteristics, risk predictors, discrimination, calibration, and reclassification performance of models, as well as validation and impact analyses. We included 26 publications reporting on 30 CKD occurrence prediction risk scores and 17 CKD progression prediction risk scores. The vast majority of CKD risk models had acceptable-to-good discriminatory performance (area under the receiver operating characteristic curve>0.70) in the derivation sample. Calibration was less commonly assessed, but overall was found to be acceptable. Only eight CKD occurrence and five CKD progression risk models have been externally validated, displaying modest-to-acceptable discrimination. Whether novel biomarkers of CKD (circulatory or genetic) can improve prediction largely remains unclear, and impact studies of CKD prediction models have not yet been conducted. Limitations of risk models include the lack of ethnic diversity in derivation samples, and the scarcity of validation studies. The review is limited by the lack of an agreed-on system for rating prediction models, and the difficulty of assessing publication bias.
Conclusions:
The development and clinical application of renal risk scores is in its infancy; however, the discriminatory performance of existing tools is acceptable. The effect of using these models in practice is still to be explored.
Please see later in the article for the Editors' Summary
Introduction
Chronic kidney disease (CKD) is increasingly common in the US and worldwide [1],[2]. Related complications, including end-stage renal disease (ESRD) and cardiovascular disease (CVD), have major public health and economic implications [1]–[3]. Screening for CKD has been somewhat controversial in the absence of direct evidence from a randomized clinical trial [4]. However, early identification of individuals with CKD, especially targeting populations with a high risk for CKD and related adverse outcomes [5], followed by the implementation of evidence-based interventions can slow or prevent the progression to advanced stages of the disease, reduce the risk of CVD and other complications of decreased glomerular filtration rate (GFR), and improve survival and quality of life [6]. However, large proportions of individuals with CKD remain undiagnosed and, as a consequence, are not benefiting from those interventions. For instance, in the US, awareness of CKD in the general population remains very low [1]. During the 1999–2004 period, the proportion of US adults with stage 3 CKD who reported being aware of their status was only 11.6% in men and 5.5% in women. Even among men with stage 3 CKD and elevated albuminuria, awareness of weak or failing kidneys was only 22.8%. Among those with stage 4 CKD, the corresponding percentage was 42% for both men and women [1]. In clinical settings, awareness levels are also low. Data from the US National Kidney Foundation's Kidney Early Evaluation Program, for the 2000–2009 period, indicate that only 9% of patients with CKD are aware of their diagnosis [7].
Strategies for early identification and treatment of people with CKD are therefore needed worldwide. The use of complex and potentially expensive detection strategies may prevent those at risk from deriving the benefits of preventative interventions, especially in settings where renal replacement therapy is not readily available. Several risk factors that are independently associated with the occurrence of CKD and easily assessable in routine clinical settings have been incorporated in model equations for predicting the occurrence of CKD or progression in people already diagnosed with CKD. These models have utility even in the context of automatic reporting of the estimated GFR (eGFR). Indeed, recent data indicate that referral to a nephrologist by primary care physicians as the result of making eGFR available mostly occurs for certain subgroups in the population (women and elderly), and a high proportion of referrals are inappropriate [8].
The use of risk models is very attractive and likely cost-effective for large-scale CKD risk stratification, and would allow the identification of all the segments of the population that would benefit the most from CKD detection. To this end, it is very important that existing models are not methodologically flawed, and that they provide accurate estimates of the CKD risk in different populations.
To date, there has been no effort, to our knowledge, to provide decision makers and healthcare providers with a balanced account of the performance of existing CKD risk models. We therefore systematically reviewed studies of risk equations to predict CKD or its progression, with the objectives of summarizing evidence on their performance and exploring methodological issues surrounding their development and validation and application.
Methods
We performed literature searches to identify all risk models developed to predict the presence/occurrence of CKD, or to predict the progression of CKD in those with the disease. We also searched for all studies that applied existing CKD risk models either in the population from which the model was developed or in different populations, and, lastly, we searched for all impact studies and clinical practice guidelines that incorporated existing CKD risk models.
Model Development and Validation Studies
Data sources and search strategy
We searched the PubMed MEDLINE and Embase databases from 1 January 1980 to 20 June 2012, for English - or French - language studies of CKD risk prediction model development and/or validation. We used a combination of search terms related to CKD and prediction. The search strategies are provided in detail in Texts S2 and S3. In addition, we manually searched the reference lists of eligible studies and relevant reviews, and traced studies that had cited them through the ISI Web of Science to find additional published and unpublished data.
Study selection
Two evaluators (J. B. E. and A. P. K.) independently identified articles and sequentially screened them for inclusion (Figure 1). Where necessary, the full text of articles and/or supplemental materials (tables and appendices) was reviewed before deciding on inclusion. Disagreements were solved by consensus between both authors.
