
A PHONEME CLASSIFICATION USING PCA AND SSOM METHODS FOR A CHILDREN DISORDER SPEECH ANALYSIS
Authors:
Josef Vavrina; Pavel Grill; Vaclav Olsansky; Jana Tuckova
Authors‘ workplace:
Czech Technical University, Prague, Czech Republic
Published in:
Lékař a technika - Clinician and Technology No. 2, 2012, 42, 85-88
Category:
Conference YBERC 2012
Overview
Mathematical-engineering methods described in the paper are oriented towards the analysis of disordered children’s speech with the diagnosis of Developmental Dysphasia (DD). The paper is divided into three parts. The first one shows briefly our aim to classify consonants using Supervised Self-Organizing Maps (SSOM). The second part is about phoneme parameterization using Mel-Frequency-Cepstral-Coefficients (MFCC), Linear-Predictive-Coding coefficients (LPC) with Principal Component Analysis (PCA). A possibility of clusters visualization is used for a monitoring of disorder proportions and therapy success. The last part describes the importance of vocalic triangle for children with DD and connects the formant frequencies with the second part of the paper.
Keywords:
phoneme detection, children speech, PCA, SSOM, vocalic triangle
Introduction
This paper deals with the detection and classification of phonemes (vowels and consonants) extracted from the children's speech. The classification uses two groups – phonemes obtained from utterances of healthy children and utterances of children with developmental dysphasia. The aim of this method is also a graphical representation of phonemes – cluster visualization. Graphic display in 2D or 3D is suitable for diagnose of disease by doctors. Analysis of layout and movement of the features in the SSOM can be one of the symptoms of the neurological disease identification. [1] The topic is a part of a joint project of the Laboratory of Artificial Neural Network Applications (LANNA) from the Department of Circuit Theory in CTU FEE and the Department of Child Neurology of the Motol University Hospital. Our research in this area is focused on searching for the relation between clinical and electrophysiological symptoms of children with DD. Developmental dysphasia is one of the most frequently occurring neurodevelopment disorders affecting 5% of the paediatric population [2]. The condition is frequently defined as an inability to acquire and learn normal communication skills in proportion to age, even though there is adequate peripheral hearing, intelligence and absence of a broad sensor motor deficit or congenital malformation of the speech or vocal systems.
Utterances were created by clinical psychologist. The aim is the 2D or 3D phoneme representation, so it is necessary to do some dimension reduction of the input speech signal. The proper dimension reduction is parameterization. Parameterized segments of speech signal of particular vowels and consonants became input vectors. Different types of parameterization were used: LPC coefficients, MFCC and formant frequencies [3]. The second dimension reduction used in the paper is PCA [4] and SSOM [6], [7].
Phonemes characterization
It's important for correct classification to focus where consonants are created. They are created by so-called consonant articulation, it means that way for exhaled air is blocked and blowing air around this obstruction is started to ripple. Sound which was created has noisy character. Czech consonants are divided into a few groups according to their origin: explosives (b, d, g, k, t, m, n, p), fricatives (f, h, ch, ř, s, š, v, x, z, ž), sonors (r, l, j) and affricates (c, č). Vowels have a tonal character. They are characterized by the fundamental frequency and vowel formants, which are dependent on the shape of the basic wave tone (the method of vibration of vocal cords). Formants for individual vowels are different and characteristic for them. We distinguish vowels a, e, i, o, u in Czech [7].
Data and Software
Our database contains records of healthy children and children with DD from 8 to 10 years old. We collect data for pilot study from psychologists, speech therapists, neurologists, MRI and EEG records. Our goal is to objectify the degree of DD. There are 12 children with DD in the pilot study. The records contain isolated vowels, several syllabic words and also whole sentences. These records were labelled manually phoneme by phoneme. MFCC were calculated from the labelled data - 16 MFCC, 20ms long, 50% overlap, Hamming window. 8 LPC were calculated with the same parameters as MFCC. The data of healthy children are used for training and validation, this set contains utterance of more than 60 children. The data of children with DD are used for testing [8].
We use formant analysis for the processing of speech pathology. The existence of formants can be related to the activity of the human brain and movements taking place in a person’s articulatory system. FORANA [9] software was developed in the MATLAB. The software was developed to find the formant frequencies correctly. Standardly, the extraction of formant frequencies from speech signals was done by PRAAT [10] - acoustic analysis software. In the classification of formants the results obtained using this approach could not be treated as relevant. A decision was made to develop software, which would be able to classify formants with a minimal error rate. Another factor, which was taken into consideration in designing the FORANA, was the need to automate the process of extracting formants from the recorded speech signals.
The original program SOMLab was used for data processing [11]. Kohonen's SSOM were used for classification of consonants [5].
The original software SpeechLab package [12] in MATLAB was used for speech pre-processing. It is a complex system which was created as a user friendly application of the neural networks in prosody modelling of synthetic speech. The project consists of the tools necessary for utilizing neural networks in prosody modelling. Individual tools can be divided into three categories: pre-processing, processing and postprocessing tools. We use pre-processing tool for data preparation, data creation and analysis.
Training ANN for consonants classification
Particular maps were trained separately for words with the same number of syllables and for recordings of children with the same age [1]. Co-articulation had important role at classification of formant frequencies. Explosives were found dominantly in these maps. It shows occurrence formant frequencies, which can be occurring by co-articulation effect of neighbouring vowels. Fig. 1 shows an example of one of the map.