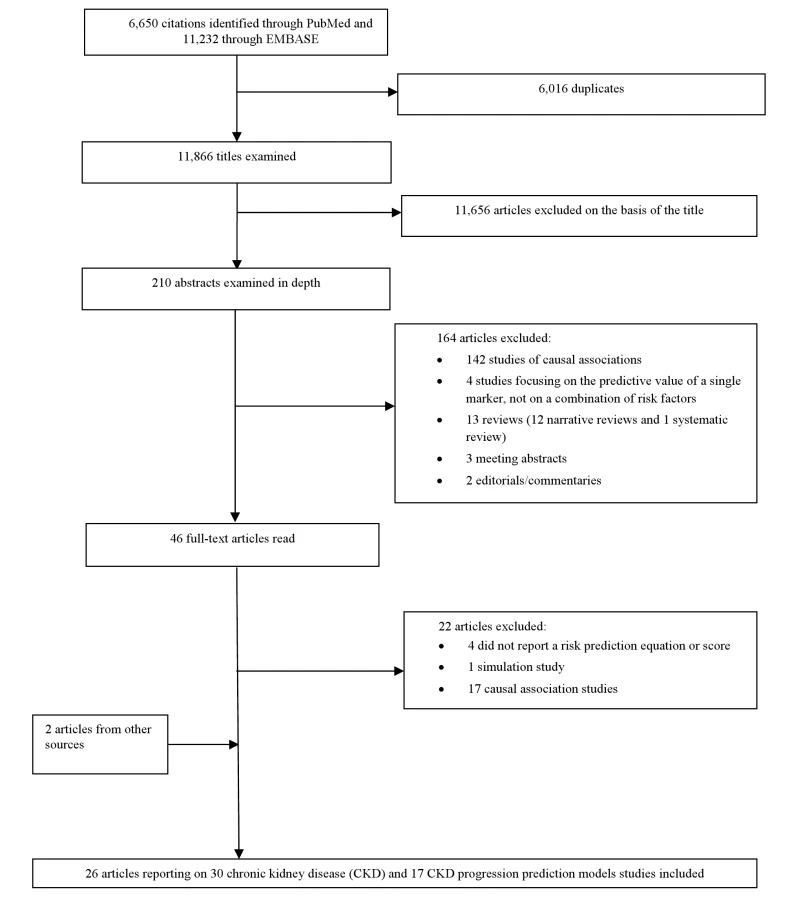
Eligible articles had to report a risk assessment tool (equation and/or score) for predicting CKD or its progression, derived in adult human populations. Reporting of quantitative measures of the performance of tools was preferable, but not necessary for inclusion. The reported metrics of evaluation of predictive ability could be the area under the receiver operating characteristic curve (AUC) or C-statistic, reclassification percentage, net reclassification improvement (NRI), or integrated discrimination improvement index (IDI). These metrics are recognized and used for the assessment of prediction models [9],[10]. We excluded studies that reported only measures of association between risk factors and CKD without information on the beta coefficients of variables included in a prediction equation, and simulation studies.
Data extraction and quality assessment
Two reviewers (J. B. E. and A. P. K.) independently conducted the data extraction and quality assessment. We did not use a particular framework for quality assessment, as there is no consensus on a quality assessment framework for risk prediction models. Consequently, we did not develop a formal protocol for the review (Text S1). From each study, we extracted data on study design, setting, population characteristics, the number of patients in the derivation and validation cohorts, the number of participants with the outcome of interest, the number of candidate variables tested as predictors, and the number and list of those variables included in the final model, as well as the type of statistical model used. For the discriminative performance of models, we extracted information on the AUC or C-statistic, which indicates the ability of a risk model to rank-order individuals' risks. To describe model calibration, we extracted data on the difference between the observed and predicted rates of CKD, as well as the p-value of the corresponding test statistic. Measures of calibration assess the ability of a risk prediction model to predict accurately the absolute level of risk that is subsequently observed.
For the assessment of reclassification, we extracted the NRI and IDI values, and the accompanying 95% CIs and p-values, when available. Reclassification analyses generally indicate the proportion of individuals who are reclassified from one risk stratum (based on estimated risk provided from a first model) to a different risk stratum (based on estimated risk from a different model, or a model that has additional variables compared with the first model). The IDI measures the extent to which the use of a new risk marker correctly revises upward the predicted risk of individuals who experienced the event of interest and correctly revises downward the predicted risk of individuals who did not experience the event.
Data synthesis
Given the wide range of metrics used for the assessment of the predictive ability of CKD risk models, and the heterogeneity in both the risk factors used for prediction and their number, as well as the study designs, we opted to conduct a narrative synthesis of the evidence instead of a meta-analysis.
Impact Studies and Implementation of Risk Models in Guidelines
Impact studies were captured by (1) scanning those publications identified through the search strategy for model development and validation, and (2) applying the search strategy for impact studies proposed by Reilly and Evans [11], which combines the model's acronym, name of the cohort, or first author with a specific search term (Text S3). We searched relevant clinical practice guidelines to investigate the implementation of CKD prediction models in countries in which such models have been developed. In the absence of validated strategies for these types of searches, we targeted guidelines (when available in English language) compiled by a selection of organizations known to be involved in issues relating to kidney diseases, including the American Society of Nephrology (http://www.asn-online.org), the US National Kidney Foundation [12], the UK National Institute for Health and Clinical Excellence [13], the International Society of Nephrology [14], the European Renal Association–European Dialysis and Transplant [15], the Canadian Society of Nephrology [16], Kidney Disease: Improving Global Outcomes [17], The Korean Society of Nephrology (http://www.ksn.or.kr/english/), the Japanese Society for Dialysis Therapy [18], The Japan Association of Chronic Kidney Disease Initiatives (J-CKDI) [19], and the Taiwan Society of Nephrology [20].
Results
Figure 1 describes the study selection process. Of the citations identified through searches, 210 abstracts were selected for in-depth evaluation, and 46 full-text publications were reviewed. After all exclusions, 26 articles, reporting on 30 CKD prediction risk scores and 17 CKD progression risk scores, met the eligibility criteria and were included in the review.
CKD Prediction Risk Scores
Table 1 summarizes data from studies that developed CKD risk prediction models. Five of the 30 CKD risk prediction models were developed using cross-sectional data (thus, prevalent CKD) [21]–[24], and the remaining models were based on cohort studies.

Populations, outcomes, and risk factors
The majority of the 30 CKD risk models were developed from samples that mostly included white individuals, and only four studies included exclusively Asian participants [23]–[26]. The number of participants included in the studies ranged from 534 to 1.6 million, and their ages ranged from 18 to 90 y. The length of follow-up in the cohort studies ranged from 1 to 10 y.
The definition of CKD was fairly consistent across prediction models (eGFR<60 ml/min/1.73 m2), although nine models focused on predicting diabetic nephropathy [22], and another on CKD prediction among HIV-positive individuals [26]. The included risk models used the Modification of Diet in Renal Disease (MDRD) Study equation to estimate GFR, with the exception of models from the ADVANCE study [27], which used estimates from the Chronic Kidney Disease Epidemiology Collaboration (CKD-EPI) equation. The original MDRD equation is eGFR (ml/min/1.73 m2) = 175×standardized Scr (mg/dl)−1.154×age (y)−0.203×1.212 [if black]×0.742 [if female], where Scr is serum creatinine [28]. The less used CKD-EPI equation is eGFR (ml/min/1.73 m2) = 141×min(Scr/κ, 1)α×max(Scr/κ, 1)−1.209× 0.993age×1.018 [if female]×1.159 [if black], where Scr is serum creatinine, κ is 0.7 for females and 0.9 for males, α is −0.329 for females and −0.411 for males, min indicates the minimum of Scr/κ or 1, and max indicates the maximum of Scr/κ or 1 [29].
Ten studies provided usable data on the numbers of candidate variables tested for inclusion in the models. This number ranged from one to 24, giving conservative estimates of the ratio of the number of observed events (outcome of interest) to the number of candidate variables ranging from six to 166. The predictors most commonly included in the final prediction models were age, sex, body mass index, diabetes status, systolic blood pressure, serum creatinine, a measure of proteinuria, and serum albumin or total protein (Table S1). Three studies used novel biomarkers or genetic or circulating factors [22],[30],[31]. Eighteen models were derived using logistic regressions, and three using Cox regressions. All studies reported the original model with beta coefficients, and five studies presented additional point-based scoring systems [21],[27],[32], or risk calculators [33],[34].
Performance of risk prediction models
Table 1 shows the performance of the various CKD risk models. All the included studies reported a C-statistic ranging from 0.57 to 0.88, indicating a modest-to-good discriminatory performance. Nine risk scores were internally validated, through split-sample validation in four cases (three of these were also externally validated), and bootstrapping in five other studies. Twelve risk models had an estimate of calibration: Hosmer-Lemeshow test statistics in most cases, which generally indicated good calibration.
CKD model improvement
Four studies assessed model improvement subsequent to adding extra variables. One study reported a significant improvement after adding circulating biomarkers (aldosterone and homocysteine) to traditional CKD risk factors [30]; the difference in AUC was 0.012 (p = 0.00233), NRI 6.9% (p = 0.0004), and IDI 0.013 (p = 0.004). The second study reported an AUC difference of 0.001 (p = 0.2) for adding genotypic information (16 single nucleotide polymorphisms) to known risk factors [31]. The third study reported no statistically significant improvement from adding uric acid, postprandial glucose, hemoglobin A1c, and proteinuria ≥ 100 mg/dl to traditional risk factors, with nonsignificant differences in AUC (−0.003), NRI (−0.0889), and IDI (0.0141) [25]. The last study found that a model for predicting major renal events using eGFR and albumin/creatinine ratio (ACR) (AUC: 0.818) was superior to models with either of the predictors alone (AUC: 0.779 for eGFR, and 0.752 for ACR); all three models were inferior to an expanded model with five additional variables (AUC: 0.847) (all p<0.05 for AUC comparison) [27]. In the same study, the eGFR+ACR (AUC: 0.629) and ACR alone (AUC: 0.627) models had similar performance for predicting new-onset albuminuria; both were superior to the eGFR alone model (AUC: 0.543) (both p<0.05), while all three were inferior to an extended model (AUC: 0.647) with six extra variables (all p<0.05 for AUC comparison) [27].