Size of clusters was dependent at occurrence of particular consonant. It turned out during the comparing of maps that polysyllabic words have important role for children with DD.
Method of parameterization and dimension reduction
Principal component analyses which reduce dimensions, is used in method of vowel classification.
It is based on preserving first dimensions (PC – principal component), which contain a maximum information (the largest variance), and inhibiting higher PCs with less valuable information. It is not known in advance, if the MFCC and LPC contain the most information for vowel detection in their first PCs or whether the MFCC or LPC contain different information, which has high variance among speakers, which is not useful for vowel detection. The part of the paper is about finding the best PCs for vowel detection using MFCC and LPC.
Function of classifier
The method for finding the best PCs, is based on correct vowel clustering. The model for vowel classification divides the space into 5 sub-spaces according to 5 vowels in Czech. The space is divided by finding centroid for each vowel – mean of all segments of each vowel. Each new segment is classified to one vowel by finding nearest centroid. The method classifies whole vowel and not only segments. The final classified vowel is the one to which was assigned to most segments.
Finding PCs for parameterization MFCC and LPC
Training data set contains segments with 16 MFCC. If this space is transformed into new dimensions, which PCA produces, the new dimensions (PCs) variance is expressed in Tab. 1, which shows the information value of each dimension. For example, the first three dimensions preserve about 80 % of the original data.

Individual dimensions may not properly classify vowels. The Tab. 2 summarizes the detection rate of correct classification of vowels for each dimension.

Columns and rows in Tab. 2 represent each dimension (PC). The diagonal is the value of correct classification of vowels (for just one dimension). Green cells show the largest values of the correct classification.
Tab. 2 shows that the best results are obtained with PC1 and PC2, respectively. The final model is shown in Fig. 2.

Circles represent the centroids and stars around them are the vowel of each child. The Fig. 2 shows that the clusters are separable. It corresponds to the large success of correct classification of vowels in Tab. 2. It is also important to note that vowel positions are similar to vocalic triangle.

The same method (the previous paragraphs) was used also for LPC. Similar graphs and tables show very different results for LPC. PC1 does not contain proper information for vowel classification, but also other PCs do not contain enough information for a high degree of correct classification (Tab. 4).

Tab. 4 does not contain high values of correct vowel detection and the best dimension is PC4. Combination of PC4 and PC5 reaches about 66 % of correct vowel detection. These two dimensions in Fig. 3 do not show good clustering and vocalic triangle is not preserved.