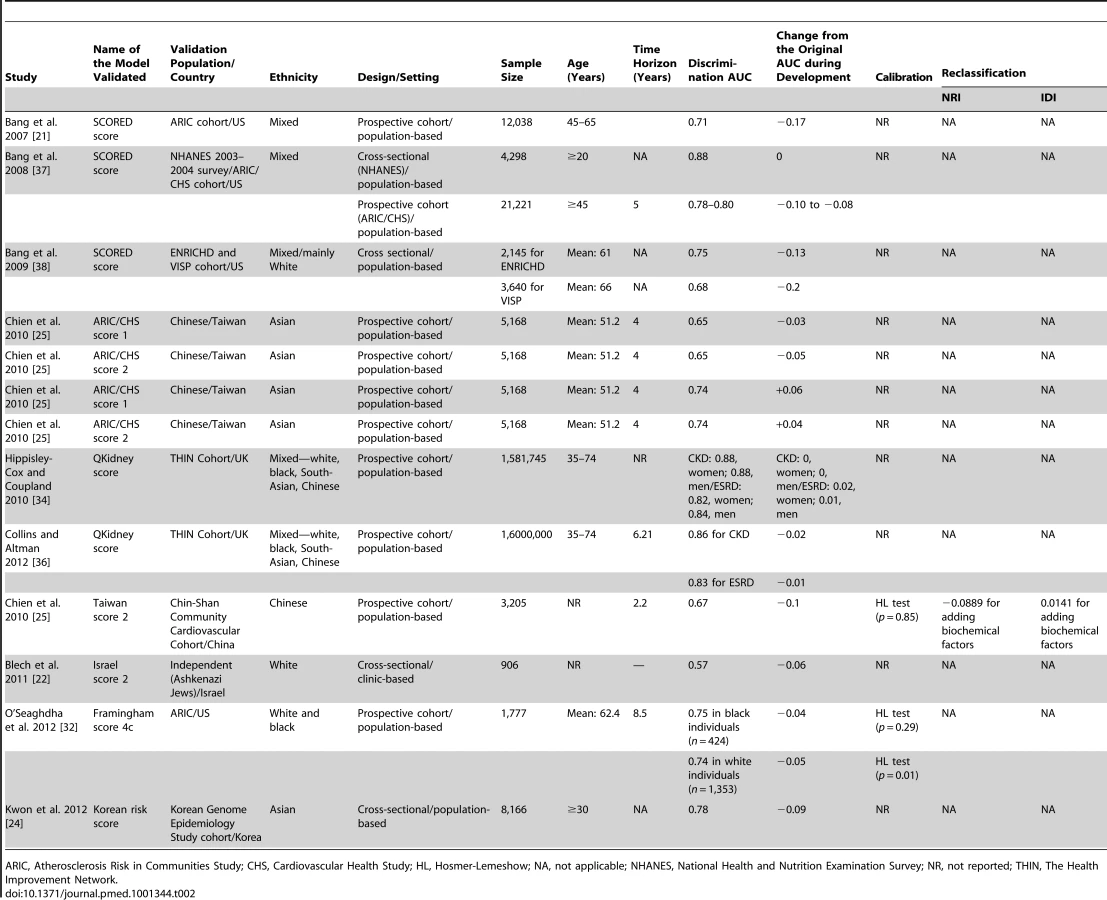
Validation of CKD risk prediction models
Table 2 shows the results of the external validation of CKD risk models. Only eight of the models were externally validated. Of these, only four models were validated more than once: twice for three models [25],[34]–[36] and three times for one model [21],[37],[38]. The AUC in validation studies (0.57 to 0.88) was generally lower than that in the derivation sample; the change from the original C-statistic from when the model was first derived ranged from −0.2 to +0.06 (Table 2), being negative or null except in two cases of validation of one score where it was positive [25], thus indicating a generally lower discrimination in validation populations. In the validation populations, the calibration was also poorer, though it was not assessed in most of validation studies.
Risk Scores for Predicting Progression of CKD to ESRD
Table 3 shows the models for the prediction of progression to later stages among people with already established CKD. We found 17 CKD progression risk scores, developed from Cox regression models using data from clinical settings, mainly in white populations. Two of the CKD progression risk scores were developed from a cohort of people with type 2 diabetes and nephropathy [39],[40], and three other scores used cohorts of people exclusively with IgA nephropathy [41]–[43]. The risk factors included in CKD progression risk models varied. The number of candidate variables tested for inclusion in the models ranged from ten to 24, corresponding to a ratio of number of observed events (outcome of interest) to number of candidate variables of four to 16. For one risk model, the performance in the derivation sample was not reported [39], although the performance of the score was later assessed in a validation study conducted in a different population. When evaluated, the C-statistic of these models ranged from 0.56 to 0.94, and calibration (reported for two models only) was good. In addition to reporting beta coefficients for regression models, four studies also provided a point-based scoring system [42]–[44] or a risk calculator [45].

As shown in Table 4, five of the CKD progression risk models were externally validated (C-statistic: 0.83 to 0.91); the change in C-statistic from the original value when the model was first developed ranged from −0.1 to +0.03. This change was negative in all but one case, thus indicating a generally poorer discrimination.

Two studies investigated the improvement of three different CKD progression models [33],[40], after adding biomarkers to traditional risk factors (serum bicarbonate and phosphate in one case [33], and Troponin T plus brain natriuretic peptide in the two other cases) [40]. The change in C-statistic or AUC varied from 0.01 to 0.02, and NRI from 16.9% to 26.7%.
Impact Studies and Incorporation of CKD Prediction Models in Clinical Practice Guidelines
We found no evidence in guidelines of recommendations for using CKD risk prediction models to estimate the risk in patients either in clinical or community settings. We also did not find any studies assessing the impact of adopting CKD (occurrence and progression) risk scores in clinical practice on the process of care and outcomes of patients.
Discussion
This systematic review shows that a sizeable number of renal risk prediction models have been developed, with, however, variation in their quality. Reasons for this may be specific to nephrology, where risk prediction is still in its infancy and the methodology for predictive research may be underappreciated. Despite the heterogeneity of CKD, with several specific forms, this review demonstrates the feasibility of defining individual renal risk using a combination of commonly assessed variables. Indeed, there was remarkable similarity between the variables that entered the prediction models (Tables S1 and S2), each developed in a distinct group of participants, sometimes with specific forms of CKD. The discriminative performance of existing models was generally acceptable-to-good on the derivation sample. However, when corrected for overfitting (internal validation) or tested in a new population (external validation), this discriminative performance was modest-to-acceptable. For CKD risk prediction, the SCORED model appears to be the most reliable, as it is the most externally validated model, with a reasonable discrimination [21]. Regarding CKD progression, no risk model has been extensively validated in different populations.
Potential Public Health and Clinical Applications of CKD Risk Models
Risk prediction models have potential applications in the prevention and management of CKD. Risk communication to patients may motivate them for lifestyle modification and adherence to prescribed therapies. Using models for predicting progression of CKD, clinicians may be able to tailor disease-modifying therapies as well as frequency of monitoring to individual risk. Indeed, therapies for controlling several variables included in CKD progression models (e.g., diabetes and hypertension) have been shown to delay CKD progression. Furthermore, using CKD progression models to identify patients who are most likely to need renal replacement therapy would allow patient education on available therapeutic options. CKD risk scores may be useful in the assessment of novel technologies or biomarkers for risk prediction, or for patient recruitment in prevention trials. They can also serve in mass screening and public education initiatives. For all these applications, estimates of CKD risk from prediction models must be accurate and validated.
Development of Existing CKD Risk Prediction Models
The performance of prediction models is largely determined by the appropriateness of the methodological approaches used to develop them. Virtually none of the existing CKD models was developed using data specifically collected for risk modeling purposes. This may raise concerns about the quality of the predictors and outcomes tested/included in the models, as well as the completeness of measurements. Lessons learned from CVD prediction suggest that the source of data for model development matters less, provided that the ensuing model can reliably predict the outcome of interest in different populations [46]. Indeed, in practice, assembling data only for the purpose of modeling can be challenging, and researchers tend to rely on available data collected for other reasons [9]. At least four of the models were likely statistically underpowered, based on having a ratio of the number of outcomes to the number of candidate predictors of <8 [24],[26],[40],[41],[47]. The performance of such models tends to drop substantially when the model is applied to different populations [24]. Other mistakes that affect model performance were present across studies, including dichotomization of continuous variables prior to modeling, linearity assumptions without formal testing, and exclusion of participants with missing values on predictor/outcome variables.
Internal Validation of Existing CKD Prediction Models
One model was published without indicators of performance during the derivation process [39]. Most models provided measures of performance, which were based on the direct application of the model to the derivation sample (apparent performance). This approach is optimistic (self-fulfilling prophecy). Some models provided performance measures from internal split-sample or bootstrap validation, which may provide the new user with an idea about what to expect when applying the model to different populations. When reported, discrimination was always good for CKD progression models, and acceptable-to-good for prevalent/incident CKD models, indicating that these models were able to differentiate participants with CKD from those without in the derivation sample. Calibration, a key property of model performance, was less commonly assessed during the derivation process. Whether calibration performance of a model in one population can inform its behavior in another population is still debated. However, there is a growing agreement that, because calibration is largely affected by the background risk, which varies across populations, models need to be updated through recalibration procedures to provide accurate estimates of the risk in new populations. There have been attempts to update some of the existing CKD models, but the procedures used (addition of extra variables) have focused on improvement in discriminatory performance [25],[27],[30],[31], and only one study reported change in the calibration properties [27].
External Validation of Existing CKD Risk Prediction Models
The demonstration of the performance of a model in new populations is an important step before recommending its widespread use. A limited number of existing CKD prediction models have been tested on different populations [21],[22],[25],[32]–[35],[45]. Validation studies have mainly been conducted by the same group of investigators who developed the models. This is methodologically inferior and quantitatively insufficient to provide good indicators of models' behavior in various populations. Hence, more validation studies of existing models are needed, ideally by different investigators, to guarantee their generalizability to a larger number of people. Instead of developing new models for their own setting, investigators in the field of CKD may consider integrating aspects of the validation of existing models into future studies. In addition to providing indicators of the performance of existing models in various settings, such an approach limits unnecessary development of new models.