A comparison of the two parameterization shows that MFCC is preferable for the vowel detection by PCA. Without any modifications it achieved more than 90% successful vowel classification and the final model fits vocalic triangle, which is important for diagnostics.
A misclassification between phoneme “a” and “e” is not a serious mistake of classifier, it occurs also in healthy children speech, otherwise a misclassification between “e” and “o” or “i” and “u” is really serious mistake. The results of our previous work shows that these phonemes misclassification are one of the symptoms for DD. Vowel detection method using reduced MFCC proves to be a good method for determining the degree of DD.
Formants
Formants are defined as the spectral peaks of the sound spectrum of the voice. Variations in the basic tone of a person’s voice and in the formants of the voice affect prosodic features. Changes to the speaker’s basic tone of voice are interpreted as a change in speech melody. Changes to the first formant (F1) correspond to changes in the vertical movement of the speaker’s tongue; changes to the second formant (F2) correspond to changes in the horizontal movement of the tongue; while the third formant (F3) changes with actions taking place in the nasal cavity. This means that the first three formants are most important when it comes to vowels (in the order of importance F2, F1 and F3). Higher formants are identical for all vowels and they contain a significant portion of the information about the intonation of the speaker’s voice. We get vocalic triangle as the correlation between F1 and F2 all of vowels (Tab. 5).
![Vocalic triangle [3]](https://pl-master.mdcdn.cz/media/cache/media_object_image_large/media/image/4e8d720fff3563e907ed1555bf2bca28.png)
Vowels detection and control of the accuracy
Sometimes during labelling children’s speech signals that a specific vowel is detecting after listening to an entire word. After the calculation of formants and after the subsequent evaluation of this analysis is it often detected by other vowel. Correction and repair of detection the vowel is done by listening. On the tested sample of speech recordings obtained from healthy children, all of the vowels that were isolated in these recordings were analyzed and subsequently theirs classification by formant analysis. The Tab. 6 shows the parameters for each individual vowel, which were used to classify the vowel.
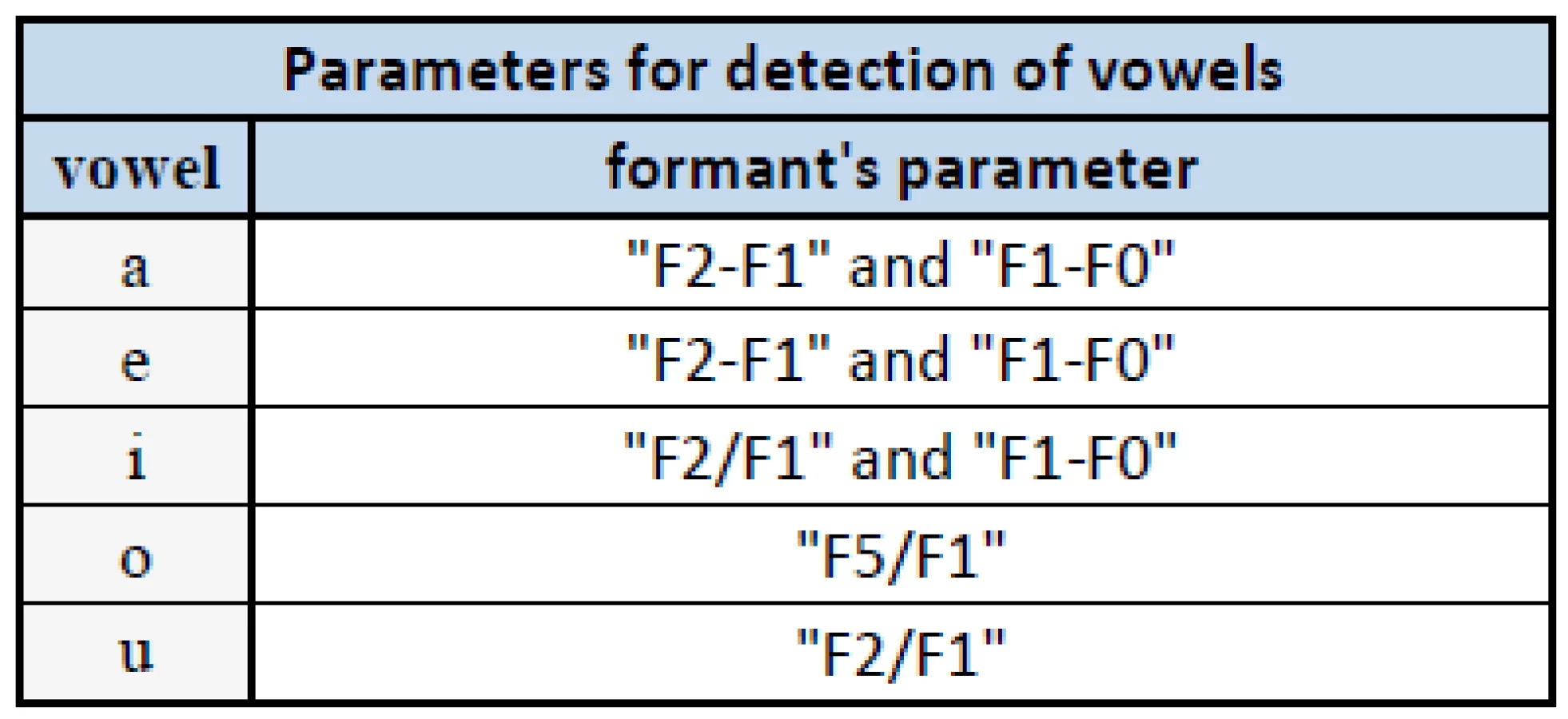
Vocalic triangle can be used to check the accuracy of calculation and classification of formant frequencies. Fig. 4 shows the wrong frequency range.