Implementation of Existing CKD Prediction Models
CKD models have largely been published in the form of mathematical equations, with point-scoring systems [21],[32],[42]–[44] or calculators [33],[34],[45] for a few. The mathematical format may not be suitable for application in various settings, particularly by busy clinicians who may be less familiar with manipulating complex formulas. Translation efforts are therefore needed to convert accurate and validated CKD prediction equations into simple tools that can improve their uptake in various settings [33]. Some context-specific efforts may also be required to derive appropriate cutoffs for defining high-risk status when models are integrated in guidelines for screening. It is, however, important to confirm whether the implementation of CKD risk prediction models affects the behavior of healthcare providers and improves outcomes of care. At present, no implementation study of CKD risk prediction models has been conducted.
Published studies have relied on GFR estimated from the MDRD equation to define CKD [28]. The MDRD equation provides less accurate estimates of GFR in different ethnic groups, compared with estimates derived from the more recent CKD-EPI equation [29], resulting in “over-diagnosis” of CKD using the MDRD equation. There have been suggestions that this over-diagnosis may have little effect on estimates of the association between risk factors and CKD outcomes [24],[32] and, accordingly, on discriminatory performance when models developed to predict the outcome of CKD based on the MDRD equation are applied to the outcome of CKD based on the CKD-EPI formula. However, the difference in prevalence/incidence of CKD based on the two formulas will invite recalibration of MDRD equation–based models to improve their applicability with the increasing international adoption of CKD-EPI estimates of GFR for CKD diagnosis.
Participants in the reviewed studies were overwhelmingly white. A homogenous population does not allow researchers to probe into the whole scope of the variability in CKD risk. This is even more important for CKD than for other diseases, as some ethnic groups are particularly prone to CKD (e.g., African-Americans), and the use of risk stratification tools in these groups may be more warranted. Future studies should therefore incorporate more participants of different ethnic backgrounds.
Strengths and Limitations of the Review
The strengths of this review include the exclusion of studies that reported only effect estimates for independent association of risk factors with CKD. These measures alone provide no information on model calibration and global discriminative performance. The case for predictive testing depends not merely on the magnitude of the risk ratio, but also on the extent to which the test results are useful for improving prediction of disease when various risk factors are accounted for. This systematic review may also help policy makers decide whether to incorporate risk tools in guidelines for screening, routine evaluation, and management of CKD. Such an inclusion may be premature at this point in time, particularly in the absence of extensive external validation studies and impact analyses. We did not explicitly rank or categorize the quality of existing CKD risk models, mindful that there is no agreed-on scientific system for rating risk prediction model quality. Some will argue that minimizing risk for potential bias is of critical importance, while others might support the view that a risk score should be judged on its ability to perform accurately across diverse settings. Finally, our ability to assess publication bias was limited.
Conclusion
This review suggests that risk models for predicting CKD or its progression have a modest-to-acceptable discriminatory performance, but would need to be better calibrated and externally validated—and the impact of their use on outcomes assessed—before these are incorporated in guidelines. Their potential application for screening or management to identify CKD in a heterogeneous population will also depend on the context. In the US, for example, the adoption of the Kidney Disease Outcomes Quality Initiative guidelines has led to systematic reporting of eGFR by laboratories whenever serum creatinine is requested. Consequently, a certain degree of de facto opportunistic CKD screening is happening. In such a context, risk scores for predicting CKD progression or outcomes would be particularly useful for defining prognosis in identified people. However, an important fraction of the population at high risk of CKD without access to care could still be identified in the community using CKD risk prediction tools.
Supporting Information
Zdroje
1. CoreshJ, SelvinE, StevensLA, ManziJ, KusekJW, et al. (2007) Prevalence of chronic kidney disease in the United States. JAMA 298 : 2038–2047.
2. ZhangQL, RothenbacherD (2008) Prevalence of chronic kidney disease in population-based studies: systematic review. BMC Public Health 8 : 117.
3. KhanS, AmediaCAJr (2008) Economic burden of chronic kidney disease. J Eval Clin Pract 14 : 422–434.
4. FinkHA, IshaniA, TaylorBC, GreerNL, MacDonaldR, et al. (2012) Screening for, monitoring, and treatment of chronic kidney disease stages 1 to 3: a systematic review for the U.S. Preventive Services Task Force and for an American College of Physicians Clinical Practice Guideline. Ann Intern Med 156 : 570–581.
5. UhligK, LeveyAS (2012) Developing guidelines for chronic kidney disease: we should include all of the outcomes. Ann Intern Med 156 : 599–601.
6. LeveyAS, CoreshJ (2012) Chronic kidney disease. Lancet 379 : 165–180.
7. Whaley-ConnellA, ShlipakMG, InkerLA, Kurella TamuraM, BombackAS, et al. (2012) Awareness of kidney disease and relationship to end-stage renal disease and mortality. Am J Med 125 : 661–669.
8. AkbariA, GrimshawJ, StaceyD, HoggW, RamsayT, et al. (2012) Change in appropriate referrals to nephrologists after the introduction of automatic reporting of the estimated glomerular filtration rate. CMAJ 184: E269–E276.
9. MoonsKG, KengneAP, WoodwardM, RoystonP, VergouweY, et al. (2012) Risk prediction models: I. development, internal validation, and assessing the incremental value of a new (bio)marker. Heart 98 : 683–690.
10. MoonsKG, KengneAP, GrobbeeDE, RoystonP, VergouweY, et al. (2012) Risk prediction models: II. external validation, model updating, and impact assessment. Heart 98 : 691–698.
11. ReillyBM, EvansAT (2006) Translating clinical research into clinical practice: impact of using prediction rules to make decisions. Ann Intern Med 144 : 201–209.
12. National Kidney Foundation (2002) K/DOQI clinical practice guidelines for chronic kidney disease: evaluation, classification, and stratification. Am J Kidney Dis 39: S1–S266.
13. National Collaborating Centre for Chronic Conditions (2008) Chronic kidney disease: early identification and management of chronic kidney disease in adults in primary and secondary care. NICE clinical guideline 73. London: National Institute for Health and Clinical Excellence. Available: http://www.nice.org.uk/nicemedia/live/12069/42117/42117.pdf. Accessed 10 October 2012.
14. International Society of Nephrology (2012) Clinical practice guidelines. Available: http://www.theisn.org/isn-information/clinical-practice-guidelines/itemid-482. Accessed 5 May 2012.
15. HeemannU, AbramowiczD, SpasovskiG, VanholderR (2011) Endorsement of the Kidney Disease Improving Global Outcomes (KDIGO) guidelines on kidney transplantation: a European Renal Best Practice (ERBP) position statement. Nephrol Dial Transplant 26 : 2099–2106.
16. Canadian Society of Nephrology (2008) Guideline document library. Available: http://www.csnscn.ca/site/c.lnKKKOOvHqE/b.8079309/k.799F/Guideline_Document_Library.htm. Accessed 5 May 2012.
17. Kidney Disease: Improving Global Outcomes (2009) Clinical practice guidelines. Available: http://www.kdigo.org/clinical_practice_guidelines/index.php. Accessed 5 May 2012.
18. Japanese Society for Dialysis Therapy (2008) Guidelines. Available: http://www.jsdt.or.jp/guideline.html. Accessed 10 October 2012.
19. ImaiE, YasudaY, MakinoH (2011) Japan Association of Chronic Kidney Disease Initiatives (J-CKDI). Japan Med Assoc J 54 : 403–405.
20. Taiwan Society of Nephrology (2012) History and mission. Available: http://www.tsn.org.tw/englishVersion/History.aspx. Accessed 5 May 2012.
21. BangH, VupputuriS, ShohamDA, KlemmerPJ, FalkRJ, et al. (2007) SCreening for Occult REnal Disease (SCORED): a simple prediction model for chronic kidney disease. Arch Intern Med 167 : 374–381.
22. BlechI, KatzenellenbogenM, KatzenellenbogenA, WainsteinJ, RubinsteinA, et al. (2011) Predicting diabetic nephropathy using a multifactorial genetic model. PLoS ONE 6: e18743 doi:10.1371/journal.pone.0018743.
23. ThakkinstianA, IngsathitA, ChaiprasertA, RattanasiriS, SangthawanP, et al. (2011) A simplified clinical prediction score of chronic kidney disease: a cross-sectional-survey study. BMC Nephrol 12 : 45.
24. KwonKS, BangH, BombackAS, KohDH, YumJH, et al. (2012) A simple prediction score for kidney disease in the Korean population. Nephrology (Carlton) 17 : 278–284.
25. ChienKL, LinHJ, LeeBC, HsuHC, LeeYT, et al. (2010) A prediction model for the risk of incident chronic kidney disease. Am J Med 123 : 836–846.e2.
26. AndoM, YanagisawaN, AjisawaA, TsuchiyaK, NittaK (2011) A simple model for predicting incidence of chronic kidney disease in HIV-infected patients. Clin Exp Nephrol 15 : 242–247.
27. JardineMJ, HataJ, WoodwardM, PerkovicV, NinomiyaT, et al. (2012) Prediction of kidney-related outcomes in patients with type 2 diabetes. Am J Kidney Dis E-pub ahead of print. doi:10.1053/j.ajkd.2012.1004.1025.
28. LeveyAS, BoschJP, LewisJB, GreeneT, RogersN, et al. (1999) A more accurate method to estimate glomerular filtration rate from serum creatinine: a new prediction equation. Modification of Diet in Renal Disease Study Group. Ann Intern Med 130 : 461–470.
29. LeveyAS, StevensLA, SchmidCH, ZhangYL, CastroAF3rd, et al. (2009) A new equation to estimate glomerular filtration rate. Ann Intern Med 150 : 604–612.
30. FoxCS, GonaP, LarsonMG, SelhubJ, ToflerG, et al. (2010) A multi-marker approach to predict incident CKD and microalbuminuria. J Am Soc Nephrol 21 : 2143–2149.
31. O'SeaghdhaCM, YangQ, WuH, HwangSJ, FoxCS (2012) Performance of a genetic risk score for CKD stage 3 in the general population. Am J Kidney Dis 59 : 19–24.
32. O'SeaghdhaCM, LyassA, MassaroJM, MeigsJB, CoreshJ, et al. (2012) A risk score for chronic kidney disease in the general population. Am J Med 125 : 270–277.
33. TangriN, StevensLA, GriffithJ, TighiouartH, DjurdjevO, et al. (2011) A predictive model for progression of chronic kidney disease to kidney failure. JAMA 305 : 1553–1559.