Conclusion
Our research involves an original method for the intensity of speech defect monitoring in child patients with DD. Phoneme classification is part of them. We were drawing upon a body of knowledge consisting of phonetics, acoustics and ANN applications. The PCA and SSOM were chosen for solving part of the project. The LPC reduced by PCA are not good parameterization for solving our problem with determining the degree of DD. The MFCC present much better results. It was shown, that the main information in MFCC contains useful data for vowel classification and it also corresponds with vocalic triangle. It will be probably less complicated to use directly vowel formants for vowel detection.
The consonants detection using SSOM for children with DD are in the beginning of our studies. The SSOM uncovered many results for vowel detection of children with DD, so we expect that the method will be useful also for consonant detection.
Acknowledgement
The work has been supported by research grant No. SGS SGS12/143/OHK3/2T/13 and by IGA MH CR agency, grant No. NT11443-5/2010.
Sources
[1] Tuckova, J., Komarek, V. Effectiveness of speech analysis by self-organizing maps in children with developmental language disorders. Neuroendocrinology Letters, 2009, 29 (6), 939–948
[2] Dlouha, O., Novak, A., Vokral, J. Central Auditory Processing Disorder (CAPD) in Children with Specific Language Impairment (SLI). In Int. Journal of Pediatric Otorhinolaryngology,2007, 71 (6), 903-907.
[3] Psutka, J., Muller, L., Matousek, J., Radová, V.: Mluvíme s počítačem česky, Academia Praha, 2006, ISBN 80-200-0203-0.
[4] Introduction to Machine Learning, Ethem ALPAYDIN, The MIT Press, October 2004, ISBN 0-262-01211-1.
[5] Kohonen, T. Self-Organizing Maps, Springer–Verlag, 3rd edition, 2001.
[6] Vesanto, J., Himberg,J., Alhoniemi, E., Parhankangas J., 2000. SOM Toolbox for Matlab 5, Helsinki University of Technology, ISBN 951-22-4951-0. www.cis.hut.fi/projects/somtoolbox
[7] Palkova, Z. Fonetika a fonologie češtiny. Univerzita Karlova, Praha 1994, ISBN 80-7066-843-1.
[8] Zetocha, P. Design and realization of children speech database. Ministry of Education grant FRVS, No.2453/2008.
[9] Grill, P., Tuckova,J., FORANA. In: Proc. of the Int. Conf. on Technical Computing Prague 2009. Humusoft, Praha, 2009, pp. 32 - 39. ISBN 978-80-7080-733-0.
[10 ] PRAAT: doing phonetics by computer http://www.fon.hum.uva.nl/praat/.
[11] Tuckova, J., Bártů, M., Zetocha, P. Aplikace umělých neuronových sítí při zpracování signal. Česká technika, 2009, Praha. ISBN 978-80-01-04400-1.
[12] Tuckova, J., Santarius, J. Neural Network Program Package for Prosody Modelling. In: Radioengineering, April 2004, 13 (1),17-21, ISSN: 1210-2512.
Labels
BiomedicineArticle was published in
The Clinician and Technology Journal

2012 Issue 2
Most read in this issue
- MECHANICAL MODEL OF THE CARDIOVASCULAR SYSTEM: DETERMINATION OF CARDIAC OUTPUT BY DYE DILUTION
- MATLAB AND ITS USE FOR PROCESSING OF THERMOGRAMS
- VALUATION METHODOLOGY FOR MEDICAL DEVICES
- VENTILATOR CIRCUIT MODEL FOR OPTIMIZATION OF HIGH-FREQUENCY OSCILLATORY VENTILATION