34. Hippisley-CoxJ, CouplandC (2010) Predicting the risk of chronic kidney disease in men and women in England and Wales: prospective derivation and external validation of the QKidney Scores. BMC Fam Pract 11 : 49.
35. KshirsagarAV, BangH, BombackAS, VupputuriS, ShohamDA, et al. (2008) A simple algorithm to predict incident kidney disease. Arch Intern Med 168 : 2466–2473.
36. CollinsG, AltmanD (2012) Predicting the risk of chronic kidney disease in the UK: an evaluation of QKidney(R) scores using a primary care database. Br J Gen Pract 62 : 243–250.
37. BangH, MazumdarM, KernLM, ShohamDA, AugustPA, et al. (2008) Validation and comparison of a novel screening guideline for kidney disease: KEEPing SCORED. Arch Intern Med 168 : 432–435.
38. BangH, MazumdarM, NewmanG, BombackAS, BallantyneCM, et al. (2009) Screening for kidney disease in vascular patients: SCreening for Occult REnal Disease (SCORED) experience. Nephrol Dial Transplant 24 : 2452–2457.
39. KeaneWF, ZhangZ, LylePA, CooperME, de ZeeuwD, et al. (2006) Risk scores for predicting outcomes in patients with type 2 diabetes and nephropathy: the RENAAL study. Clin J Am Soc Nephrol 1 : 761–767.
40. DesaiAS, TotoR, JarolimP, UnoH, EckardtKU, et al. (2011) Association between cardiac biomarkers and the development of ESRD in patients with type 2 diabetes mellitus, anemia, and CKD. Am J Kidney Dis 58 : 717–728.
41. GotoM, KawamuraT, WakaiK, AndoM, EndohM, et al. (2009) Risk stratification for progression of IgA nephropathy using a decision tree induction algorithm. Nephrol Dial Transplant 24 : 1242–1247.
42. GotoM, WakaiK, KawamuraT, AndoM, EndohM, et al. (2009) A scoring system to predict renal outcome in IgA nephropathy: a nationwide 10-year prospective cohort study. Nephrol Dial Transplant 24 : 3068–3074.
43. WakaiK, KawamuraT, EndohM, KojimaM, TominoY, et al. (2006) A scoring system to predict renal outcome in IgA nephropathy: from a nationwide prospective study. Nephrol Dial Transplant 21 : 2800–2808.
44. JohnsonES, ThorpML, PlattRW, SmithDH (2008) Predicting the risk of dialysis and transplant among patients with CKD: a retrospective cohort study. Am J Kidney Dis 52 : 653–660.
45. LandrayMJ, EmbersonJR, BlackwellL, DasguptaT, ZakeriR, et al. (2010) Prediction of ESRD and death among people with CKD: the Chronic Renal Impairment in Birmingham (CRIB) prospective cohort study. Am J Kidney Dis 56 : 1082–1094.
46. van DierenS, BeulensJW, KengneAP, PeelenLM, RuttenGE, et al. (2012) Prediction models for the risk of cardiovascular disease in patients with type 2 diabetes: a systematic review. Heart 98 : 360–369.
47. HallanSI, RitzE, LydersenS, RomundstadS, KvenildK, et al. (2009) Combining GFR and albuminuria to classify CKD improves prediction of ESRD. J Am Soc Nephrol 20 : 1069–1077.
48. HalbesmaN, JansenDF, HeymansMW, StolkRP, de JongPE, et al. (2011) Development and validation of a general population renal risk score. Clin J Am Soc Nephrol 6 : 1731–1738.
49. AlssemaM, NewsonRS, BakkerSJ, StehouwerCD, HeymansMW, et al. (2012) One risk assessment tool for cardiovascular disease, type 2 diabetes, and chronic kidney disease. Diabetes Care 35 : 741–748.
50. KentDM, JafarTH, HaywardRA, TighiouartH, LandaM, et al. (2007) Progression risk, urinary protein excretion, and treatment effects of angiotensin-converting enzyme inhibitors in nondiabetic kidney disease. J Am Soc Nephrol 18 : 1959–1965.
Štítky
Interní lékařstvíČlánek vyšel v časopise
PLOS Medicine
2012 Číslo 11
- Ivabradin zlepšuje kvalitu života starších pacientů se srdečním selháním
- Fixní kombinace kandesartan/amlodipin v terapii arteriální hypertenze
- Inovace v hojení ran: krytí Zetuvit Plus Silicone Border pro optimální management exsudátu z ran
- Rána vizitkou (nejen) chirurga
- Patogeneze vzniku keloidní jizvy
Nejčtenější v tomto čísle
- Screening for Chronic Kidney Disease: Preventing Harm or Harming the Healthy?
- The Long-Term Health Consequences of Child Physical Abuse, Emotional Abuse, and Neglect: A Systematic Review and Meta-Analysis
- G6PD Deficiency Prevalence and Estimates of Affected Populations in Malaria Endemic Countries: A Geostatistical Model-Based Map
- Screening and Rapid Molecular Diagnosis of Tuberculosis in Prisons in Russia and Eastern Europe: A Cost-Effectiveness Analysis
Zvyšte si kvalifikaci online z pohodlí domova
Mazová zátka a její řešení
nový kurzVšechny kurzy